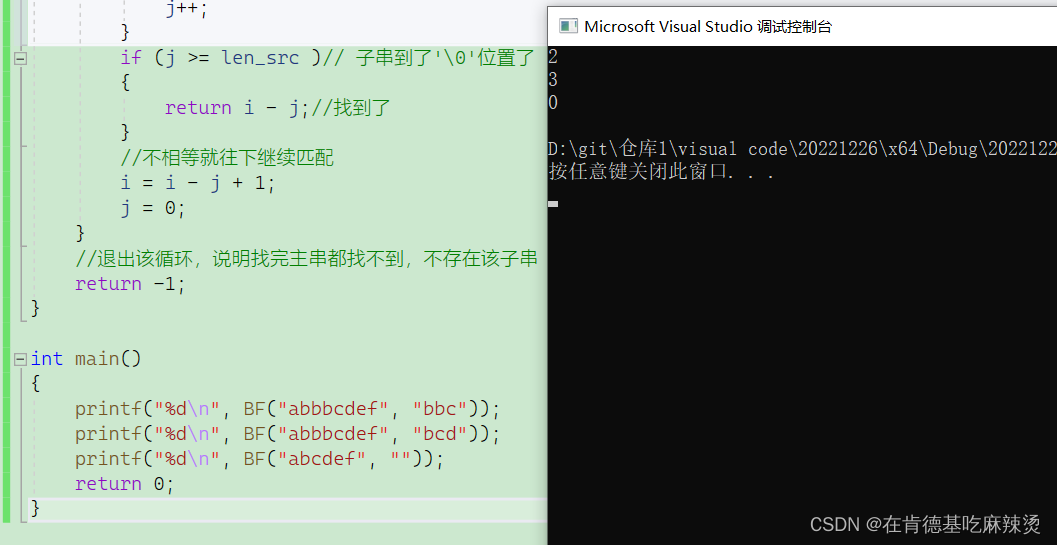
自然语言技术
零基础入门NLP - 新闻文本分类
基于word2vec的word相似度
疫情微博情绪识别挑战赛
- 自然语言技术
- 背景
- 一、赛事任务
- 二、使用步骤
- 1.README
- 2.数据下载
- 3.模型训练及保存
- 4.模型预测
- 5.比赛结果
背景
疫情发生对人们生活生产的方方面面产生了重要影响,并引发了国内舆论的广泛关注,众多网民也参与到了疫情相关话题的讨论中。大众日常的情绪波动在疫情期间会放大,并寻求在自媒体和社交媒体上发布和评论。为了掌握真实社会舆论情况,科学高效地做好防控宣传和舆情引导工作,针对疫情相关话题开展网民情绪识别是重要任务。本次我们重点关注微博平台上的用户情绪,希望各位选手能搭建自然语言处理模型,对疫情下微博文本的情绪进行识别。
一、赛事任务
本次赛题需要选手对微博文本进行情绪分类,分为正向情绪和负面情绪。
二、使用步骤
1.README
|–README.md # 解决⽅案及算法介绍⽂件,必选
|–requirements.txt # Python环境依赖
|–xfdata # ⽐赛数据集
|–user_data # 选⼿数据⽂件夹
|----model_data # 模型⽂件夹示例,可⾃⾏组织
|----tmp_data # 临时存储⽂件夹示例,可⾃⾏组织
|–prediction_result # 预测结果
|–code # 选⼿代码⽂件夹
|–train # 训练代码⽂件夹示例,可⾃⾏组织
|–test # 预测代码⽂件夹示例,可⾃⾏组织
|–test.sh # 预测执⾏脚本,必选
|–train.sh # 训练示例脚本,必选
2.数据下载
数据下载
3.模型训练及保存
import emojiswitch
import os
import json
import random
import time
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import paddle
import paddlenlp
import paddle.nn.functional as F
from functools import partial
from paddlenlp.data import Stack, Dict, Pad
from paddlenlp.datasets import load_dataset
import paddle.nn as nn
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import pearsonr
from paddlenlp.transformers.auto.tokenizer import AutoTokenizer
from paddlenlp.transformers.auto.modeling import AutoModelForSequenceClassificationseed = 10000
def set_seed(seed):paddle.seed(seed)random.seed(seed)np.random.seed(seed)
set_seed(seed)
# 超参数
MODEL_NAME = 'ernie-3.0-base-zh'
# 设置最大阶段长度 和 batch_size
#max_seq_length = 200
max_seq_length = 175
train_batch_size = 64
valid_batch_size = 64
test_batch_size = 16
# 训练过程中的最大学习率
learning_rate = 2e-5
# 训练轮次
epochs = 4
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
max_grad_norm = 1.0
#路径
data_path = (os.path.abspath(os.path.join(os.getcwd(), "..")))
