软件环境:win7,mysql版本5.5,InnoDB存储引擎。
硬件环境:普通笔记本,CPU P8700双核2.53GHz,内存3G,5400转机械硬盘1000GB。
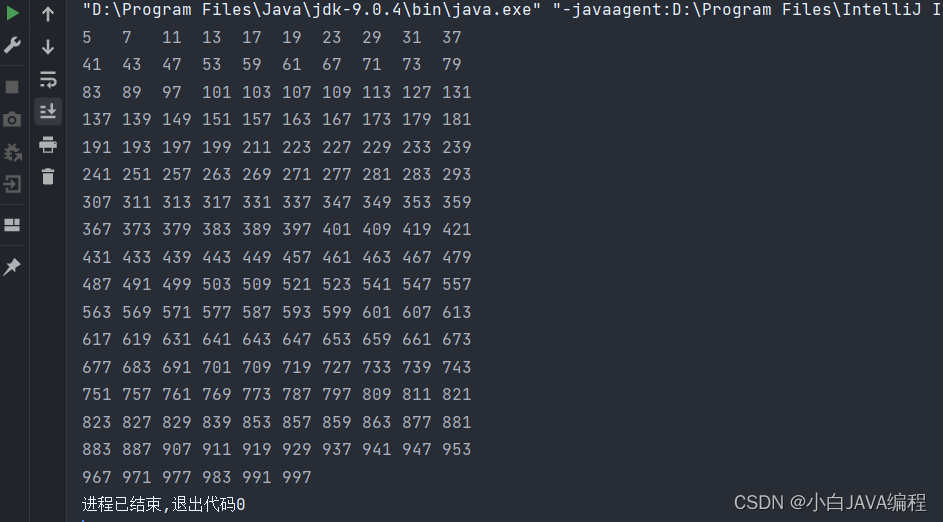
建了一张表,id列是自增长bigint,再加上其他varchar、datetime型的字段,总共8个字段,通过java生成了insert的sql文件,一共62个文件,每个文件50万行(约88M),总共3100万行记录(约5.35G),通过source导入,从中午1:30一直到18:00才导完,花了快4个半小时,导完后,数据文件大小约2.5G。后来听说用load data infile可以加快导数据时间,改天再试试。
结论1:由此可见,mysql单表支持1000万条数据是完全可行的。
此时只有id列上有主键,聚集索引,测试开始。
1、整表数据行数统计(select count)
select count(*) from t_test;
返回3100万条数据足足花了1分21秒,多次测试取平均值,也差不多要1分6秒。
select count(n_id) from t_test;
返回3100万条数据也要1分多,感觉比count(*)性能好不了多少,难道是数据量级还不够大?
给n_id建了一个非聚集索引,create index idx_nid on t_test(n_id) 耗时4分43秒。
再次 select count(n_id) from t_test;
返回3100万条数据耗时13.52秒;