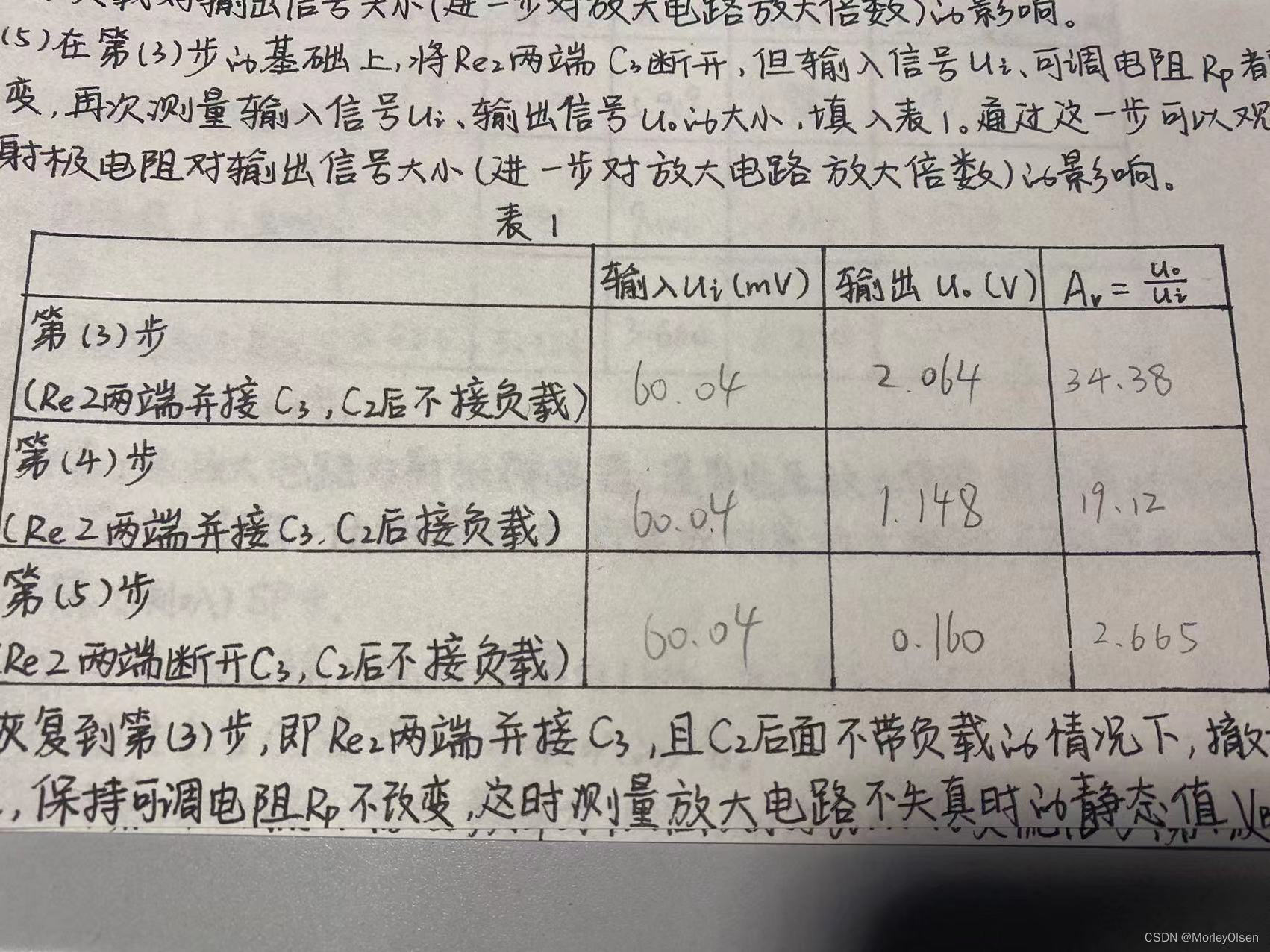
4.2.8.修改表
4.2.8.1.表重命名
基本语法:
alter table old_table_name rename to new_table_name;
– 把表score3修改成score4
alter table score3 rename to score4;
4.2.8.2.增加/修改列信息
– 1:查询表结构
desc score4;
– 2:添加列
alter table score4 add columns (mycolx string, myscoy string);
– 3:查询表结构
desc score4;
– 4:更新列
alter table score4 change column myscox mysconew int;
– 5:查询表结构
desc score4;
4.2.8.3.删除表
drop table score4;
4.2.8.4.清空表数据
只能清空管理表,也就是内部表
truncate table score4;
4.2.9.hive表中加载数据
4.2.9.1.直接向分区表中插入数据
通过insert into方式加载数据
create table score3 like score;
insert into table score3 partition(month =‘202007’) values (‘001’,‘002’,100);
通过查询方式加载数据
create table score4 like score;
insert overwrite table score4 partition(month = ‘202006’) select sid,cid,sscore from score;
4.2.9.2.通过查询插入数据
通过load方式加载数据
create table score5 like score;
load data local inpath ‘/export/data/hivedatas/score.txt’ overwrite into table score5 partition(month=‘202006’);
4.2.9.2.1.多插入模式
常用于实际生产环境当中,将一张表拆开成两部分或者多部分
给score表加载数据
load data local inpath ‘/export/data/hivedatas/score.txt’ overwrite into table score partition(month=‘202006’);
创建第一部分表:
create table score_first( sid string,cid string) partitioned by (month string) row format delimited fields terminated by ‘\t’ ;
创建第二部分表:
create table score_second(cid string,sscore int) partitioned by (month string) row format delimited fields terminated by ‘\t’;
分别给第一部分与第二部分表加载数据
from score insert overwrite table score_first partition(month=‘202006’) select sid,cid insert overwrite table score_second partition(month = ‘202006’) select cid,sscore;
4.2.9.2.2.查询语句中创建表并加载数据(as select)
将查询的结果保存到一张表当中去
create table score5 as select * from score;
4.2.9.2.3.创建表时通过location指定加载数据路径
1)创建表,并指定在hdfs上的位置
create external table score6 (sid string,cid string,sscore int) row format delimited fields terminated by ‘\t’ location ‘/myscore6’;
2)上传数据到hdfs上
hadoop fs -mkdir -p /myscore6
hadoop fs -put score.txt/myscore6;
3)查询数据
select * from score6;