# 训练结束后,存储模型参数
save_dir_curr = "checkpoint/{}-model".format(MODEL_NAME.replace('/','-'))
print(save_dir_curr)
save_dir_curr = os.path.join(data_path,"user_data/model_data")
print(save_dir_curr)
# 记录训练epoch、损失等值
loggiing_print = 50
loggiing_eval = 200
# 是否开启 mutli-dropout
enable_mdrop = True
enable_adversarial = False
layer_mode = 'dym' # cls / mean / max / dymtrain_path = os.path.join(data_path,"xfdata/train.csv")
test_path = os.path.join(data_path,"xfdata/train.csv")train = pd.read_csv(train_path,sep='\t')#[:1000]
test = pd.read_csv(test_path,sep='\t')#[:100]
import re
def clean_str(text):text = emojiswitch.demojize(text,delimiters=("",""), lang="zh") # Emoji转文字URL_REGEX = re.compile(r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))',re.IGNORECASE)text = text.replace("转发微博", "") # 去除无意义的词语text = text.replace('展开全文', '')text = text.replace('?展开全文c', '')text = text.replace('?', '?')text = text.replace('!', '!')text = text.replace('。', '.')text = text.replace(',', ',')text = text.replace('//?', '')for i in range(66, 1, -1):word = i*'?'text = text.replace(word, '?')for i in range(66, 1, -1):word = i*'.'text = text.replace(word, '?')for i in range(66, 1, -1):word = i*'!'text = text.replace(word, '?')for i in range(66, 1, -1):word = i*'@'text = text.replace(word, '?')text = re.sub(r"\s+", " ", text) # 合并正文中过多的空格return text.strip()
train['text'] = train['text'].apply(lambda x: clean_str(x))
test['text'] = test['text'].apply(lambda x: clean_str(x))# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)# 创建数据迭代器iter
def read(df,istrain=True):if istrain:for _,data in df.iterrows():yield {"words":data['text'],"labels":data['label']}else:for _,data in df.iterrows():yield {"words":data['text'],}# 将生成器传入load_dataset
train,valid = train_test_split(train,test_size=0.1,random_state=seed)
train_ds = load_dataset(read, df=train, lazy=False)
valid_ds = load_dataset(read, df=valid, lazy=False)
# 编码
def convert_example(example, tokenizer, max_seq_len=512, mode='train'):# 调用tokenizer的数据处理方法把文本转为idtokenized_input = tokenizer(example['words'],is_split_into_words=True,max_seq_len=max_seq_len)if mode == "test":return tokenized_input# 把意图标签转为数字idtokenized_input['labels'] = [example['labels']]return tokenized_input # 字典形式,包含input_ids、token_type_ids、labelstrain_trans_func = partial(convert_example,tokenizer=tokenizer,mode='train',max_seq_len=max_seq_length)valid_trans_func = partial(convert_example,tokenizer=tokenizer,mode='dev',max_seq_len=max_seq_length)# 映射编码
train_ds.map(train_trans_func, lazy=False)
valid_ds.map(valid_trans_func, lazy=False)# 初始化BatchSampler
np.random.seed(seed)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=train_batch_size, shuffle=True)
valid_batch_sampler = paddle.io.BatchSampler(valid_ds, batch_size=valid_batch_size, shuffle=False)# 定义batchify_fn
batchify_fn = lambda samples, fn = Dict({"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id), "token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),"labels": Stack(dtype="int32"),
}): fn(samples)# 初始化DataLoader
train_data_loader = paddle.io.DataLoader(dataset=train_ds,batch_sampler=train_batch_sampler,collate_fn=batchify_fn,return_list=True)
valid_data_loader = paddle.io.DataLoader(dataset=valid_ds,batch_sampler=valid_batch_sampler,collate_fn=batchify_fn,return_list=True)
from paddlenlp.transformers.ernie.modeling import ErniePretrainedModel# 原始的基于Ernie的分类模型
class EmotionErnieModel(ErniePretrainedModel):def __init__(self, ernie, num_classes=1, dropout=None):super().__init__()# 预训练模型self.ernie = ernieself.num_classes = num_classesself.dropout = nn.Dropout(self.ernie.config['hidden_dropout_prob'])self.classifier = nn.Linear(self.ernie.config['hidden_size'],self.num_classes)self.apply(self.init_weights)def forward(self,input_ids,token_type_ids=None):sequence_output , _ = self.ernie(input_ids,token_type_ids=token_type_ids)sequence_output = sequence_output.mean(axis=1)sequence_output = self.dropout(sequence_output) logits = self.classifier(sequence_output)return logits
