本文是在计算机图形学期末考察的背景下,通过一周的调查并按个人理解整理得出的。虽说文章也是总结的精华,但个人以为还颇有粗糙之处(如有错误欢迎指正)。在此,笔者把参考资源放于文章之前——相比于本文,参考资料在学术上更准确,内容深刻,表达得体;另一方面也是希望大家优先从参考资料下手,从中得出自己的思考,再来笑看这篇多方借鉴的总结。
Reference
- 如果想要入门或者快速了解一下可以先看B站的科普视频,可以大致了解DLSS是什么,为什么,怎么做。看完视频方便你进一步提出问题,查找资料。
- B站:DLSS到底是什么技术?为何能提升游戏性能?有代价吗?,
- B站:【硬件科普】免费提升画质和帧数?详解DLSS2.0的工作原理与作用
- NVIDIA官网介绍:NVIDIA:DLSS 2.0
此外,NVIDA还在GTC上给出了相应的Talk,其中介绍了DLSS 2.0、针对于游戏的图像超分辨率的挑战以及DLSS 2.0引擎集成:NVIDA’s Talk:GTC 2020: DLSS 2.0 - Image Reconstruction for Real-time Rendering with Deep Learning(这是油管上面的,英语听力ok的可以直接冲,英语不太行的可以开中文字母。好像b站也上线了,但还没点进去过,不知道有没有翻译)本文有关于DLSS 2.0的介绍大抵上也出自这个Talk. - 同时,DLSS团队成员文刀秋二也是这个Talk的汇报人在知乎上也对Talk进行了总结,详见:DLSS 2.0 - 基于深度学习的实时渲染图像重建
- Beyond3D: Diving into Anti-Aliasing个人觉得是很全面很有逻辑的抗锯齿的介绍。有需要的朋友可以自取!
- 书籍:Real time rendering 在实时渲染和计算机图形学领域,《Real-Time Rendering》这本书一直备受推崇。有人说,它实时渲染的圣经。也有人说,它是绝世武功的目录。这次调查主要阅读了本书关于抗锯齿方面的介绍。如有机会可以进军相关领域,还是很期待可以把这本书读一下的。当然毛星云也在CSDN上发布了这本书第三版提炼总结的专栏:【《Real-Time Rendering 3rd》提炼总结】,两者可以配合食用。
- 一篇2021年7月的期刊:An overview of current deep learned rendering technologies 着重讨论实时渲染和深度学习渲染。其中介绍了实时渲染技术中的抗锯齿和超分辨率,深度学习渲染技术中的DLSS和NSS模型,并且介绍了DLSR技术面临的挑战。本文的思路也从这篇期刊而来。
实时渲染技术和DLSS 2.0技术
- Reference
- 一、前言
- 二、实时渲染图像重建技术基础
- (一)抗锯齿技术
- 1. 基于采样的抗锯齿技术
- 样本数量
- 样本位置
- 采样类型
- 样本融合方式
- 2. 后处理抗锯齿技术
- 3. 混合抗锯齿算法
- (二)超分辨率技术
- 1. 单帧超分辨率
- 2. 多帧超分辨率
- 3. 时域超采样
- DLSS 2.0技术介绍
- DLSS 2.0原理与思路
- DLSS 2.0引擎集成
- DLSS 2.0渲染加速
- 三、DLSR挑战与总结
- (一)DLSS效果对比
- (二)DLSS 2.0的优缺点
- 1. DLSS 2.0 四大特性
- 2. DLSS缺点
- (三)DLSR技术的展望
- Postscript:总结
一、前言
通俗讲,渲染(Render)是处理器将需要计算的画面信息,计算并“绘制”在显示屏幕上的过程。随着显示技术的进步,渲染技术也慢慢地出现了两条主流分支:一种用于视频游戏技术,另一种则是用于影视技术。这两类需求对应的渲染技术分别为:实时渲染与离线渲染。
实时渲染(Real-time rendering)指的是在计算机上快速生成图像。它是计算机图形学中最具交互性的领域。首先一幅图像显示在屏幕上,然后观察者做出动作与反应,并且其动作反馈会影响接下来的生成内容。由于这种反馈、渲染的循环速度足够快,观察者就不会只看到独立的图像,而是会沉浸在这种动态过程中。
由于追求高分辨率和高帧率的真实性体验,RTR技术难度呈指数型上升。显示设备的更新换代以及物理着色、光线追踪、精确物理引擎、更高质量的纹理模型的实现使最新一代 GPU 也难以在不影响帧率的情况下以原始分辨率渲染图像。此时,低分辨率的性能开销实现高分辨率的画面成为大势所趋。

