在传统的应用场景中,服务器资源过剩情况普遍,为了充分利用服务器资源,产生了虚拟化技术。虚拟化技术以牺牲部分效率为代价提升了资源的使用率,将原来需要硬件完成的工作,通过软件模拟的方式,满足多个云租户的需要。随着5G、8K等新型业务的不断涌现,应用系统对性能提出了更高的要求,云服务也出现了满足不同QoS要求的分化,有(物理机、裸金属)等不同产品形态。各个功能模块的衔接配合,各租户之间的信息交互都需要高效的网络系统来实现。
网络虚拟化
传统数据中心的服务器使用硬件网卡收发包,硬件网卡连接硬件交换机完成跨服务器的通信。硬件场景下,主机发送数据包时:应用程序将数据写入内核分配的内存中,硬件网卡通过DMA将要发的数据从内存搬运到物理网卡的队列中。
主机接收数据包时:硬件网卡收到数据包时按照CPU分配的硬件网卡内存地址,通过DMA功能把数据包写入对应内存中,然后中断CPU进行后续处理。硬件交换机通过MAC进行二层转发。
在云计算场景下,对计算资源进行了切分,物理服务器上运行多个虚拟机,虚拟机之间通过虚拟网卡实现互通,虚拟网卡连接到虚拟交换机上,实现同一个服务器内不同虚拟机之间以及不同服务器上虚拟机之间的流量转发。
网卡的虚拟化
虚拟网卡模拟硬件网卡,工作机制类同。虚拟网卡包括e1000,virtio等实现技术。virtio是目前最为通用的技术框架。virtio提供了虚拟机和物理服务器数据交换的通用机制,得到了大多数hypervisor的支持,成为事实上的标准。
virtio是一种半虚拟化的解决方案。半虚拟化方案中,Guest OS知道自己是虚拟机,通过前端驱动和后端模拟设备互相配合实现IO虚拟化。这种方式与全虚拟化相比,可以大幅度提高虚拟机的IO性能。virtio分为四层,包括guest OS中各种前端驱动模块,hypervisor上的后端驱动模块,中间两层包括前后端通信的virtio层和virtio-ring层。其中,virtio层是虚拟队列接口,负责前后端之间的通知机制(kick,notify)和控制流程。virtio-ring实现了两个环形虚拟队列,分别用于保存前端驱动程序和后端处理程序执行的信息。
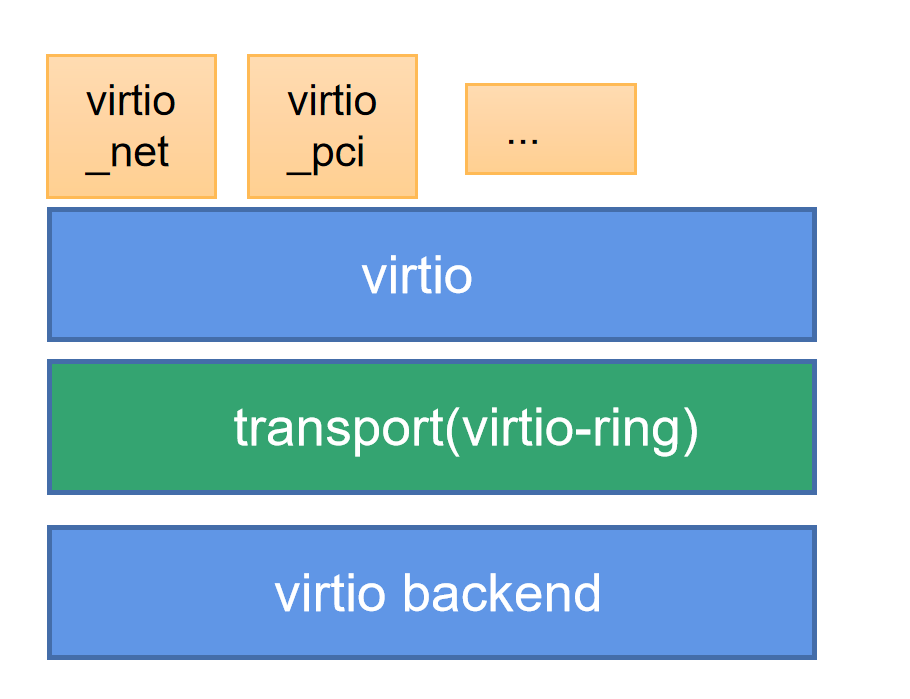
图1:virtio架构
virtio-ring是virtio的核心,包括三个部分:描述符数组desc,可用的available ring和使用过的used ring。
Desc:用于存储一些关联的描述符。
Available ring:用于guest端表示当前有哪些描述符是可用的。
Used ring:表示host端哪些描述符已经被使用。