# 增加MultiDropout-Ernie的分类模型
class Mdrop(nn.Layer):def __init__(self):super(Mdrop,self).__init__()self.dropout_0 = nn.Dropout(p=0)self.dropout_1 = nn.Dropout(p=0.1)self.dropout_2 = nn.Dropout(p=0.2)self.dropout_3 = nn.Dropout(p=0.3)self.dropout_4 = nn.Dropout(p=0.4)self.dropout_5 = nn.Dropout(p=0.4)def forward(self,x):output_0 = self.dropout_0(x)output_1 = self.dropout_1(x)output_2 = self.dropout_2(x)output_3 = self.dropout_3(x)output_4 = self.dropout_4(x)output_5 = self.dropout_5(x)return [output_0,output_1,output_2,output_3,output_4,output_5]
class EmotionMDropErnieModel(ErniePretrainedModel):def __init__(self, ernie, num_classes=1, dropout=None):super().__init__()# 预训练模型self.ernie = ernieself.num_classes = num_classes# 设置mutlidropoutself.dropout = Mdrop()self.classifier = nn.Linear(self.ernie.config['hidden_size'],self.num_classes)self.apply(self.init_weights)def forward(self,input_ids,token_type_ids=None):sequence_output , _ = self.ernie(input_ids,token_type_ids=token_type_ids)sequence_output = sequence_output.mean(axis=1)sequence_output = self.dropout(sequence_output)# 将mutlidropout进行poolingsequence_output = paddle.mean(paddle.stack(sequence_output,axis=0),axis=0) logits = self.classifier(sequence_output)return logits # 不同嵌入策略的分类模型
class EmotionLayerModel(ErniePretrainedModel):def __init__(self, ernie, num_classes=1, dropout=None):super().__init__()# 预训练模型self.ernie = ernieself.num_classes = num_classesself.dropout = nn.Dropout(self.ernie.config['hidden_dropout_prob'])self.classifier = nn.Linear(self.ernie.config['hidden_size'],self.num_classes)self.dym_pool = nn.Linear(self.ernie.config['hidden_size'],1)self.apply(self.init_weights)def dym_pooling(self, avpooled_out, maxpooled_out):pooled_output = [avpooled_out, maxpooled_out]pool_logits = []for i, layer in enumerate(pooled_output):pool_logits.append(self.dym_pool(layer))pool_logits = paddle.concat(pool_logits, axis=-1)pool_dist = paddle.nn.functional.softmax(pool_logits)pooled_out = paddle.concat([paddle.unsqueeze(x, 2) for x in pooled_output], axis=2)pooled_out = paddle.unsqueeze(pooled_out, 1)pool_dist = paddle.unsqueeze(pool_dist, 2)pool_dist = paddle.unsqueeze(pool_dist, 1)pooled_output = paddle.matmul(pooled_out, pool_dist)pooled_output = paddle.squeeze(pooled_output)return pooled_outputdef forward(self,input_ids,token_type_ids=None):sequence_output , pooled_output = self.ernie(input_ids,token_type_ids=token_type_ids)# 选择嵌入策略if layer_mode == "mean":output = sequence_output.mean(axis=1)elif layer_mode == "max":output = sequence_output.max(axis=1)elif layer_mode == "dym":mean_output = sequence_output.mean(axis=1)max_output = sequence_output.max(axis=1)output = self.dym_pooling(mean_output,max_output)else:# 默认使用clsoutput = pooled_outputoutput = self.dropout(output) logits = self.classifier(output)return logits
# 改进后的模型
class EmotionModel(ErniePretrainedModel):def __init__(self, ernie, num_classes=1, dropout=None):super().__init__()# 预训练模型self.ernie = ernieself.num_classes = num_classesif enable_mdrop:self.dropout = Mdrop()else:self.dropout = nn.Dropout(self.ernie.config['hidden_dropout_prob'])self.classifier = nn.Linear(self.ernie.config['hidden_size'],self.num_classes)self.dym_pool = nn.Linear(self.ernie.config['hidden_size'],1)self.apply(self.init_weights)def dym_pooling(self, avpooled_out, maxpooled_out):pooled_output = [avpooled_out, maxpooled_out]pool_logits = []for i, layer in enumerate(pooled_output):pool_logits.append(self.dym_pool(layer))pool_logits = paddle.concat(pool_logits, axis=-1)pool_dist = paddle.nn.functional.softmax(pool_logits)pooled_out = paddle.concat([paddle.unsqueeze(x, 2) for x in pooled_output], axis=2)pooled_out = paddle.unsqueeze(pooled_out, 1)pool_dist = paddle.unsqueeze(pool_dist, 2)pool_dist = paddle.unsqueeze(pool_dist, 1)pooled_output = paddle.matmul(pooled_out, pool_dist)pooled_output = paddle.squeeze(pooled_output)return pooled_outputdef forward(self,input_ids,token_type_ids=None):sequence_output , pooled_output = self.ernie(input_ids,token_type_ids=token_type_ids)# 选择嵌入策略if layer_mode == "mean":output = sequence_output.mean(axis=1)elif layer_mode == "max":output = sequence_output.max(axis=1)elif layer_mode == "dym":mean_output = sequence_output.mean(axis=1)max_output = sequence_output.max(axis=1)output = self.dym_pooling(mean_output,max_output)else:# 默认使用clsoutput = pooled_output# 选择dropoutoutput = self.dropout(output)if enable_mdrop:output = paddle.mean(paddle.stack(output,axis=0),axis=0) # 下游任务logits = self.classifier(output)return logits