借助于深度学习超采样(DLSS),NVIDIA推出DLSS 2.0。其实现了通过渲染更少的像素,使用 AI 构建清晰、分辨率更高的图像。 DLSS2.0由GeForce RTX GPU上的专用 AI 处理器Tensor Cores 提供支持,是一种经过改进的全新深度学习神经网络,可在生成精美、清晰的游戏图像的同时提高帧速。它为游戏玩家提供了最大化光线追踪设置和提高输出分辨率的性能空间。

本文旨在介绍实时渲染图像重建技术部分基础,同时着重于讨论新兴的基于深度学习的实时渲染重建DLSS 2.0。文章结构如下:第二部分讨论了实时渲染重建技术基础,包括抗锯齿和超分辨率采样两个方向;第三部分着重讨论DLSS 2.0技术的理论、工作原理和实现效果;第四部分分析DLSS 2.0的优点和缺点,并讨论了DLSR技术面临的挑战和展望。
二、实时渲染图像重建技术基础
(一)抗锯齿技术
Aliasing (锯齿)这个术语最早出现在信号处理这门学科中,指的是当一个连续信号被采样后和其他非一致信号混淆的现象。在3D渲染中,这个术语有着更特殊的意思——它涵盖了所有3D渲染光栅化后产生的画面瑕疵。3D场景渲染在光栅化之前是连续信号,但在进行像素渲染(对每个像素生成相应的色彩值)的时候就不得不对连续信号进行采样以获得能够输出到显示器的结果。反锯齿的目标就在于让最终输出的画面和原生场景尽可能接近,修复渲染瑕疵。
所有的渲染失真都可以归因于采样问题(用有限的像素展示无限的细节),使用哪种反锯齿手段与锯齿成因息息相关。因此,为了探讨不同反锯齿手段的优势和劣势,我们先将3D渲染的瑕疵根据其成因简单归纳为6个类别:几何失真、透明失真、子像素失真、纹理失真、渲染失真、闪烁情形(时间性锯齿)。

现如今的抗锯齿技术可以分为两类:一类是通过提高采样质量来减少渲染时锯齿,另一类则是通过对已渲染好的图片分析和后处理来减少锯齿。
1. 基于采样的抗锯齿技术
首先讨论基于采样的反锯齿技术,其实质则是通过渲染比屏幕分辨率更高的画面而后再降采样至屏幕空间分辨率。样本数量,样本位置、采样模式和样本融合方式都会影响最终的画面质量。
样本数量
显而易见,倘若生成一个像素的采样点趋近于无穷多,那么最终的效果就会无限趋近“完美”的光栅化效果。因此,抗锯齿的效果和样本数量密切相关。当然样本数量也关系到设备性能:通常在游戏中每个像素会使用2个或4个采样点,而在高端显示器中可能会使用到8个及以上的采样点。
样本位置
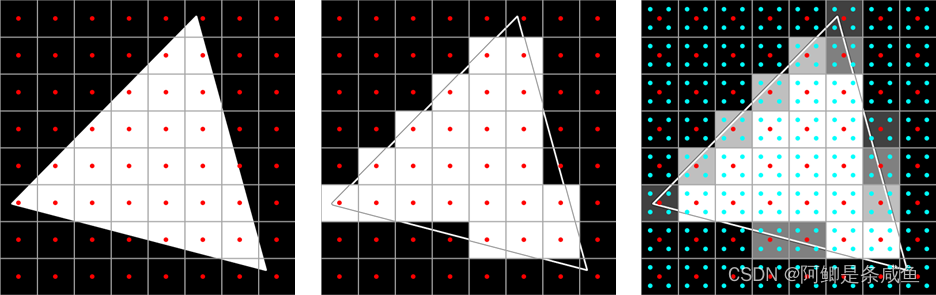
样本位置的选取对最终画面质量有着至关重要的影响。特别是在游戏渲染中,由于采样点数量少,样本位置就更为重要。由于样本位置呈有序点排列,这种抗锯齿也被称作顺序栅格超级采样(Ordered Grid Super-Sampling,OGSS)。然而,对于接近垂直或接近水平的线而言,使用排列有序的采样网格效果往往不佳。此时,采用旋转栅格超级采样(Rotated Grid Super-Sampling,RGSS)可以获得更好的结果。

