[1] ZHU, Hang, et al. Network planning with deep reinforcement learning. In: Proceedings of the 2021 ACM SIGCOMM 2021 Conference. 2021. p. 258-271. Citation: 25
文章目录
- Q1 论文试图解决什么问题?
- Q2 这是否是一个新的问题?
- Q4 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
- 1. 网络优化问题
- 2. 强化学习解决的优化问题
- Q5 论文中提到的解决方案之关键是什么?
- Q6 论文中的实验是如何设计的?
- Q9 这篇论文到底有什么贡献?
Q1 论文试图解决什么问题?
本论文解决网络规划的问题。网络规划涉及IP层和光层的跨层决策,cross-layer scheduling是一个很有挑战性的问题。
Q2 这是否是一个新的问题?
这不是一个新问题,早在1994年的论文Genetic algorithms in optimal multistage distribution network planning提出用遗传算法进行对网络的规划。规划的网络必须满足运营商指定的某些服务期望,其中包括性能要求(例如,为给定的流量矩阵提供足够的带宽)和可靠性要求(例如,对故障的稳健性)。
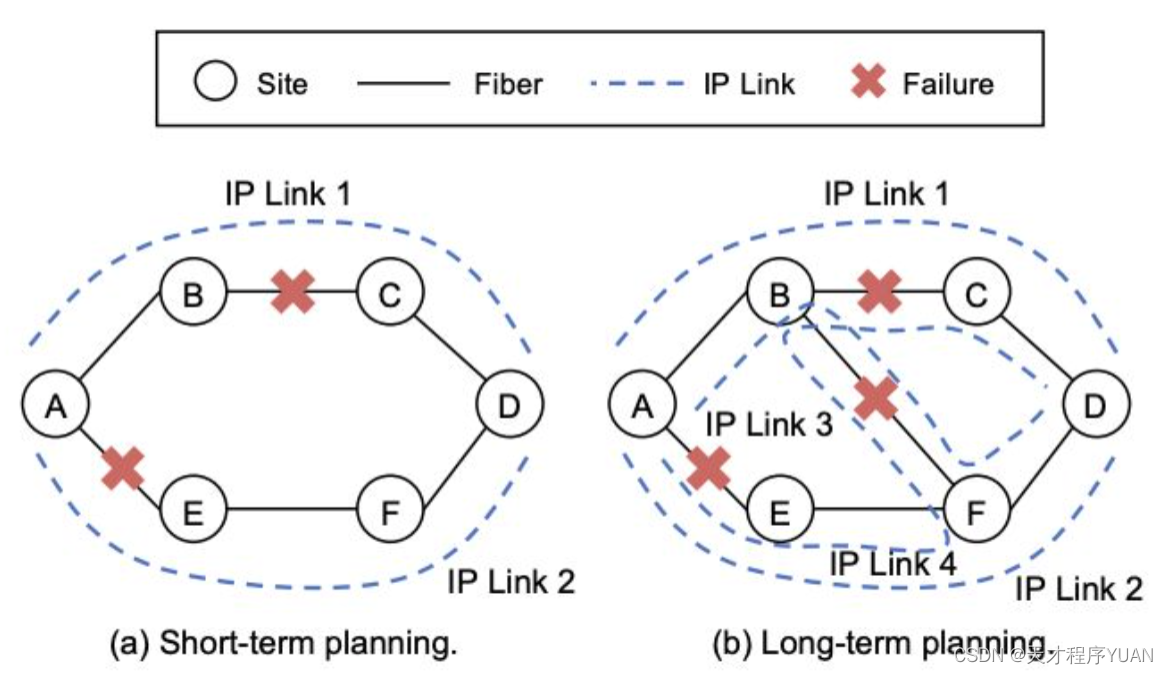
下图描述了网络规划问题:在三种单光纤故障中的任何一种情况下,满足从A到D的100Gbps流量的网络规划实例。(a) 短期规划使用两条IP链路A-B-C-D和A-E-F-D。(b) 长期规划增加一条新的光纤B-F,并使用两条IP链路A-B-C-D和A-B-F-D。
Q4 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
可主要按照以下两类来分:
1. 网络优化问题
[15] O. Gerstel, C. Filsfils, T. Telkamp, M. Gunkel, M. Horneffer, V. Lopez, and A. Mayoral. Multi-layer capacity planning for ip-optical networks. IEEE Communications Magazine, 2014.
