1.前言
Grok是一种强大的日志解析工具,用于将结构化和非结构化的日志数据转换为可查询和分析的格式。它是由Elasticsearch的Logstash组件提供的一种插件,也可以作为独立的库在其他数据处理工具中使用,Grok通过使用预定义的模式(正则表达式)和模板,将复杂的日志行解析为具有可命名字段的结构化数据,即json结构。它可以解析各种格式的日志,如Apache日志、系统日志、应用程序日志等
2.作用
日志解析:Grok可以从原始日志数据中提取有用的字段,并将其解析为结构化的键值对。例如,它可以从一行Apache访问日志中提取IP地址、访问时间、请求方法、URL等信息,并将其存储为可查询的字段
数据标准化:由于日志的格式和结构通常不统一,不同应用和系统生成的日志可能具有不同的字段和格式。使用Grok,可以将这些不同格式的日志标准化为一致的格式,使其易于分析和处理
查询和过滤:通过将日志解析为结构化数据,可以使用查询语言(如Elasticsearch的查询语法)对日志数据进行灵活的查询和过滤。这样可以轻松筛选出感兴趣的日志事件,进行故障排除、监控分析、安全审计等操作
可视化和报告:通过将日志解析为结构化数据,可以将其与其他指标和数据源进行联合分析,并使用可视化工具(如Kibana)创建交互式仪表板和报告。这样可以更清晰地呈现日志数据的趋势、异常和关联性
3.使用
