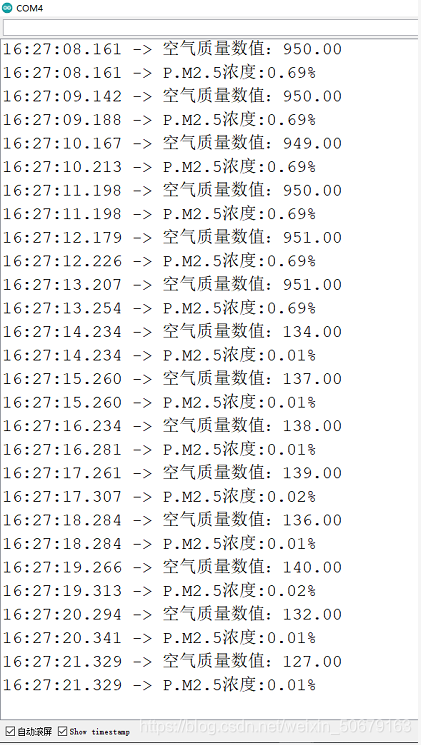
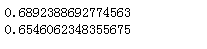我们使用的数据集为 北京空气_2010.1.1-2014.12.31.csv

我们打开看一下,依次是编号,年月日小时,以及各种天气指标

我们可以从上面的数据看到,在pm2.5这一列是有NA这种值的,这种值是没检测的意思,我们后面会处理这种NA值
天气指标的意义如下图所示

我们使用RNN通过未来某一天前5天的露点,温度,大气压,风向,风速,累计雪量,累计雨量,预测未来与PM2.5状态某一天的PM2.5状态
我们的数据最后一次采样的时间是2014-12-31 23:00:00,也就是说,在这种方案下,我们只能预测2015-1-1这一天的数据
- 我不确定露点,温度,大气压,风向,风速,累计雪量,累计雨量这些指标是否真的与PM2.5有关,我们只是通过这个例子来展示RNN的使用
目录
1 导入库
2 读取数据
3 处理数据集
3.1 消除数据中的NA
3.2 多列时间信息合并为一列
3.3 将风向(cbwd)列转换为独热编码
4 分割数据
5 定义训练数据与测试数据
6 搭建网络
7 编译模型
8 训练模型
9 保存模型
10 预测模型
1 导入库
2 读取数据
![]()
3 处理数据集
3.1 消除数据中的NA
我们先看一下在数据中一共有多少个NA数据
![]()
发现只有pm2.5这一列有NA数据,其余列都没有

对于NA数据,我们采用前向填充的方法,比如说如果今天的NA,那么我们使用昨天的数据来代替今天的数据,这样我们只要保证第一行不是NA,我们就可以填充上所有的数据,为此,我们删掉数据的前24行,因为前24行都是NA数据
![]()
之后我们可以看一下填充后在数据中还有没有NA值
![]()
发现已经没有了

3.2 多列时间信息合并为一列
时间列一共有四列,我们将其合并为一列
首先导入datetime库,然后使用其中的datetime方法,之后应用于data,将内容变为新的一列

我们看一下现在的数据是什么样的
![]()

然后我们删掉No,year,month,day,hour这五列
![]()

之后我们使用time这一列作为索引
![]()
现在我们看一下当前的data
![]()

3.3 将风向(cbwd)列转换为独热编码
我们先看一下cbwd这一列有哪些值
![]()
发现有SE,cv,NW,NE四种值
![]()
我们加入独热编码列
![]()
现在的数据是这个样子的,后面加了四列

之后我们删除cbwd列
![]()
4 分割数据
我们是通过x天前5天的数据,预测x天的数据,那么我们的数据就得这样分割

- 这样分割会使大部分数据是重复的,这样会极大消耗内存,这个问题我们放到后面的章节来搞,这一节我们就这样分割
每一个小时是一行,5天就是5*24行,1天就是24行
![]()
之后我们按照上面表格的分割方法,把每一块数据放入一个列表中

之后我们将其变为array形式
![]()
之后我们对其进行乱序
![]()
5 定义训练数据与测试数据
x是要放入的数据,y是期望的结果
![]()
-1代表最后24小时,0代表PM2.5,因为PM2.5是第0列

之后定义80%为训练数据,20%为测试数据

我们下面要对train数据进行标注话,在此之前,我们先看一下train数据的shape
![]()
![]()
其中120是seq_length的值(5*24=120),11是pm2.5,DEWP,TEMP,PRES,cbwd,Iws,Is,IR,NE,NW,SE,cv,0-11共12列,34924是一共34924块,有多少行的个数是相等的,我们下面就要对每一个块中的数值做标准化
做标准化需要均值和方差,我们先求出均值与方差
![]()
由于我们测试时不能直接使用test数据的均值与方差,所以我们这里使用训练数据的均值与方差进行替代
![]()
- 执行标准化的原因是我们需要将训练数据(标签不用变)都统一到一个范围内,这样我们训练的结果会更好
6 搭建网络
LSTM层有一个参数是return_sequences这个默认是为False的,如果我们在该层的下一层不再使用LSTM那么就让其保持默认的False就可以了,如果要继续使用LSTM层,那么需要将return_sequences置为True

7 编译模型
![]()
这里面的mae叫平均绝对误差,比如我的预测结果是50,我的实际值的75,那么我的mae就是25,如果预测结果是20,我的mae就是55
8 训练模型

首先定义batch,之后定义在训练过程中学习速率下降的回调函数,使用的方法为ReduceLROnPlateau,检测的对象是val_loss,如果连续三个epoch的val_loss不下降,那么将学习速率降为原来的0.5倍,学习速率最小降到0.000001
虽然我们每一个epoch都很快,但是需要训练很多个epoch,所以我们在这里加上tensorboard和checkpoint

9 保存模型
![]()

我们看一下tensorboard,看一下训练效果如何,我们直接看mae,发现能达到15左右,只能说还可以,但是并不是很好

10 预测模型
我们就预测test数据中的一块数据,我们呢和以前一样,处理test数据

然后我们读取刚刚训练好的模型,预测test中的第0块内容,然后再显示出来实际内容,我们看一下

我们就看前三个和后三个,发现基本都在mae的范围内