# 创建model
label_classes = train['label'].unique()
model = EmotionModel.from_pretrained(MODEL_NAME,num_classes=len(label_classes))
# 训练总步数
num_training_steps = len(train_data_loader) * epochs# 学习率衰减策略
lr_scheduler = paddlenlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps,warmup_proportion)decay_params = [p.name for n, p in model.named_parameters()if not any(nd in n for nd in ["bias", "norm"])
]# 定义优化器
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,parameters=model.parameters(),weight_decay=weight_decay,apply_decay_param_fun=lambda x: x in decay_params,grad_clip=paddle.nn.ClipGradByGlobalNorm(max_grad_norm))
# utils - 对抗训练 FGM
class FGM(object):"""Fast Gradient Method(FGM)针对 embedding 层梯度上升干扰的对抗训练方法"""def __init__(self, model, epsilon=1., emb_name='emb'):# emb_name 这个参数要换成你模型中embedding 的参数名self.model = modelself.epsilon = epsilonself.emb_name = emb_nameself.backup = {}def attack(self):for name, param in self.model.named_parameters():if not param.stop_gradient and self.emb_name in name: # 检验参数是否可训练及范围self.backup[name] = param.numpy() # 备份原有参数值grad_tensor = paddle.to_tensor(param.grad) # param.grad 是个 numpy 对象norm = paddle.norm(grad_tensor) # norm 化if norm != 0:r_at = self.epsilon * grad_tensor / normparam.add(r_at) # 在原有 embed 值上添加向上梯度干扰def restore(self):for name, param in self.model.named_parameters():if not param.stop_gradient and self.emb_name in name:assert name in self.backupparam.set_value(self.backup[name]) # 将原有 embed 参数还原self.backup = {}# 对抗训练
if enable_adversarial:adv = FGM(model=model,epsilon=1e-6,emb_name='word_embeddings')
# 验证部分
@paddle.no_grad()
def evaluation(model, data_loader):model.eval()real_s = []pred_s = []for batch in data_loader:input_ids, token_type_ids, labels = batchlogits = model(input_ids, token_type_ids)probs = F.softmax(logits,axis=1)pred_s.extend(probs.argmax(axis=1).numpy())real_s.extend(labels.reshape([-1]).numpy())score = accuracy_score(y_pred=pred_s,y_true=real_s)return score# 训练阶段
def do_train(model,data_loader):total_loss = 0.model_total_epochs = 0best_score = 0.9training_loss = 0# 训练print("train ...")train_time = time.time()valid_time = time.time()model.train()for epoch in range(0, epochs):preds,reals = [],[]for step, batch in enumerate(data_loader, start=1):input_ids, token_type_ids, labels = batchlogits = model(input_ids, token_type_ids)loss = F.softmax_with_cross_entropy(logits,labels).mean()probs = F.softmax(logits,axis=1)preds.extend(probs.argmax(axis=1))reals.extend(labels.reshape([-1]))loss.backward()# 对抗训练if enable_adversarial:adv.attack() # 在 embedding 上添加对抗扰动adv_logits = model(input_ids, token_type_ids)adv_loss = F.softmax_with_cross_entropy(adv_logits,labels).mean()adv_loss.backward() # 反向传播,并在正常的 grad 基础上,累加对抗训练的梯度adv.restore() # 恢复 embedding 参数total_loss += loss.numpy()optimizer.step()lr_scheduler.step()optimizer.clear_grad()model_total_epochs += 1if model_total_epochs % loggiing_print == 0:train_acc = accuracy_score(preds,reals)print("step: %d / %d, train acc: %.5f training loss: %.5f speed %.1f s" % (model_total_epochs, num_training_steps, train_acc, total_loss/model_total_epochs,(time.time() - train_time)))train_time = time.time()if model_total_epochs % loggiing_eval == 0:eval_score = evaluation(model, valid_data_loader)print("validation speed %.2f s" % (time.time() - valid_time))valid_time = time.time()if best_score < eval_score:print("eval acc: %.5f acc update %.5f ---> %.5f " % (eval_score,best_score,eval_score))best_score = eval_score# 保存模型os.makedirs(save_dir_curr,exist_ok=True)save_param_path = os.path.join(save_dir_curr, 'model_best.pdparams')paddle.save(model.state_dict(), save_param_path)# 保存tokenizertokenizer.save_pretrained(save_dir_curr)else:print("eval acc: %.5f but best acc %.5f " % (eval_score,best_score))model.train()return best_score