[20] R. Hartert, S. Vissicchio, P. Schaus, O. Bonaventure, C. Filsfils, T. Telkamp, and P. Francois. A declarative and expressive approach to control forwarding paths in carrier-grade networks. In ACM SIGCOMM, 2015.
[23] S. Jain, A. Kumar, S. Mandal, J. Ong, L. Poutievski, A. Singh, S. Venkata, J. Wanderer, J. Zhou, M. Zhu, et al. B4: Experie
2. 强化学习解决的优化问题
[4] I. Bello, H. Pham, Q. V. Le, M. Norouzi, and S. Bengio. Neural combinatorial optimization with reinforcement learning. arXiv preprint arXiv:1611.09940, 2016.
[5] Y. Bengio, A. Lodi, and A. Prouvost. Machine learning for combinatorial optimization: a methodological tour d’horizon. European Journal of Operational Research, 2020.
[7] Q. Cappart, T. Moisan, L.-M. Rousseau, I. Prémont-Schwarz, and A. Cire. Combining reinforcement learning and constraint programming for combinatorial optimization. arXiv preprint arXiv:2006.01610, 2020.
[10] X. Chen and Y. Tian. Learning to perform local rewriting for combinatorial optimization. Advances in Neural Information Processing Systems, 2019.
Q5 论文中提到的解决方案之关键是什么?
提出强化学习算法(NeuroPlan)在IP层和光层做出多项决策,从而进行网络规划。
1)使用图神经网络来编码网络拓扑,解决动态网络给DRL带来的挑战
2)结合ILP的方法,来解决最佳性和可操作性的矛盾
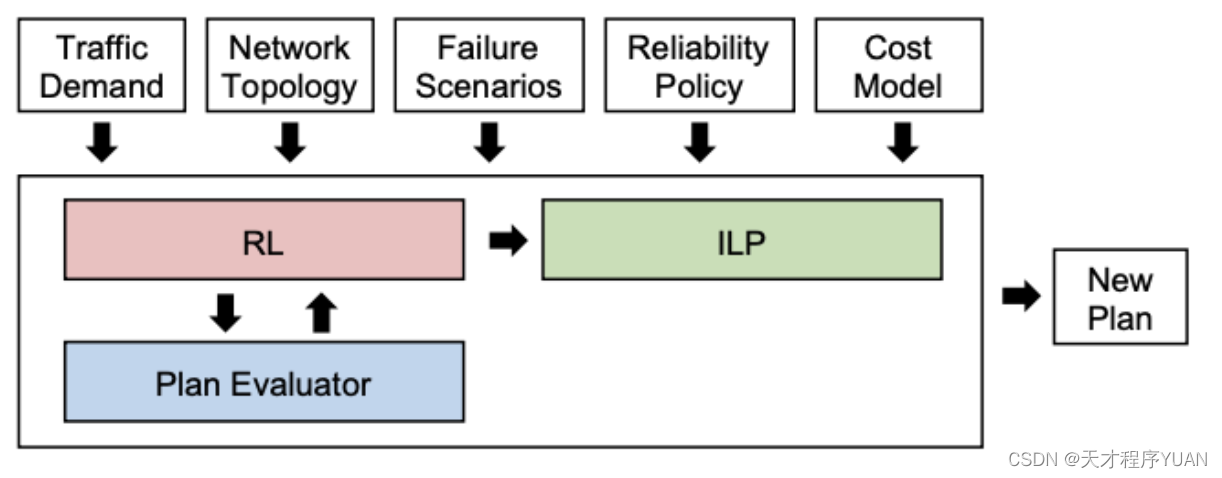
Q6 论文中的实验是如何设计的?
实验选取的baseline包括ILP和ILP-heur。Metrics包括Optimality(运行时间)和Scalability(是否适用于大规模的网络拓扑)。
Q9 这篇论文到底有什么贡献?
相比于传统的启发式解决方案,该论文是首个提出了用强化学习的方法来解决网络规划问题,并针对强化学习难以面对动态网络环境的问题使用GNN解决。但相比于启发式方法,强化学习存在很多问题,比如训练时间和成本长,收敛慢。