virtio的通信过程
在virtio的通用化实现方式中,有两个非常重要的模块:KVM和QEMU。KVM是linux内核提供的虚拟化架构,可将内核直接充当hypervisor使用。KVM负责CPU虚拟化和内存虚拟化,但是不能模拟其他设备。QEMU模拟IO设备(包括网卡),运行在用户空间。
在virtio的实现框架中,当guest发送数据时,通过函数virtqueue_add_buf将数据buffer添加到virtqueue中(向desc结构指向的buffer中填充数据,并更新available ring),然后调用virtqueue_kick函数,发出EPT violation/misconfig(类似于page fault),形成vm-exit,由host上的kvm内核模块负责后续处理,kvm调用virtqueue_notify函数通知用户态QEMU,通过写入寄存器的方式通知host,host调用virtqueue_get_buf来获取virtqueue中收到的数据(从desc指向的buffer中找到available ring中添加的buffer,并更新used ring)。
在接收网络数据包时,virtio_queue-notify调用virtio-net网络设备注册的数据包接收函数virtio_net_handle_rx,QEMU会把数据复制到对应的队列中,之后再调用qemu_notify_event通知virtio前端,最终通过kvm_set_irq触发vCPU中断以通知virtio前端。
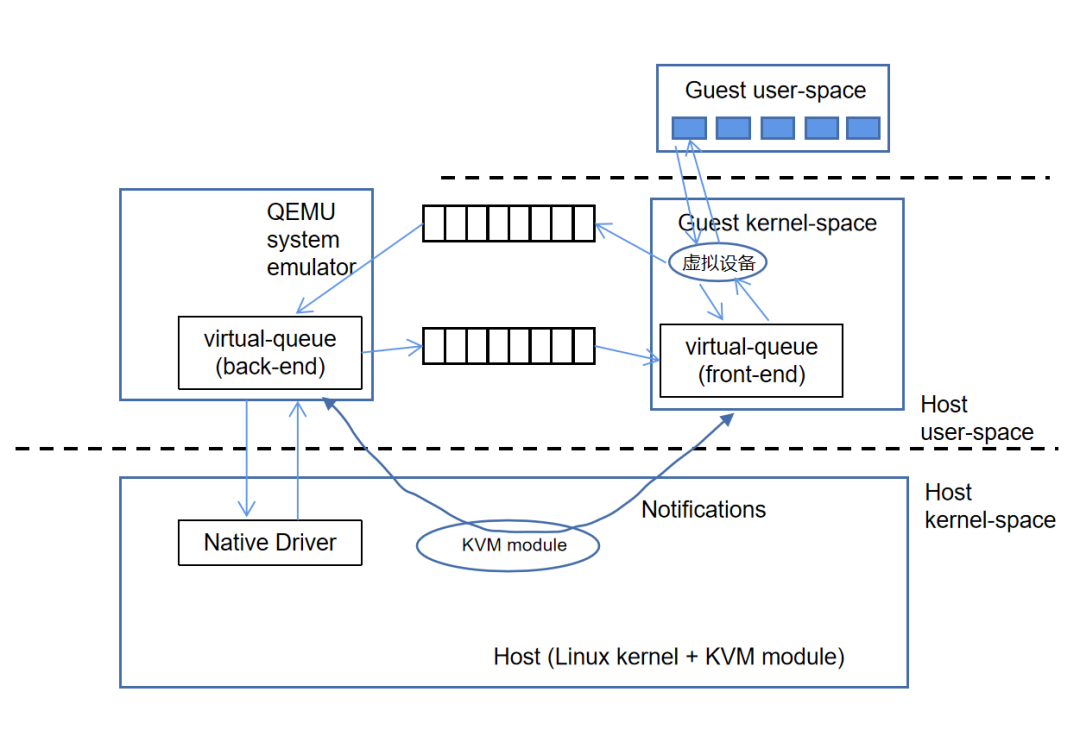
图2:virtio通信过程
virtio的内核态卸载
最初的virtio的通信机制中,guest与用户空间的hypervisor通信,会有多次数据拷贝和CPU特权级的切换。Guest发包给外网络,guest要切换到内核的KVM,然后KVM通知用户空间的QEMU处理guest请求。这种方式通信效率不高。在virtio的后续演进中出现了vhost-net。
Vhost-net是virtio的一种后端实现方案。Vhost-net实现在内核中,是内核的一个模块vhost-net.ko。Vhost与guest直接通信,旁路了KVM和QEMU。Guest和host kernel之间的数据通道通过virtqueue进行,QEMU不参与数据通道,主要负责virtio控制平面。