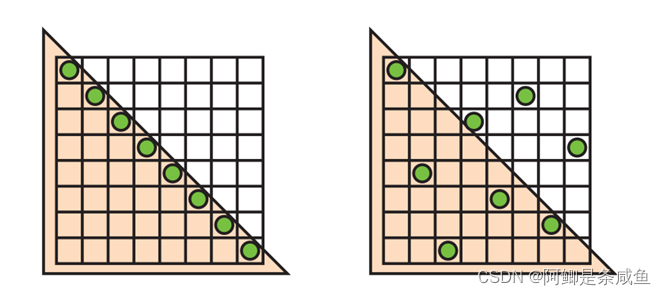
为了缓解这个问题,我们也可以将采样点稀疏摆放在不同的列。对于抗锯齿来说,理想的摆放应当是稀疏的。换句话说,对于N个采样点,任意两个采样点不会在一个N\times N网格的同一列、行以及对角线上。通过对N皇后问题求解可得到满足这种条件的采样点摆放方式,在此不再赘述。这种稀疏摆放采样点的抗锯齿也被称作稀疏栅格抗锯齿(Sparse Grid Anti-aliasing,SGAA)。
采样类型
- 超采样抗锯齿(Super-sampling Anti-aliasing,SSAA)
基于采样的抗锯齿方法对每个采样点都进行了运算。虽然这样的采样方式可以消除各类渲染失真,但也非常耗费资源。举个例子,N倍采样将会给像素渲染、光栅单元、内存带宽以及内存容量施加N倍的计算压力。这种对每个采样点都进行独立计算的采样也被称为超采样抗锯齿。

- 多重采样抗锯齿(multi-sample anti-aliasing,MSAA)
在进入21世纪后,多重采样抗锯齿开始作为SSAA的一种优化解被广泛应用。MSAA实质是只对 Z 缓存(Z-Buffer)和模板缓存 (Stencil Buffer)中的数据进行超级采样抗锯齿的处理。可以理解为只对边缘进行抗锯齿处理。当硬件支持Z缓存和模板缓存时(而现今大部分GPU都已经支持这些特性),MSAA带来的内存带宽开销会进一步缩小。相比SSAA对画面中所有数据进行处理,MSAA大大减弱对资源的消耗。但由于MSAA仅针对几何体边缘进行抗锯齿,其他类别的失真(透明失真、纹理失真和渲染失真等)都无法被消除。
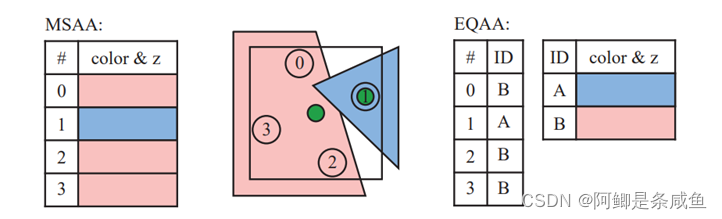

- 覆盖采样抗锯齿(coverage sampling anti-aliasing,CSAA)
第三种采样类型则是NVIDIA在2006年引入的覆盖采样抗锯齿。CSAA在MSAA的基础上还增加了覆盖采样(Coverage Sample)。简单说 CSAA 就是将边缘多边形里需要取样的子像素坐标覆盖掉,把原像素坐标强制安置在硬件和驱动程序预先算好的坐标中。这就好比取样标准统一的MSAA,能够最高效率的执行边缘取样,效能提升非常的显著。比方说16xCSAA取样性能下降幅度仅比4xMSAA略高一点,处理效果却几乎和 8xMSAA一样。8xCSAA有着4xMSAA的处理效果,性能消耗却和2xMSAA相同。

样本融合方式
影响采样抗锯齿质量的最后一个要素就是采样融合模式,即如何将采样点加权计算出一个像素值。
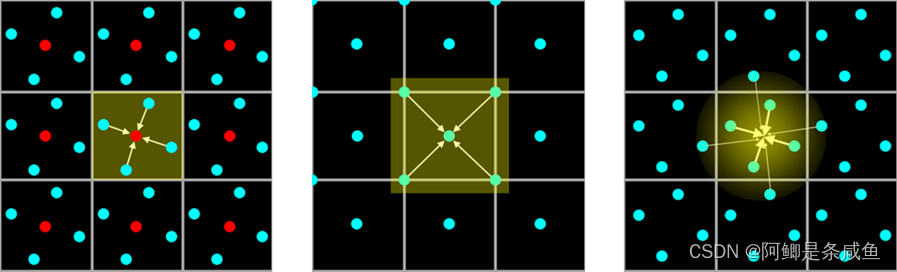
一种改进的融合方法被称作高分辨率抗锯齿方法(High Resolution Anti-Aliasing,HRAA),也称 Quincunx 方法,出自 NVIDIA 公司。Quincunx指的是5个物体的排列方式:其中 4 个在正方形角上,第五个在正方形中心,也就是梅花形,很像六边模型上的五点图案模式。这使得采样点个数不多的情况下的抗锯齿效果明显增强,但由于一个像素点过多地混合了周边的采样点信息而使图像边缘变得模糊,带来了画面锐度降低的问题。
一种更灵活的方法则出现于2007年AMD的HD2900系列显卡中,其称为Tent Filter。HD2900系列提供了可编程的混合能力,也称为可编程过滤抗锯齿(Custom Filter Anti-Aliasing,CFAA),并借这种工具实现了Narrow Tent和Wide Tent两种模式。如图9所示,这两种新型采样模式在混合采样点时并没有使用相同权重,而是根据采样点离像素中心的距离决定相应的混合权重。Narrow和Wide两种混合模式的区别仅在于其使用的过滤核心(Filter Kernel)的大小上。这种混合模式可以根据需要使用不同样本数量。相较于Quincunx方法,这种抗锯齿模式可以说是平衡了画面锐度和抗锯齿力度。