转化日志为结构化日志
以下通过一段nginx的access来展示grok通过正则表达式和预定义模板字段将非结构化日志解析为结构化日志的功能,我们可以使用kibana的grok debug功能来测试

访问一下nginx服务的80端口来生成access日志
curl 10.1.60.114
tail -f /var/log/nginx/access.log
10.1.13.252 - - [05/Jul/2023:10:55:37 +0800] "GET /img/header-background.png HTTP/1.1" 200 82896 "http://10.1.60.114/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36" "-"
将以上获取的日志填入到数据样例中
接下来就可以在grok模式里 写入正则和预定义模板来将以上的日志转化为结构化日志
先来简单的匹配一下前面的ip
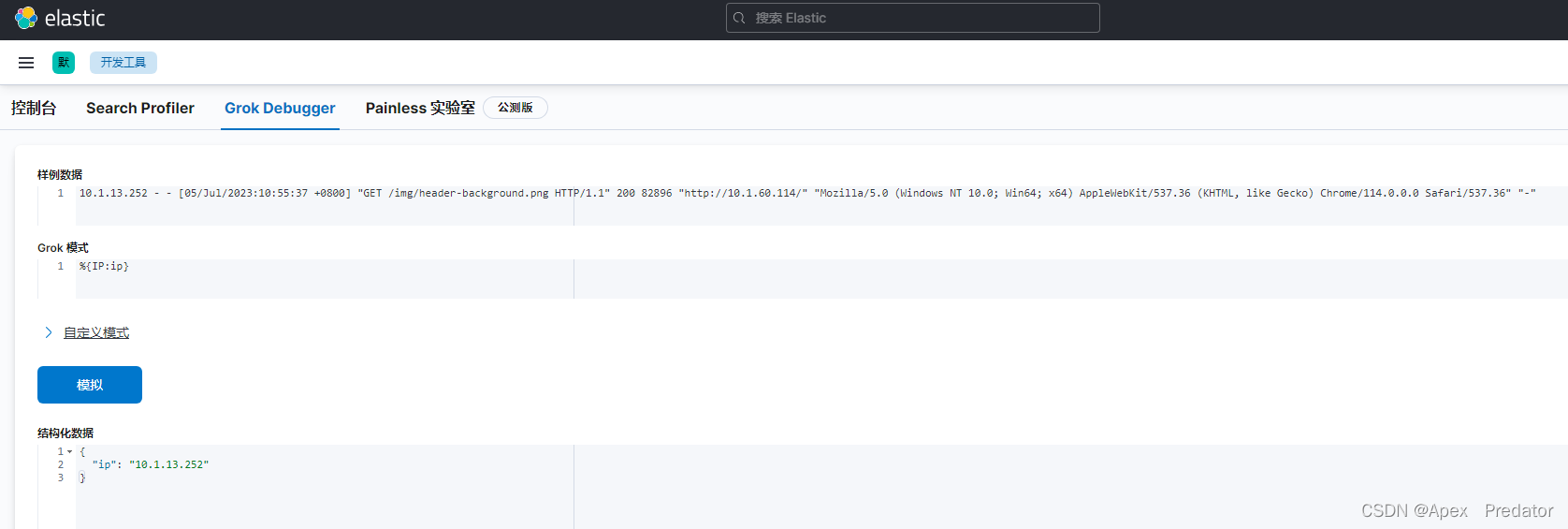
这里是使用了预定义模板里的值IP,即预定义模板里是写好了的正则,直接通过变量调用即可 ,关于grok的预定义模板下面会展示出来
接下来继续匹配一下后面的内容,继续使用正则表达式和预定义模板
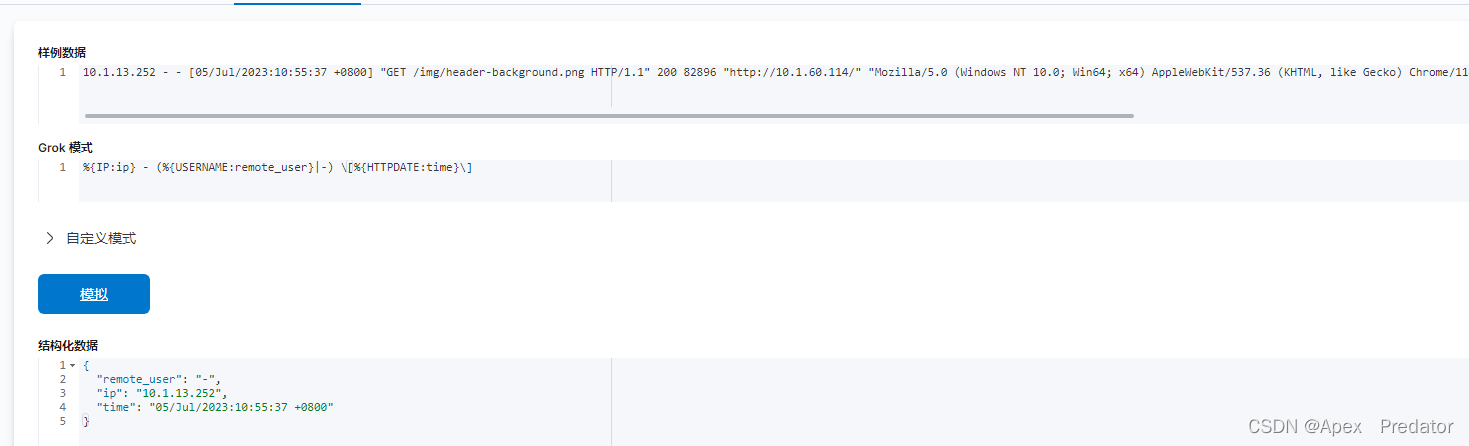