Vhost与virtio前端的通信通过事件驱动机制来实现。Vhost初始化后会启动一个工作线程监听enventfd,当guest发出kick event后,kvm.ko触发ioeventfd到vhost,vhost通过virtqueue的available ring 获取数据,并设置used ring。当vhost工作线程向guest通信时触发回调call envent,通过kvm.ko触发irqfd通知guest。
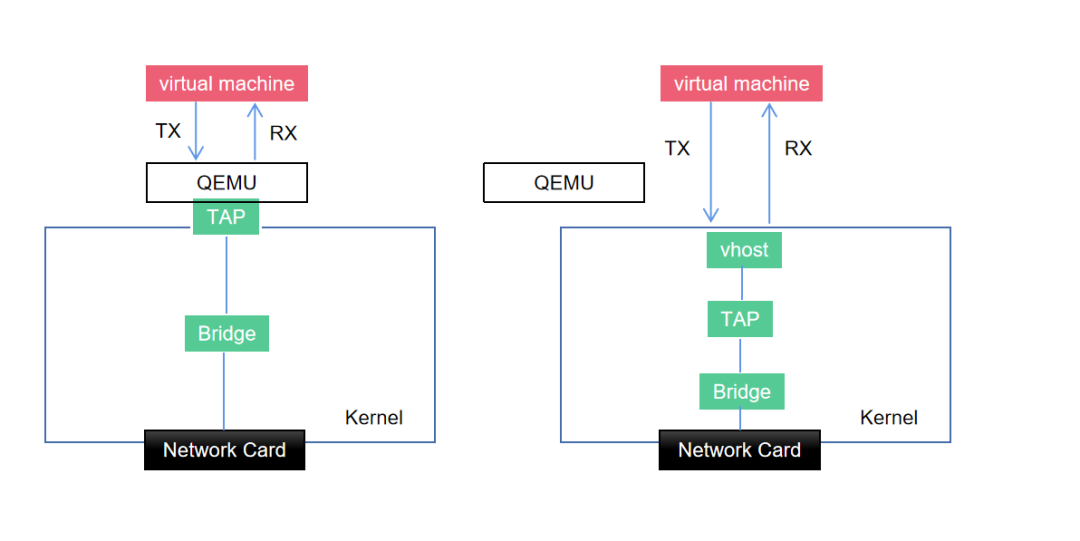
图3:virtio的内核态卸载
在单次收发的过程中,数据通道减少了两次用户态与内核态的上下文切换过程。实现了数据通道在内核态的卸载。Vhost-net作为virtio的backend,与虚拟机内部的virtio NIC通过共享内存方式通信。
virtio的DPDK卸载
基于vhost协议,DPDK设计了一套新的用户态协议——vhost-user。该协议将网络包处理(数据平面)卸载到DPDK应用中。控制平面仍然由QEMU来配置Vhost-user。
控制平面要做的事情包括:
1、特性协商:virtio的特性与后端特性通过一定的方式协商(vhost通过ioctl实现,vhost-user通过unix socket实现)。
2、内存区域配置:QEMU配置好内存映射区域,vhost-user使用mmap接口映射。
3、Vring配置:QEMU将Virtqueue的个数与地址发送给vhost(后端)。
4、通知配置:通过eventfd实现前后端通知。
DPDK优化实现了处理器的亲和性、巨页的使用、轮询模式驱动等。
virtio的半硬件卸载
virtio设备虚拟化的功能一直都是由软件来实现,在Host上因虚拟化而产生的额外开销无法避免。为了提升云端服务的性能,可以将virtio功能offload,将与业务无关的任务绕开系统、CPU直接交给专用硬件执行。
vDPA(硬件) 是virtio的半硬件虚拟化实现。该框架由Redhat提出,实现了virtio数据平面的硬件卸载。控制平面仍然采用原来的控制平面协议,当控制信息被传递到硬件中,硬件完成数据平面的配置之后,数据通信过程由硬件设备(智能网卡)完成,虚拟机与网卡之间直通。中断信息也由网卡直接发送至虚拟机不需要主机的干预。这种方式,控制面比较复杂,硬件难以实现。
在硬件vDPA架构中,通过OVS转发的流量首包依然由主机上的OVS转发平面处理,对应数据流的后续报文由硬件网卡直接转发。
在性能方面能够接近SR-IOV设备直通的数据平面。同时,能够保持virtio标准接口,保持云服务的兼容性。
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !
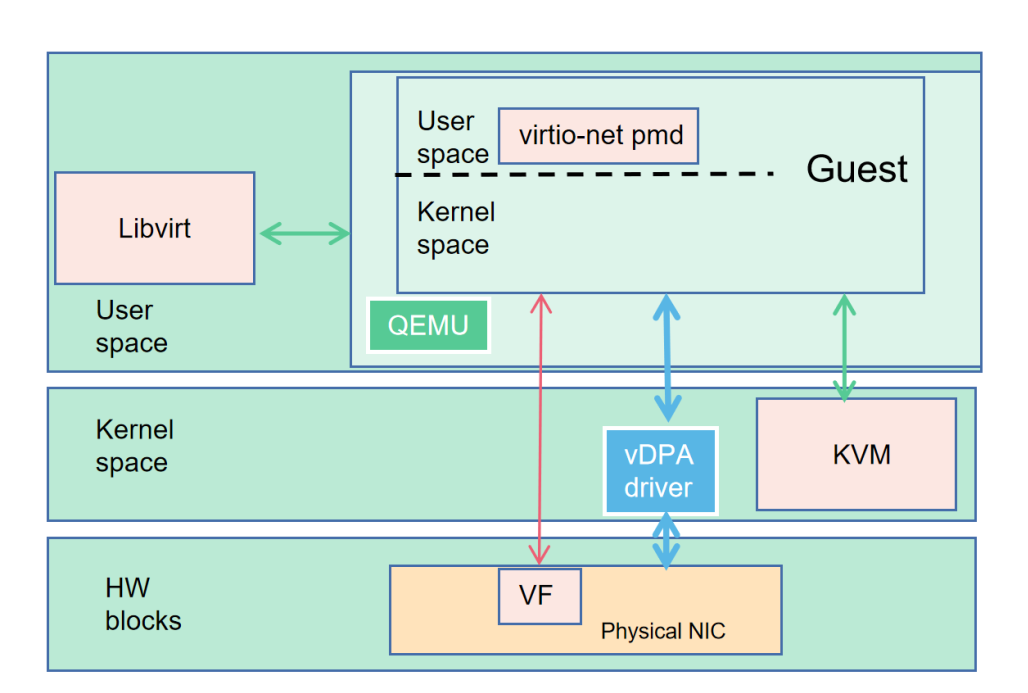
图4:virtio的半硬件卸载
网络虚拟化技术发展
随着业务对网络性能要求越来越高,能够满足更高性能要求的SR-IOV技术出现了。SR-IOV技术通过对物理网卡实现资源分割,实现了应用与物理网卡的独占,从而大幅度提升了通信效率。
SR-IOV技术最初应用在网卡上。SR-IOV将一个物理网卡虚拟出多个轻量化的PCI物理设备,从而分配给虚拟机使用;同时,在虚拟机/容器和网卡硬件之间提供了一个直接接口,绕过主机CPU和操作系统,将宝贵的CPU资源从I/O任务中释放出来。
但是SR-IOV存在一些问题包括无法实时迁移,需要在客户操作系统上安装网络驱动程序。这些问题阻碍了SR-IOV在云部署中的应用。通常情况下,以性能为中心的应用程序利用SR-IOV加速,数据密集程度较低的应用使用virtio接口或者硬件vDPA。
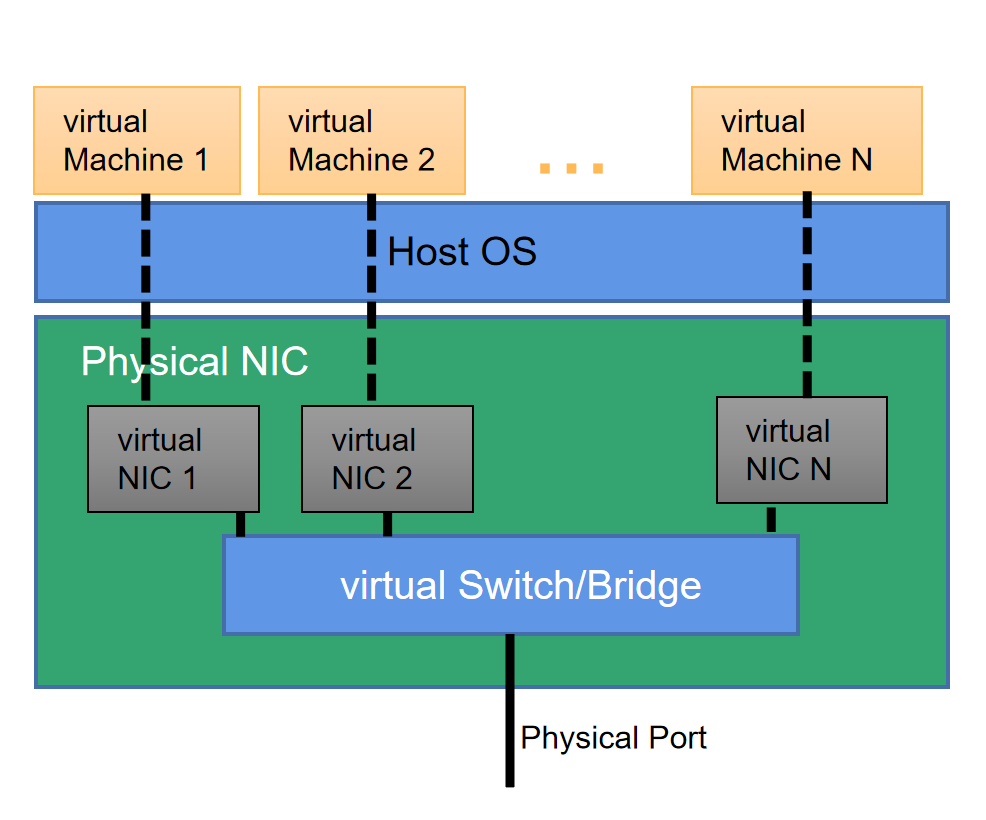
图5:SR-IOV示意图
virtio的DPU卸载
越来越多的硬件厂商开始原生支持virtio协议,将虚拟化功能Offload到硬件上,把嵌入式CPU集成到SmartNIC中,网卡处理所有网络中的数据,而嵌入式CPU控制路径的初始化并处理异常情况。这种具有Offload的SmartNIC则称为DPU,专门处理数据中心内的各种计算机和存储之间的数据移动和处理。