2. 后处理抗锯齿技术
虽然基于采样的抗锯齿算法不仅原理简单,在采样点足够的情况下也有很优秀的效果,但在性能方面仍然会带来巨大的开销。此外基于采样的抗锯齿在近期流行的渲染模式中(例如延迟渲染)基于各种原因更难被实现。由此诞生了另一种非基于采样的抗锯齿方法——后处理抗锯齿。这个方法渲染出未使用抗锯齿的原生画面(无任何采样和缩放),随后尝试通过对成品画面的分析来减少锯齿和失真。
总体而言,所有的后处理抗锯齿都包含了以下三个步骤,而不同的后处理抗锯齿主要区别就在这三个步骤的具体实现方法上。
- 检测图像中不连续的部分,即检测边缘信息
- 通过这些不连续部分的信息重建原始边缘信息
- 对估测边缘上的像素进行重着色
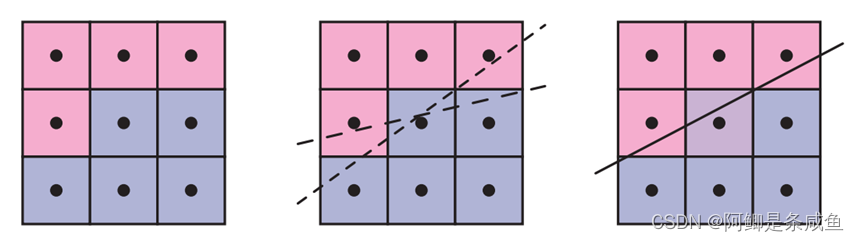
形态抗锯齿(Morphological Anti-Aliasing,简称 MLAA),是 AMD 推出的完全基于 CPU 处理的抗锯齿解决方案。例如图10展示了MLAA对边缘的识别和重建方式。左侧是走样图像。我们的目的是确定边缘的可能方向。中间图展示了算法通过检查相邻像素来记录其为边缘的可能性,图中显示了两个可能的边缘位置。右侧图则展示使用了最佳的推测边缘后,将相邻的颜色与估计的覆盖率成比例地混合到中心像素中。
3. 混合抗锯齿算法
了解了两大类抗锯齿技术方向后,我们会去思考现有流行的抗锯齿技术是如何弥补传统算法的遗憾。
一种可行的解决方案是将基于采样的抗锯齿算法和后期处理抗锯齿技术结合起来。这种新的混合抗锯齿算法在对画面进行多次采样的同时,会结合后期处理抗锯齿算法以输出最终画面。这样做的好处是显而易见的:新算法既避免了纯后期处理抗锯齿的种种缺点(比如说不能处理子像素失真和造成边缘闪烁的问题),在同样的性能损失下,对于几何失真的处理结果又比纯粹基于采样的抗锯齿算法好得多。
- 快速近似抗锯齿(Fast Approximate Anti-Aliasing,FXAA)
快速近似抗锯齿是传统 MSAA效果的一种高性能近似。它是一种单程像素着色器,和 MLAA一样运行于目标游戏渲染管线的后期处理阶段,但不像后者那样使用 DirectCompute,而只是单纯的后期处理着色器,不依赖于任何GPU计算 API。正因为如此,FXAA技术对显卡没有特殊要求,完全兼容 NVIDIA、AMD 的不同显卡(MLAA仅支持AMD)和 DirectX 9.0、DirectX 10、DirectX 11。 - 时间性抗锯齿(Temporal Anti-Aliasing,TXAA)
时间性抗锯齿将MSAA、时间滤波以及后期处理相结合,用于呈现更高的视觉保真度。与CG电影中所采用的技术类似,TXAA集MSAA的强大功能与复杂的解析滤镜于一身,可呈现出更加平滑的图像效果。此外,TXAA还能够对帧之间的整个场景进行抖动采样,以减少闪烁情形(时间性锯齿)。目前,TXAA有两种模式:TXAA 2X和 TXAA 4X。TXAA 2X可提供堪比8X MSAA的视觉保真度,然而所需性能却与 2X MSAA相类似;TXAA4X的图像保真度胜过8XMSAA,所需性能仅仅与4X MSAA相当。 - 多帧采样抗锯齿(Multi-Frame Sampled Anti-Aliasing,MFAA)
多帧采样抗锯齿(Multi-Frame Sampled Anti-Aliasing,MFAA)是NVIDIA公司根据MSAA 改进出的一种抗锯齿技术。目前仅搭载Maxwell架构GPU的显卡才能使用。可以将MFAA理解为MSAA的优化版,能够在得到几乎相同效果的同时提升性能上的表现。MFAA与MSAA最大的差别就在于在同样开启4倍效果的时候MSAA是真正的针对每个边缘像素周围的 4 个像素进行采样,MFAA则是仅仅只是采用交错的方式采样边缘某个像素周围的两个像素。
另一种可行的方案还未被广泛应用:在渲染时记录额外的几何信息,以供后处理抗锯齿使用。目前的实现有GPAA (Geometric Post-process Anti-Aliasing) 以及GBAA(Geometry Buffer Anti-Aliasing)等。
(二)超分辨率技术
图像分辨率体现了系统实际所能反映物体细节信息的能力。相较于低分辨率图像,高分辨率图像通常包含更大的像素密度、更丰富的纹理细节及更高的可信赖度。由此,从软件和算法的角度着手,实现图像超分辨率重建的技术成为了图像处理和计算机视觉等多个领域的热点研究课题。
图像的超分辨率重建技术指的是将给定的低分辨率图像通过特定的算法恢复成相应的高分辨率图像。超分辨率方法通常分为单帧超分辨率(Single Image Superresolution,SISR)和多帧超分辨率(Multi-image Superresolution,MISR)、时域超采样(Temporal Super Sampling)。
1. 单帧超分辨率
单帧超分辨率是和DLSS非常相关的一个研究方向。尤其是跟着这两年深度学习的应用的热度,这个问题的state of the art也提高了很多,这个方向的研究也经常上国内公众号的头条,例如SRCNN,SRGAN,ESRGAN等等。
可是单帧超分辨率其实是个非常困难的问题,因为本质上需要生成低分辨率图像中完全不存在的信息。用神经网络解决这一类问题,本质上就是在训练集中学习到各种低分辨率的像素和高分辨率像素的一个对应关系。有了这个映射后,神经网络能做到比一般的基于插值(interpolation)的方法更好的效果。

