Main Concepts
一些服务器形成了存储层,被称为broker,其他服务器运行kafka连接去不断地导入和导出数据作为事件流,将kafka和关系型数据库等存在的系统集成。
Servers: Kafka is run as a cluster of one or more servers that can span multiple datacenters or cloud regions. Some of these servers form the storage layer, called the brokers. Other servers run Kafka Connect to continuously import and export data as event streams to integrate Kafka with your existing systems such as relational databases as well as other Kafka clusters. To let you implement mission-critical use cases, a Kafka cluster is highly scalable and fault-tolerant: if any of its servers fails, the other servers will take over their work to ensure continuous operations without any data loss.
KAFKA中的数据称为event。
An event records the fact that “something happened” in the world or in your business. It is also called record or message in the documentation. When you read or write data to Kafka, you do this in the form of events. Conceptually, an event has a key, value, timestamp, and optional metadata headers.
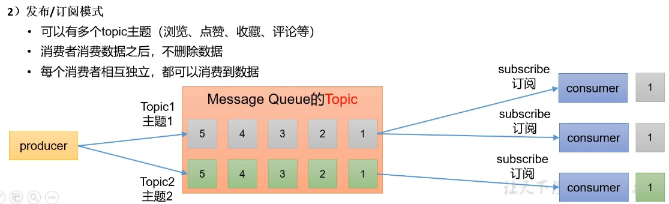
Producers are those client applications that publish (write) events to Kafka, and consumers are those that subscribe to (read and process) these events.
In Kafka, producers and consumers are fully decoupled and agnostic of each other, which is a key design element to achieve the high scalability that Kafka is known for.
For example, producers never need to wait for consumers. Kafka provides various guarantees such as the ability to process events exactly-once.
events被有组织地持久化存储在topic中,topic类似于文件夹,event类似于文件夹中的文件。
These events are organized and stored in topics. Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder.
Events are organized and durably stored in topics. Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder. An example topic name could be “payments”. Topics in Kafka are always multi-producer and multi-subscriber: a topic can have zero, one, or many producers that write events to it, as well as zero, one, or many consumers that subscribe to these events. Events in a topic can be read as often as needed—unlike traditional messaging systems, events are not deleted after consumption. Instead, you define for how long Kafka should retain your events through a per-topic configuration setting, after which old events will be discarded. Kafka’s performance is effectively constant with respect to data size, so storing data for a long time is perfectly fine.
一个topic的跨度是多个broker节点(比如一个文件夹中的东西放在多个机器上)。
Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers. This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time. When a new event is published to a topic, it is actually appended to one of the topic’s partitions. Events with the same event key (e.g., a customer or vehicle ID) are written to the same partition, and Kafka guarantees that any consumer of a given topic-partition will always read that partition’s events in exactly the same order as they were written.
为了容错性和高可靠,每个topic都可被复制。
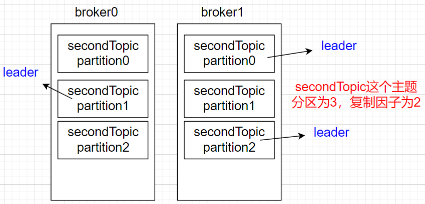
To make your data fault-tolerant and highly-available, every topic can be replicated, even across geo-regions or datacenters, so that there are always multiple brokers that have a copy of the data just in case things go wrong, you want to do maintenance on the brokers, and so on. A common production setting is a replication factor of 3, i.e., there will always be three copies of your data. This replication is performed at the level of topic-partitions.
# 启动zookeeper
docker pull zookeeper
docker run -d --restart=always --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper# 下载安装kafka
curl -O https://mirrors.aliyun.com/apache/kafka/3.3.1/kafka_2.12-3.3.1.tgz
tar -zxvf kafka_2.12-3.3.1.tgz -C /usr/local/src
vim /usr/local/src/kafka_2.12-3.3.1/config/server.properties
# 修改三处
# broker.id // 唯一
# zookeeper.connect=kafka100:2181,kafka200:2181/kafka
# log.dirs=/root/kafka-logs
vim /etc/profile # 配置kafka环境变量# 启动(启动之前需先启动zookeeper)
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
# 看是否启动成功
jps
# 列出已有topic
kafka-topics.sh --bootstrap-server kafka100:9092 --list
# 创建topic,名字为fistTopic,分区为1,复制因子为2(分区数量可以大于broker节点数量, 复制因子不能大于broker节点数量)
kafka-topics.sh --bootstrap-server kafka100:9092 --topic fistTopic --create --partitions 1 --replication-factor 2
kafka-topics.sh --bootstrap-server kafka100:9092 --topic secondTopic --create --partitions 3 --replication-factor 2
# 关闭kafka
kafka-server-stop.sh

# 向firstTopic主题写入数据
kafka-console-producer.sh --bootstrap-server kafka100:9092 --topic firstTopic
# 消费firstTopic主题的数据
kafka-console-consumer.sh --bootstrap-server kafka100:9092 --topic firstTopic
# 删除fistTopic主题
kafka-topics.sh --bootstrap-server kafka100:9092 --topic fistTopic --delete