best_score = do_train(model,train_data_loader)# logging partlogging_dir = os.path.join(data_path, 'user_data/tmp_data')
logging_name = os.path.join(logging_dir,'run_logging.csv')
os.makedirs(logging_dir,exist_ok=True)var = [MODEL_NAME, seed, learning_rate, max_seq_length, layer_mode, enable_mdrop, enable_adversarial, best_score]
names = ['model', 'seed', 'lr', "max_len" , 'layer_mode', 'enable_mdrop', 'enable_adversarial', 'best_score']
vars_dict = {k: v for k, v in zip(names, var)}
results = dict(**vars_dict)
keys = list(results.keys())
values = list(results.values())if not os.path.exists(logging_name): ori = []ori.append(values)logging_df = pd.DataFrame(ori, columns=keys)logging_df.to_csv(logging_name, index=False)
else:logging_df= pd.read_csv(logging_name)new = pd.DataFrame(results, index=[1])logging_df = logging_df.append(new, ignore_index=True)logging_df.to_csv(logging_name, index=False) 4.模型预测
import emojiswitch
import os
import json
import random
import time
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import paddle
import paddlenlp
import paddle.nn.functional as F
from functools import partial
from paddlenlp.data import Stack, Dict, Pad
from paddlenlp.datasets import load_dataset
import paddle.nn as nn
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import pearsonr
from paddlenlp.transformers.auto.tokenizer import AutoTokenizer
from paddlenlp.transformers.auto.modeling import AutoModelForSequenceClassificationseed = 10000
def set_seed(seed):paddle.seed(seed)random.seed(seed)np.random.seed(seed)
set_seed(seed)
# 超参数
MODEL_NAME = 'ernie-3.0-base-zh'
# 设置最大阶段长度 和 batch_size
max_seq_length = 175
train_batch_size = 32
valid_batch_size = 32
test_batch_size = 16
# 训练过程中的最大学习率
learning_rate = 2e-5
# 训练轮次
epochs = 4
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
max_grad_norm = 1.0
#路径
data_path = (os.path.abspath(os.path.join(os.getcwd(), "..")))
# 训练结束后,存储模型参数
save_dir_curr = "checkpoint/{}-model".format(MODEL_NAME.replace('/','-'))
print(save_dir_curr)
save_dir_curr = os.path.join(data_path,"user_data/model_data")
print(save_dir_curr)
# 记录训练epoch、损失等值
loggiing_print = 50
loggiing_eval = 200
# 是否开启 mutli-dropout
enable_mdrop = True
enable_adversarial = False
layer_mode = 'dym' # cls / mean / max / dymtrain_path = os.path.join(data_path,"xfdata/train.csv")
test_path = os.path.join(data_path,"xfdata/train.csv")train = pd.read_csv(train_path,sep='\t')[:1000]
test = pd.read_csv(test_path,sep='\t')[:100]
import re
def clean_str(text):text = emojiswitch.demojize(text,delimiters=("",""), lang="zh") # Emoji转文字URL_REGEX = re.compile(r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))',re.IGNORECASE)text = text.replace("转发微博", "") # 去除无意义的词语text = text.replace('展开全文', '')text = text.replace('?展开全文c', '')text = text.replace('?', '?')text = text.replace('!', '!')text = text.replace('。', '.')text = text.replace(',', ',')text = text.replace('//?', '')for i in range(66, 1, -1):word = i*'?'text = text.replace(word, '?')for i in range(66, 1, -1):word = i*'.'text = text.replace(word, '?')for i in range(66, 1, -1):word = i*'!'text = text.replace(word, '?')for i in range(66, 1, -1):word = i*'@'text = text.replace(word, '?')text = re.sub(r"\s+", " ", text) # 合并正文中过多的空格return text.strip()
train['text'] = train['text'].apply(lambda x: clean_str(x))
test['text'] = test['text'].apply(lambda x: clean_str(x))# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)# 创建数据迭代器iter
def read(df,istrain=True):if istrain:for _,data in df.iterrows():yield {"words":data['text'],"labels":data['label']}else:for _,data in df.iterrows():yield {"words":data['text'],}# 将生成器传入load_dataset