但尽管如此,这样生成出来的信息其实是完全基于训练集图片中的数据分布,而并不是对我们实际正在渲染的场景的采样。所以单帧超分辨率的结果经常会和原生分辨率渲染在风格和样式上不一致。对于DLSS来说,我们的目标是重建出和高分辨率渲染一模一样的结果,所以单帧超分辨率一类的工作对实时渲染来说很难适用。
2. 多帧超分辨率
另一类超采样的工作则是针对视频,或者手机摄影的多帧超分辨率。多帧超分辨率并不像单帧超分辨率那么的困难,因为我们不完全需要填补原本不存在的信息。有多个低分辨率图片的情况下,这个问题会可控很多,多帧合成的高分辨率图片往往在光学细节上的还原的质量上会比单帧超分辨率的高许多。
然而针对视频或者摄影的算法也并不太能直接搬过来用于实时渲染,原因有许多。① 在渲染中,我们可以用到的数据是比视频多很多的,我们可以计算每个像素精确的运动向量,我们也可以有场景函数的精确采样,有HDR颜色,甚至像素的精确深度。不利用这些信息,设计出来的算法在效率和质量上都不会是最优的。② 许多视频超分辨率的工作是需要用时序上未来的图片来重建当前帧的图片的,因为实时渲染对延迟的要求,这也显然不适用。

3. 时域超采样
利用把渲染的样本分布在多个帧上,并且用这些多帧复合的样本重建出最终渲染的图片,这在实时渲染领域太司空见惯了。几乎所有引擎都在用的Temporal Antialiasing(TAA),或者游戏主机上非常流行的Checkerboard Rendering都是这么一个思路。
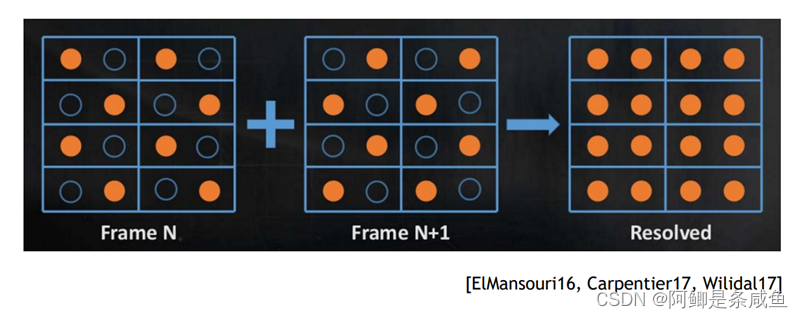
这一类算法利用了渲染图片的时域连贯性(Temporal coherency),既渲染结果的帧与帧之间大体是连续的,发生高频变化的概率不高。也就是说,我们可以假设需要渲染的场景在上一帧和当前帧几乎一样。如果这个假设成立的话,我们大可以之间复用过去帧上对场景采样的样本来重建当前帧。
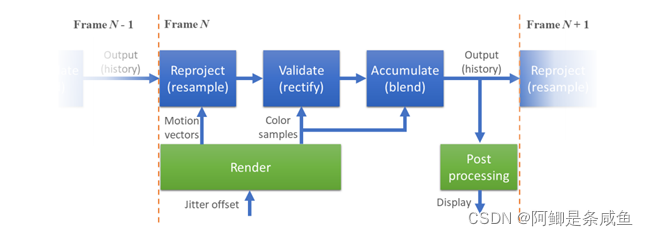
这样做的好处是,每一帧的采样率非常低,所以渲染性能会有很大的提升,然而重建图像时的样本还都确实是对于场景函数的无偏采样,所以最终重建的图像质量也会和原生分辨率渲染非常一致。
然而天下哪有这等好事,实时渲染或者游戏的图片序列中几乎每一帧都有或多或少的变化,从角色动画,到动态光影,到粒子特效。直接复用过去帧的样本来重建当前帧的图片会使重建的结果中产生很大的错误。这种错误在渲染图片中会以延迟,或者鬼影(ghosting)的形式呈现出来。这也是为什么,所有实时渲染中的时域超采样算法,例如TAA,都有非常重要的一步去“纠正”过去帧中样本的错误。

