1.volatile能保证可见性
先说个案例:
- 有两个线程A和B,有一个公共的 boolean flag 标记位,最开始赋值为 true;
- B线程循环,根据这个flag来进行执行或者退出;
- 这时线程A把flag改成false这个时候希望线程B看到变化,而停止执行;
- 但是线程B可能并不能立刻停下来,也有可能过一段时间才会停止,甚至在最极端的情况下可能永远都不会停止。
- 因为最开始它们都可以读取到 flag 为 true ,不过当线程 A 这个值改为 false 之后,线程B 并不能及时看到这次修改,因为线程B 不能直接访问线程A 的本地内存。
可以看一下CPU的内存结构:
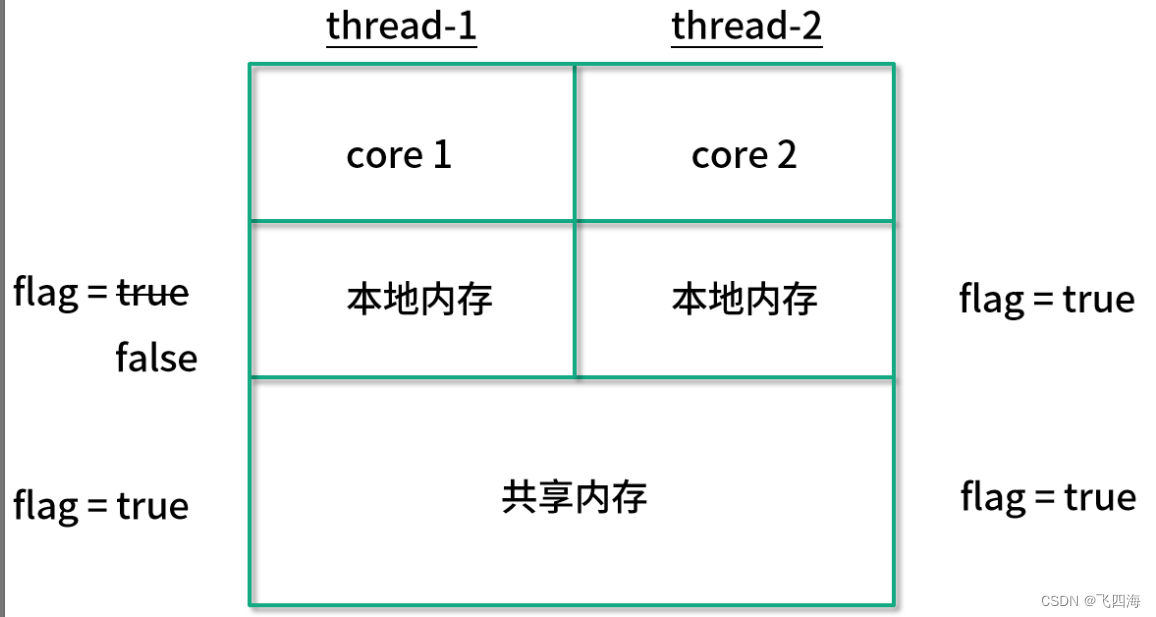
可以看出,线程A和线程B 分别在不同的 CPU 核心上运行,每一个核心都有自己的本地内存,并且在下方也有它们共享的内存。
这样的问题就是一个可见性问题。
volatile 关键字:
要想解决这个问题,我们只需要在变量的前面加上 volatile 关键字修饰,只要我们加上这个关键字,那么每一次变量被修改的时候,其他线程对此都可见,这样一旦线程A改变了这个值,那么线程B 就可以立刻看到,因此就可以退出 while 循环了。
所以volatile关键字可以让它拥有可见性。
原因在于有了这个关键字之后,线程 A 的更改会被 flush 到共享内存中,然后又会被 refresh 到线程B 的本地内存中,这样线程B 就能感受到这个变化了,所以 volatile 这个关键字最主要是用来解决可见性问题的,可以一定程度上保证线程安全。
2.volatile 不能保证原子性
- 比如我们线程A和B 同时进行 value++ ;
- 每个线程都加 1000 次,最终的结果很可能不是 2000;
- 所以在多线程的情况下,会出现线程安全问题(不信可以自己试一下);
- 因为这里的问题不单单是可见性问题,还包含原子性问题。
如果我们想保证原子性也有很多办法比如:
- 使用 synchronized 关键字
- 使用我们的原子类 AtomicInteger ,调用它的 incrementAndGet 方法
- 在利用了原子变量之后就无需加锁,我们可以使用它的 incrementAndGet 方法,这个操作底层由 CPU 指令保证原子性,所以即便是多个线程同时运行,也不会发生线程安全问题。
3.volatile 使用场景
通常情况下,volatile 可以用来修饰 boolean 类型的标记位,因为对于标记位来讲,直接的赋值操作本身就是具备原子性的,再加上 volatile 保证了可见性,那么就是线程安全的了。
也就是说我们有一个可见性问题,那么可以使用 volatile 关键字。
如果我们要保证原子性可以使用 原子类 来保证。可以自己探索下,后面我也会总结的,
OK完活。