train,valid = train_test_split(train,test_size=0.1,random_state=seed)
train_ds = load_dataset(read, df=train, lazy=False)
valid_ds = load_dataset(read, df=valid, lazy=False)
# 编码
def convert_example(example, tokenizer, max_seq_len=512, mode='train'):# 调用tokenizer的数据处理方法把文本转为idtokenized_input = tokenizer(example['words'],is_split_into_words=True,max_seq_len=max_seq_len)if mode == "test":return tokenized_input# 把意图标签转为数字idtokenized_input['labels'] = [example['labels']]return tokenized_input # 字典形式,包含input_ids、token_type_ids、labelstrain_trans_func = partial(convert_example,tokenizer=tokenizer,mode='train',max_seq_len=max_seq_length)valid_trans_func = partial(convert_example,tokenizer=tokenizer,mode='dev',max_seq_len=max_seq_length)# 映射编码
train_ds.map(train_trans_func, lazy=False)
valid_ds.map(valid_trans_func, lazy=False)# 初始化BatchSampler
np.random.seed(seed)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=train_batch_size, shuffle=True)
valid_batch_sampler = paddle.io.BatchSampler(valid_ds, batch_size=valid_batch_size, shuffle=False)# 定义batchify_fn
batchify_fn = lambda samples, fn = Dict({"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id), "token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),"labels": Stack(dtype="int32"),
}): fn(samples)# 初始化DataLoader
train_data_loader = paddle.io.DataLoader(dataset=train_ds,batch_sampler=train_batch_sampler,collate_fn=batchify_fn,return_list=True)
valid_data_loader = paddle.io.DataLoader(dataset=valid_ds,batch_sampler=valid_batch_sampler,collate_fn=batchify_fn,return_list=True)
from paddlenlp.transformers.ernie.modeling import ErniePretrainedModel# 原始的基于Ernie的分类模型
class EmotionErnieModel(ErniePretrainedModel):def __init__(self, ernie, num_classes=1, dropout=None):super().__init__()# 预训练模型self.ernie = ernieself.num_classes = num_classesself.dropout = nn.Dropout(self.ernie.config['hidden_dropout_prob'])self.classifier = nn.Linear(self.ernie.config['hidden_size'],self.num_classes)self.apply(self.init_weights)def forward(self,input_ids,token_type_ids=None):sequence_output , _ = self.ernie(input_ids,token_type_ids=token_type_ids)sequence_output = sequence_output.mean(axis=1)sequence_output = self.dropout(sequence_output) logits = self.classifier(sequence_output)return logits
# 增加MultiDropout-Ernie的分类模型
class Mdrop(nn.Layer):def __init__(self):super(Mdrop,self).__init__()self.dropout_0 = nn.Dropout(p=0)self.dropout_1 = nn.Dropout(p=0.1)self.dropout_2 = nn.Dropout(p=0.2)self.dropout_3 = nn.Dropout(p=0.3)self.dropout_4 = nn.Dropout(p=0.4)self.dropout_5 = nn.Dropout(p=0.4)def forward(self,x):output_0 = self.dropout_0(x)output_1 = self.dropout_1(x)output_2 = self.dropout_2(x)output_3 = self.dropout_3(x)output_4 = self.dropout_4(x)output_5 = self.dropout_5(x)return [output_0,output_1,output_2,output_3,output_4,output_5]
class EmotionMDropErnieModel(ErniePretrainedModel):def __init__(self, ernie, num_classes=1, dropout=None):super().__init__()# 预训练模型self.ernie = ernieself.num_classes = num_classes# 设置mutlidropoutself.dropout = Mdrop()self.classifier = nn.Linear(self.ernie.config['hidden_size'],self.num_classes)self.apply(self.init_weights)def forward(self,input_ids,token_type_ids=None):sequence_output , _ = self.ernie(input_ids,token_type_ids=token_type_ids)sequence_output = sequence_output.mean(axis=1)sequence_output = self.dropout(sequence_output)# 将mutlidropout进行poolingsequence_output = paddle.mean(paddle.stack(sequence_output,axis=0),axis=0) logits = self.classifier(sequence_output)return logits # 不同嵌入策略的分类模型