这一类算法需要首先检测过去帧和当前帧因为场景的变化导致的样本错误,然后在不影响画质太多的情况下,“合理”的纠正那些错误的样本。乍一看这简直是个计算机视觉问题,然而在实时渲染中这一步需要非常高效的完成。所以过去十几年,游戏开发者绞尽脑汁的发明了各种“启发式”的方法(Heuristics)。
目前解决这个问题效果最好,也最常用的Heuristic,叫做Neighborhood Clamping。是Epic的Brian Karis在14年的SIGGRAPH的一个实时渲染讲座里最先提到的。思路其实很简单,就是把过去帧采样的样本的值的范围,限制在当前帧像素周围3x3大小的Local neighborhood的所有样本的值的范围内。
DLSS 2.0技术介绍
DLSS 2.0原理与思路
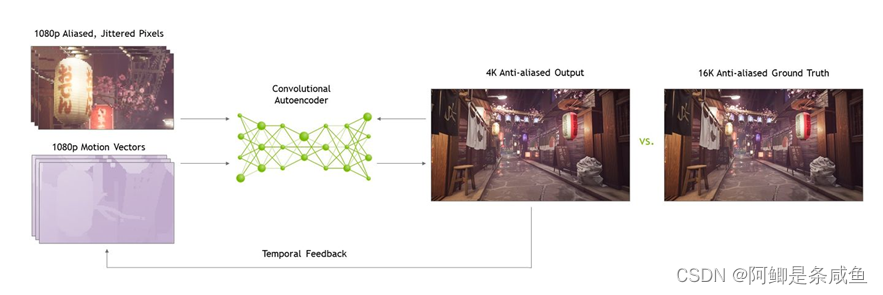
DLSS 2.0首先也是一个基于多帧的图像重建技术。因为我们的目标是重建出和原生渲染一致的画面,所以基于用单帧的算法去“想象”不存在的信息是不适用的。
那DLSS 2.0和现有的实时渲染中的时域超采样有什么区别呢?DLSS2.0抛弃了人肉手调的启发式算法,用一个在超级计算机上数万张超高质量图片训练的神经网络来代替这些Heuristics。就像深度学习在几年前在计算机视觉领域超越了各种手调的特征提取算法一样,深度学习第一次在实时渲染中也非常合理的跑赢了图形领域的手调算法。
用DLSS 2.0重建的渲染图像序列达到了非常高的多帧样本利用率,这也是为什么只用四分之一的样本就可以重建出媲美原生分辨率渲染的图像质量的原因。

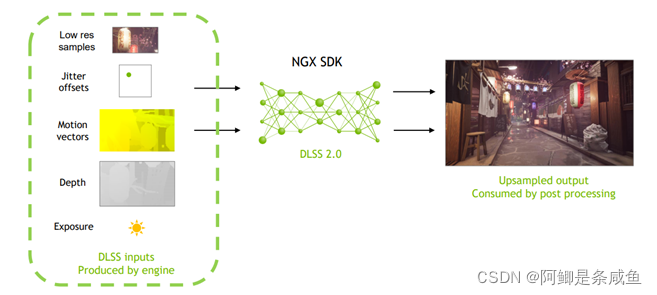
下图是DLSS 2.0的粗略架构:
DLSS 2.0引擎集成
相信现在大家已经知道,DLSS 2.0并不是一个单纯的图像超分辨率算法。它是一个专门针对实时渲染应用的算法。所以引擎要集成DLSS 2.0,需要配合的作出相应的改动。但所幸改动的幅度远比类似Checkerboard rendering简单。