对于固定的内容就直接把内容写入到语句里就可以了,如果有涉及正则表达式的字符就需要使用转义符,以上的[]是正则表达式里匹配中括号里任意内容的意思,所以需要使用转义符去转义为普通的字符
关于后面的匹配我就放出完整的grok表达式
%{IP:ip} - (%{USERNAME:remote_user}|-) \[%{HTTPDATE:time}\] \"%{WORD:request_method} %{URIPATHPARAM:request_uri} HTTP/%{NUMBER:http_version}\" %{NUMBER:http_status} %{NUMBER:bytes} \"(%{DATA:referrer}|-)\" \"%{DATA:http_agent}\" \"(%{DATA:forwarded}|-)\"
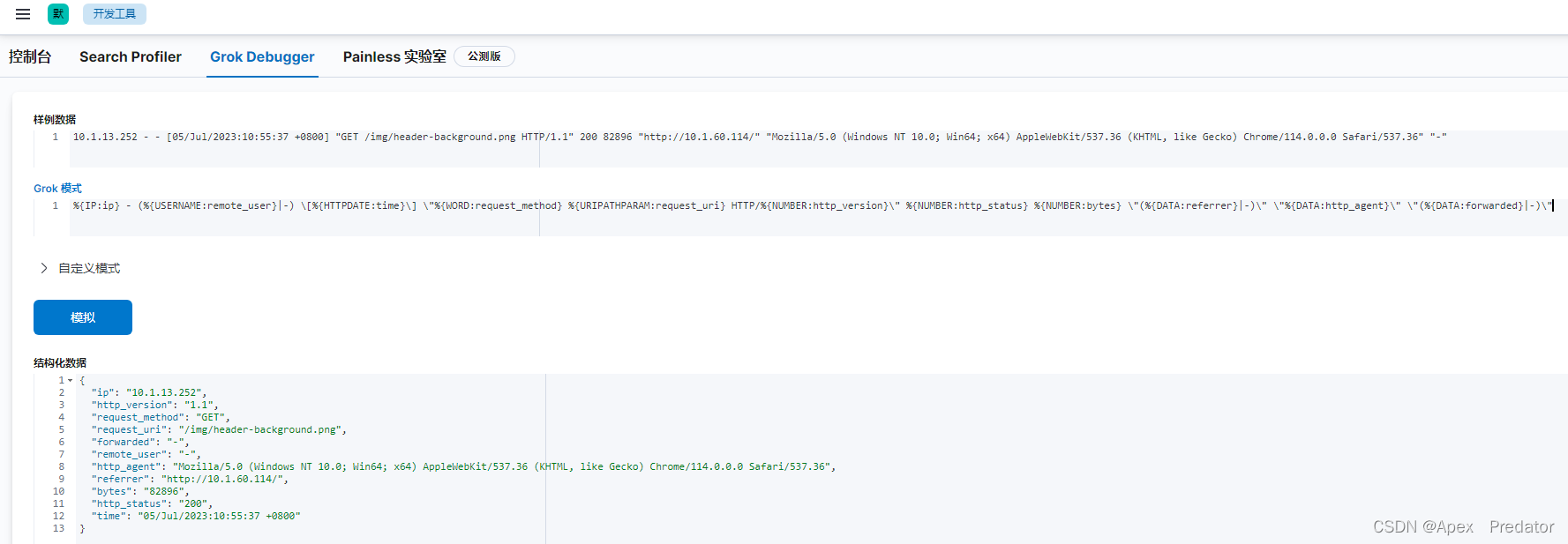
可以看到使用这条表达式完整的匹配了所有日志内容后,将以上的非结构化日志转化为了结构化日志
再来看一条nginx error日志的转化
可以更改nginx的配置文件,随意往里面加入一些字符,再重载nginx配置就会产生报错日志
nginx -s reload
tail -f /var/log/nginx/error.log