class EmotionLayerModel(ErniePretrainedModel):def __init__(self, ernie, num_classes=1, dropout=None):super().__init__()# 预训练模型self.ernie = ernieself.num_classes = num_classesself.dropout = nn.Dropout(self.ernie.config['hidden_dropout_prob'])self.classifier = nn.Linear(self.ernie.config['hidden_size'],self.num_classes)self.dym_pool = nn.Linear(self.ernie.config['hidden_size'],1)self.apply(self.init_weights)def dym_pooling(self, avpooled_out, maxpooled_out):pooled_output = [avpooled_out, maxpooled_out]pool_logits = []for i, layer in enumerate(pooled_output):pool_logits.append(self.dym_pool(layer))pool_logits = paddle.concat(pool_logits, axis=-1)pool_dist = paddle.nn.functional.softmax(pool_logits)pooled_out = paddle.concat([paddle.unsqueeze(x, 2) for x in pooled_output], axis=2)pooled_out = paddle.unsqueeze(pooled_out, 1)pool_dist = paddle.unsqueeze(pool_dist, 2)pool_dist = paddle.unsqueeze(pool_dist, 1)pooled_output = paddle.matmul(pooled_out, pool_dist)pooled_output = paddle.squeeze(pooled_output)return pooled_outputdef forward(self,input_ids,token_type_ids=None):sequence_output , pooled_output = self.ernie(input_ids,token_type_ids=token_type_ids)# 选择嵌入策略if layer_mode == "mean":output = sequence_output.mean(axis=1)elif layer_mode == "max":output = sequence_output.max(axis=1)elif layer_mode == "dym":mean_output = sequence_output.mean(axis=1)max_output = sequence_output.max(axis=1)output = self.dym_pooling(mean_output,max_output)else:# 默认使用clsoutput = pooled_outputoutput = self.dropout(output) logits = self.classifier(output)return logits
# 改进后的模型
class EmotionModel(ErniePretrainedModel):def __init__(self, ernie, num_classes=1, dropout=None):super().__init__()# 预训练模型self.ernie = ernieself.num_classes = num_classesif enable_mdrop:self.dropout = Mdrop()else:self.dropout = nn.Dropout(self.ernie.config['hidden_dropout_prob'])self.classifier = nn.Linear(self.ernie.config['hidden_size'],self.num_classes)self.dym_pool = nn.Linear(self.ernie.config['hidden_size'],1)self.apply(self.init_weights)def dym_pooling(self, avpooled_out, maxpooled_out):pooled_output = [avpooled_out, maxpooled_out]pool_logits = []for i, layer in enumerate(pooled_output):pool_logits.append(self.dym_pool(layer))pool_logits = paddle.concat(pool_logits, axis=-1)pool_dist = paddle.nn.functional.softmax(pool_logits)pooled_out = paddle.concat([paddle.unsqueeze(x, 2) for x in pooled_output], axis=2)pooled_out = paddle.unsqueeze(pooled_out, 1)pool_dist = paddle.unsqueeze(pool_dist, 2)pool_dist = paddle.unsqueeze(pool_dist, 1)pooled_output = paddle.matmul(pooled_out, pool_dist)pooled_output = paddle.squeeze(pooled_output)return pooled_outputdef forward(self,input_ids,token_type_ids=None):sequence_output , pooled_output = self.ernie(input_ids,token_type_ids=token_type_ids)# 选择嵌入策略if layer_mode == "mean":output = sequence_output.mean(axis=1)elif layer_mode == "max":output = sequence_output.max(axis=1)elif layer_mode == "dym":mean_output = sequence_output.mean(axis=1)max_output = sequence_output.max(axis=1)output = self.dym_pooling(mean_output,max_output)else:# 默认使用clsoutput = pooled_output# 选择dropoutoutput = self.dropout(output)if enable_mdrop:output = paddle.mean(paddle.stack(output,axis=0),axis=0) # 下游任务logits = self.classifier(output)return logits
# 创建model
label_classes = train['label'].unique()
model = EmotionModel.from_pretrained(MODEL_NAME,num_classes=len(label_classes))
# 训练总步数
num_training_steps = len(train_data_loader) * epochs# 学习率衰减策略
lr_scheduler = paddlenlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps,warmup_proportion)decay_params = [p.name for n, p in model.named_parameters()if not any(nd in n for nd in ["bias", "norm"])
]# 定义优化器
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,parameters=model.parameters(),weight_decay=weight_decay,apply_decay_param_fun=lambda x: x in decay_params,grad_clip=paddle.nn.ClipGradByGlobalNorm(max_grad_norm))
# utils - 对抗训练 FGM
class FGM(object):"""Fast Gradient Method(FGM)针对 embedding 层梯度上升干扰的对抗训练方法"""def __init__(self, model, epsilon=1., emb_name='emb'):# emb_name 这个参数要换成你模型中embedding 的参数名self.model = modelself.epsilon = epsilonself.emb_name = emb_nameself.backup = {}def attack(self):for name, param in self.model.named_parameters():if not param.stop_gradient and self.emb_name in name: # 检验参数是否可训练及范围self.backup[name] = param.numpy() # 备份原有参数值grad_tensor = paddle.to_tensor(param.grad) # param.grad 是个 numpy 对象norm = paddle.norm(grad_tensor) # norm 化if norm != 0:r_at = self.epsilon * grad_tensor / normparam.add(r_at) # 在原有 embed 值上添加向上梯度干扰def restore(self):for name, param in self.model.named_parameters():if not param.stop_gradient and self.emb_name in name:assert name in self.backupparam.set_value(self.backup[name]) # 将原有 embed 参数还原self.backup = {}# 对抗训练