首先当然是引擎要把所有的像素着色工作在低分辨率执行,通常这些包括GBuffer渲染,动态光影,屏幕特效,光线追踪等。
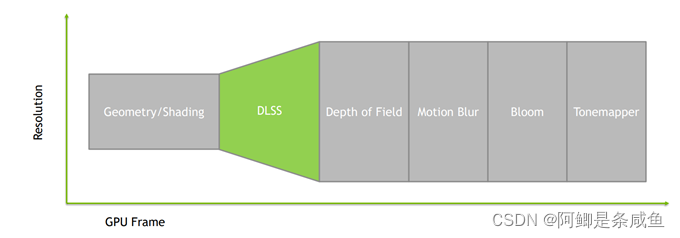
其次,DLSS 2.0是一个融合了抗锯齿和超采样的算法。引擎现有的抗锯齿解决方案例如TAA需要被移除,然后DLSS需要被插入在后处理(post processing)之前,这样后处理可以处理抗锯齿后的平滑图片以避免各种artifact。
DLSS的输出会是一个高分辨率的图片,所以引擎需要超采样后的分辨率下计算各种后处理特效,例如景深,动态模糊,tonemapping以及渲染UI。
DLSS 2.0渲染加速
DLSS 2.0加速渲染的原理很简单。开启DLSS后,引擎的渲染会在1/2到1/4像素的低分辨率下运行。这意味着,一大半的像素级别的计算直接被粗暴的砍掉了。像素级别的计算通常包括GBuffer的渲染,动态光源、阴影的计算,屏幕空间的特效例如屏幕空间环境遮挡(SSAO)、屏幕空间反射(SSR),甚至实时光线追踪。这些计算通常也是一帧里面最耗费性能的部分、毕竟大部分的画面出色的游戏,像素计算是绝对的瓶颈(pixel bound)。
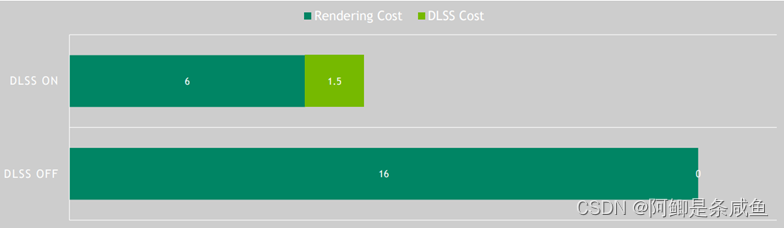
所以DLSS 2.0的加速多少,也直接取决于像素计算在多大程度上是性能瓶颈。通常来说,画面越好的3A大作,越会用更加耗费性能的渲染技术,像素也就会更大程度的成为瓶颈,而DLSS则会提供更大的加速!
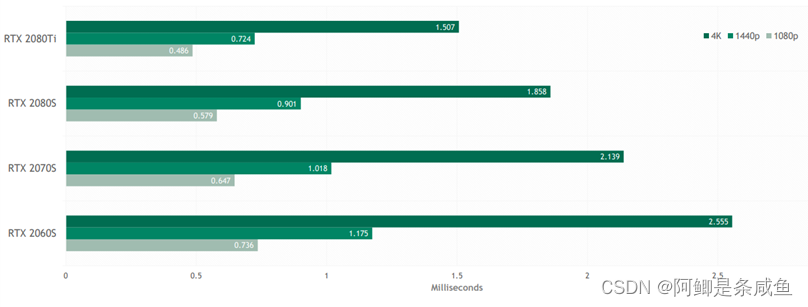
在省掉的渲染计算之上,运行DLSS 2.0这个算法本身会引入一定的开销,这个开销通常是完全取决于分辨率大小的,不随场景内容而改变。下面这个表格展示了DLSS 2.0在不同GPU和不同分辨率下的开销。相比于DLSS 1.0,我们把这个开销减小了两倍以上。在2080Ti上,4K分辨率下也只有1.5毫秒,因为有Tensor Core的加速,这已经和普通的TAA非常接近了。
三、DLSR挑战与总结
(一)DLSS效果对比
DLSS 2.0可以将540p的渲染图像直接放大到1080p,或者720p到1440p,1080p到4K。并且放大的画面在质量以及细节程度完全不输原生分辨率渲染,网上的许多测评也都反映了这一点。
下面放几组例子,第一个是一个几何非常密集的森林场景,开启实时光线追踪后540p原生分辨率渲染大概有89fps,但是因为分辨率太低,画面非常模糊。

如果1080p渲染,画面则清晰了很多,但是帧率也降低到48fps

使用DLSS2.0, 用540p分辨率渲染的画面作为输入,通过深度学习超采样至1080p,帧率提升到86fps,并且画质和原生十分接近。

但如果放大看的话,可以发现DLSS2.0的结果和原生1080p还是有一些差别,那么为了验证正确性,下面这个对比的左下角是每个像素用32个样本渲染的ground truth。很明显DLSS 2.0用在540p下渲染的结果,比1080p的原生渲染更接近ground truth!