2023/07/05 12:29:48 [emerg] 12584#12584: unknown directive "sdasdasd" in /etc/nginx/nginx.conf:35
%{DATA:timestamp} \[%{WORD:severity}\] %{NUMBER:pid}#%{NUMBER:tid}: %{GREEDYDATA:prompt}
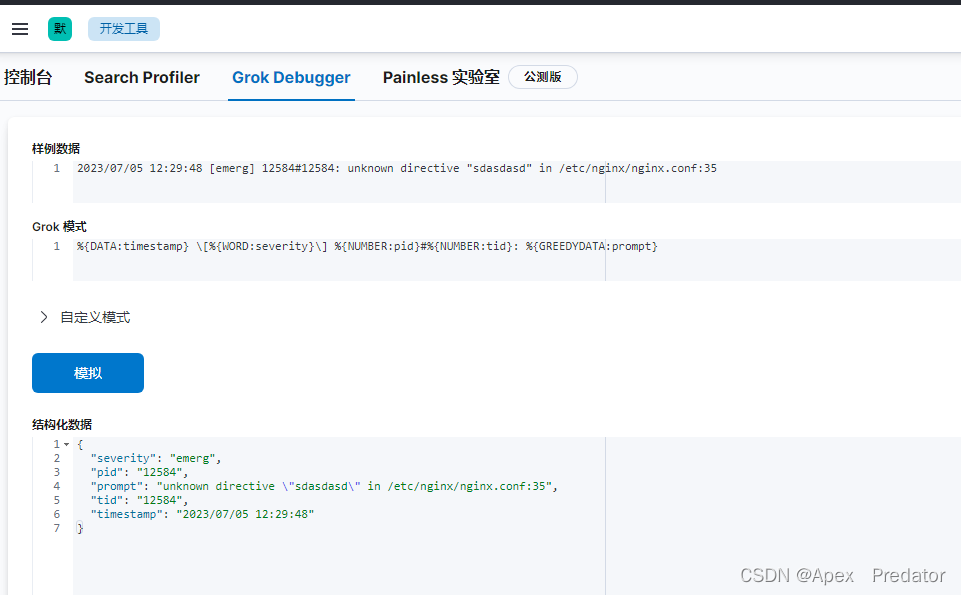
可以看到使用以上的表达式,将error日志的非结构化日志,成功转化为了结构化日志
这个功能主要是再logstash使用,在logstash接收的日志为非结构化日志时,就需要用到filter中的grok去将日志转化为结构化日志,使日志在kibana中能更直观的展示出来,也方便查询
4.pattern(预定义模板)
logstash中有预定义的模板提供给grok使用,预定义模板中每个变量都有写好的正则表达式,在构建结构化日志时,直接调用变量即可,接下来看一下预定义模板中都有哪些正则表达式
在logstash的安装包目录下查找patterns目录
find /opt/logstash/logstash -name patterns
![]()
ls -ll /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/