if enable_adversarial:adv = FGM(model=model,epsilon=1e-6,emb_name='word_embeddings')
# 验证部分
@paddle.no_grad()
def evaluation(model, data_loader):model.eval()real_s = []pred_s = []for batch in data_loader:input_ids, token_type_ids, labels = batchlogits = model(input_ids, token_type_ids)probs = F.softmax(logits,axis=1)pred_s.extend(probs.argmax(axis=1).numpy())real_s.extend(labels.reshape([-1]).numpy())score = accuracy_score(y_pred=pred_s,y_true=real_s)return score# 训练阶段
def do_train(model,data_loader):total_loss = 0.model_total_epochs = 0best_score = 0.9training_loss = 0# 训练print("train ...")train_time = time.time()valid_time = time.time()model.train()for epoch in range(0, epochs):preds,reals = [],[]for step, batch in enumerate(data_loader, start=1):input_ids, token_type_ids, labels = batchlogits = model(input_ids, token_type_ids)loss = F.softmax_with_cross_entropy(logits,labels).mean()probs = F.softmax(logits,axis=1)preds.extend(probs.argmax(axis=1))reals.extend(labels.reshape([-1]))loss.backward()# 对抗训练if enable_adversarial:adv.attack() # 在 embedding 上添加对抗扰动adv_logits = model(input_ids, token_type_ids)adv_loss = F.softmax_with_cross_entropy(adv_logits,labels).mean()adv_loss.backward() # 反向传播,并在正常的 grad 基础上,累加对抗训练的梯度adv.restore() # 恢复 embedding 参数total_loss += loss.numpy()optimizer.step()lr_scheduler.step()optimizer.clear_grad()model_total_epochs += 1if model_total_epochs % loggiing_print == 0:train_acc = accuracy_score(preds,reals)print("step: %d / %d, train acc: %.5f training loss: %.5f speed %.1f s" % (model_total_epochs, num_training_steps, train_acc, total_loss/model_total_epochs,(time.time() - train_time)))train_time = time.time()if model_total_epochs % loggiing_eval == 0:eval_score = evaluation(model, valid_data_loader)print("validation speed %.2f s" % (time.time() - valid_time))valid_time = time.time()if best_score < eval_score:print("eval acc: %.5f acc update %.5f ---> %.5f " % (eval_score,best_score,eval_score))best_score = eval_score# 保存模型os.makedirs(save_dir_curr,exist_ok=True)save_param_path = os.path.join(save_dir_curr, 'model_best.pdparams')paddle.save(model.state_dict(), save_param_path)# 保存tokenizertokenizer.save_pretrained(save_dir_curr)else:print("eval acc: %.5f but best acc %.5f " % (eval_score,best_score))model.train()return best_score
# 相同方式构造测试集
test_ds = load_dataset(read,df=test, istrain=False, lazy=False)test_trans_func = partial(convert_example,tokenizer=tokenizer,mode='test',max_seq_len=max_seq_length)test_ds.map(test_trans_func, lazy=False)test_batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=test_batch_size, shuffle=False)test_batchify_fn = lambda samples, fn = Dict({"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id), "token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
}): fn(samples)test_data_loader = paddle.io.DataLoader(dataset=test_ds,batch_sampler=test_batch_sampler,collate_fn=test_batchify_fn,return_list=True)# 预测阶段
def do_sample_predict(model,data_loader):model.eval()preds = []for batch in data_loader:input_ids, token_type_ids= batchlogits = model(input_ids, token_type_ids)probs = F.softmax(logits,axis=1)preds.extend(probs.argmax(axis=1).numpy())return preds# 读取最佳模型
state_dict = paddle.load(os.path.join(save_dir_curr,'model_best.pdparams'))
model.load_dict(state_dict)# 预测
print("predict start ...")
pred_score = do_sample_predict(model,test_data_loader)
print("predict end ...")
sumbit = pd.DataFrame([],columns=['label'])
sumbit["label"] = pred_score
sumbit_path = os.path.join(data_path,"prediction_result/result.csv")
sumbit.to_csv(sumbit_path,index=False)
5.比赛结果
最终排名第9名,完整代码。