(二)DLSS 2.0的优缺点
1. DLSS 2.0 四大特性
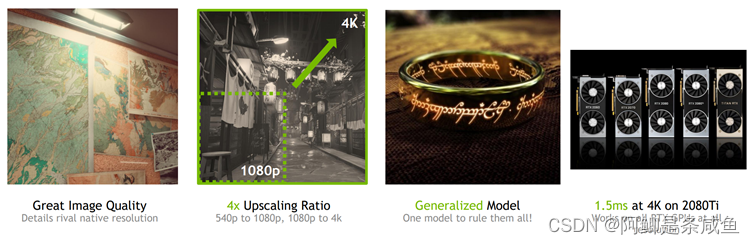
- 画质极大提升,细节和锐度媲美、甚至超越原生分辨率
- 4倍像素超采样(540p到1080p,1080p到4K,每4个像素中有3个是通过超采样生成)
- 通用模型,一个神经网络适用于所有游戏(不同引擎,着色风格,分辨率都有很强的通用性)
- Inference开销减半
2. DLSS缺点
- DLSS似乎不能很好地与某些AA技术(如TSAA)一起工作,当启用这些技术时,DLSS性能会受到严重影响。
- 此外,由于DLSS只能工作在张量核的GPU上,所以CUDA-only和Stream处理器的gpu不能实现DLSS。
(三)DLSR技术的展望
-
更简单的 SR 网络架构
虽然 DLSR 模型在图像重建方面取得了很高的准确率和保真度,但在本地部署仍然是极其困难且耗时的。由于拥有大量的计算成本和网络训练相关参数,DLSR需要大型数据中心或超级计算机。为了解决这个问题,需要降低空间和时间复杂度,降低计算成本,减少参数数量,还需要将图像质量保持在可接受范围内。 -
更有效的算法来补偿信息丢失
DLSR 模型的主要工作原理是从低分辨率输入重建高分辨率图像。但是,以非常低的内部分辨率(例如 540p)进行渲染,或者运行非常高的放大操作时(例如从 1080p 缩放到 8K),对于重建而言,此时的缺失数据量变得太大。这通常会导致错误表达或不准确的视觉数据。为了解决这个问题,需要努力使预测算法从更少的像素中更有效地提取视觉信息。 -
专注于更广泛的实施和支持
DLSR 是一项非常新的技术,仍处于起步阶段。因此,目前只有少数应用程序提供对 DLSR 的实现支持。需要完成工作并需要构建相关的 API 以扩展对更多应用程序的支持,并且必须为开发人员创建软件工具以实现更快的增长。
Postscript:总结
调查和攥写报告前前后后花了一周时间。前期也是随心所欲的查文献看资料写md,后期三天狂肝出小20页的报告还是相当痛苦的一件事……确实时间安排相当不合理(拖延症你又来啦),但更多的时间我认为是花费在捋思路上。在查阅资料过程中,我一直在尝试摸清内在的逻辑链——可惜思路一直被推翻重建,文章结构也一改再改,直到ddl前的最后一天的我基本满意。
总体来说,收获还是相当大的,调研调查本身就是一件令人兴奋的事——可以自己思考内在联系,提出问题,再去解决……这也是我第一次看这么多的外文材料(原先对英文文献有些畏惧心理,一直没有迈出这一步,或者说没迈几步)。
我最感兴趣或者最想从事的方向之一就是游戏开发(一个爱玩游戏的人也想去做游戏)。原先我多多少少低估了这个领域的难度,但现在更多地我对这个方向产生了敬畏之情。当然打动我的还有很多这个领域的前辈们。当我研究《Real time rendering》,翻看毛星云的总结提炼时,我佩服着他的热爱,也惋惜着他的离开;当我浏览文刀秋二的知乎回答时,我也是深深佩服的——我认为我对coding是很感兴趣的,以至于每次课设和项目我很多时间都花在学习新东西加上去,以做得好些,更好些。但当我发现大神的"兴趣"后,我也意识到,我还有很长的一段路要走:

最后再来谈谈这篇文章,个人感觉更多的还是在学习摘抄借鉴。写绪论的时候还在手敲,附引用;写抗锯齿部分的时候还能整合多份资料,翻译网站文献,再做校对;等写到DLSS时就开始复制粘贴了……总体而言,更像是多家资料的大合集,勉勉强强一个优点就是有自己的思考在内。当然,如有错误和问题,欢迎探讨。道阻且长,这是一次把报告整理至CSDN上,相信不会是最后一次!