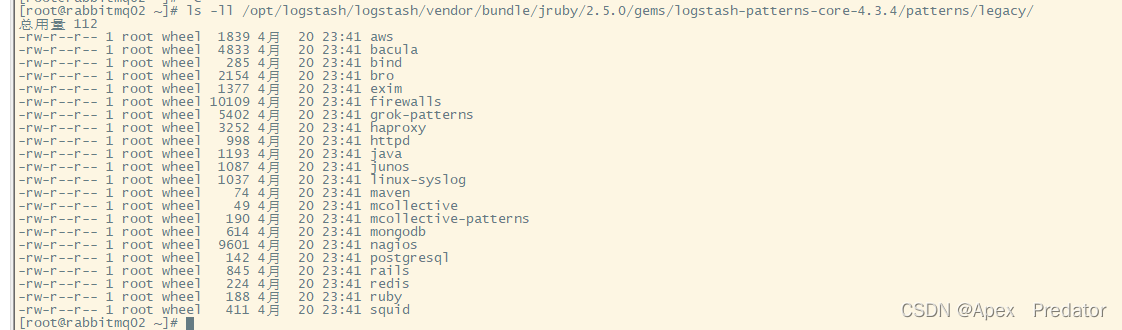
上图中的文件都是预定义模板,每个文件里都有多项预定义好的正则表达式,我们查看一下grok-patterns里的预定义表达式
cat /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/grok-patterns
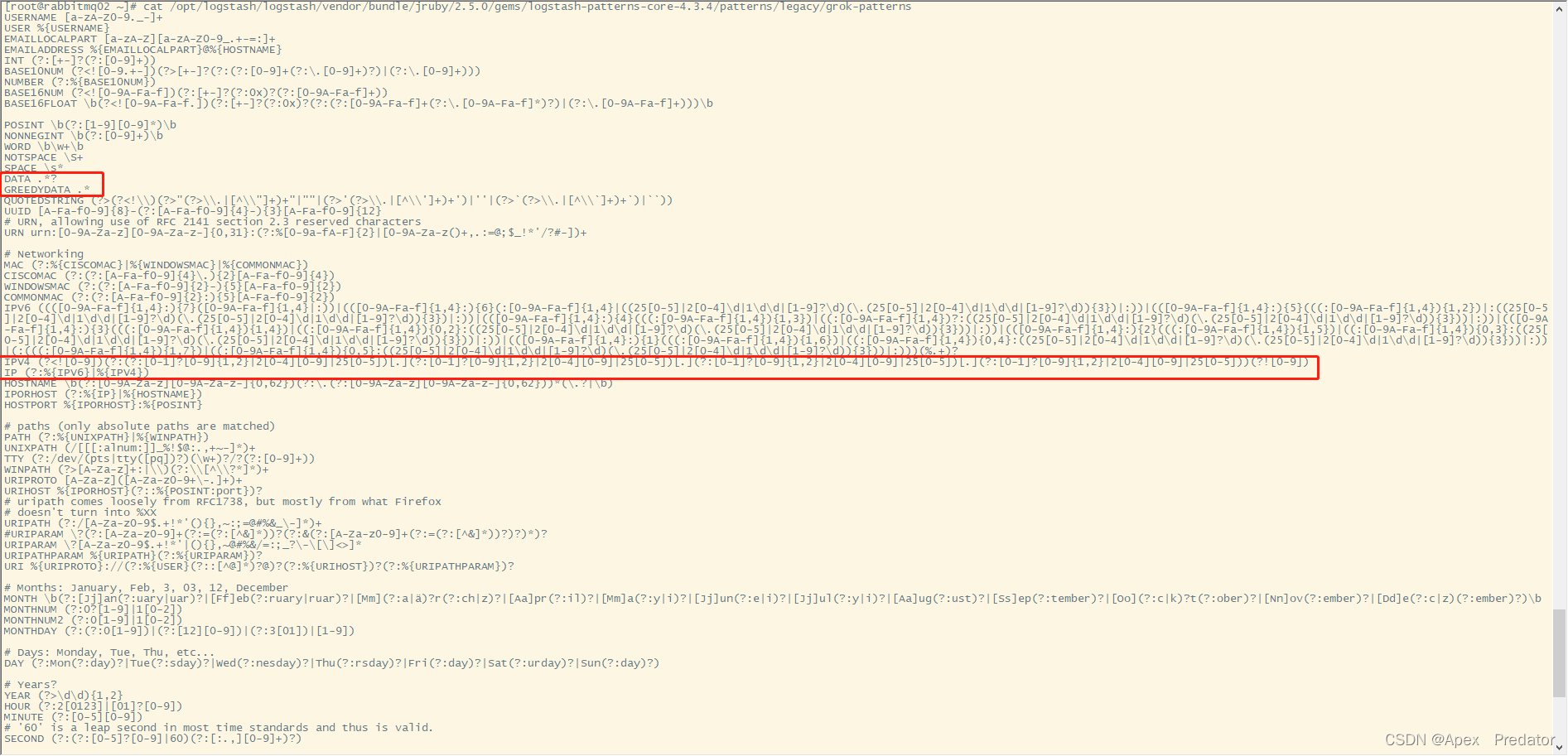
可以看到里面有很多预定义好的正则表达式,我们刚刚上面的表达里所使用的预定义模板都在里面,例如DATA、IP、GREEDYDATA他们名字后面都有带正则表达式,其它更多的表达式就需要自己在预定义模板文件中寻找了
这里额外补充一个知识,DATA和GREEDYDATA的正则表达式一个是.*一个是.*?
.*:这是贪婪模式,表示匹配任意长度的字符序列,包括空字符串和换行符之外的所有字符。它会尽可能地匹配尽量多的字符
.*?:这是非贪婪模式,表示匹配尽可能少的字符序列。问号 ? 放在量词 * 或 + 的后面,表示尽量少匹配。它会匹配任意长度的字符序列,但只匹配到满足后面的模式的最早的位置
在使用中需要注意这两个正则表达式,就如同上面案例中的表达式中末尾使用的是GREEDYDATA它使用的正则表达式是.*即会匹配后面所有的字符,要是末尾使用的是DATA 就会匹配为空