NVIDIA加速交换和数据包处理技术ASAP2实现了SR-IOV与virtio的融合。virtio-net网卡由DPU上服务virtio-net-controller模拟。
ASAP2的核心是eSwitch。eSwitch是嵌入式交换ASIC,可以提供裸金属服务器网络性能和效率,同时能够提供SD灵活性。DPU通过eSwitch在硬件中完成大部分数据包处理操作,释放主机CPU,提供更高的网络吞吐量。eSwitch处理所有进出服务器的流量,同时也处理VM或容器之间的流量。
小 结
根据NVIDIA的白皮书,基于内核的网络虚拟化能够提供的峰值吞吐率为200Kpps,DPDK 轮询模式能够提供的峰值吞吐率为7.5Mpps(以消耗2个物理核为代价),DPU全卸载模式能够提供的峰值吞吐率为66Mpps。硬件卸载的方式实现的网络虚拟化,性能有跨越式提升。
回归本质,网络虚拟化是为了提升资源使用率,丰富资源的功能性,单纯的虚拟化对CPU占用较大,同时会对性能产生较大的影响。随着DPU的出现,网络虚拟化可以offload到DPU中,实现网络功能的卸载,在提升效率的同时,减轻对CPU的占用。此种方式以增加额外硬件为代价。成本、性能始终是把双刃剑,在具体的应用场景中才会有最优解。
参考资料:
https://www.cnblogs.com/bakari/p/8341133.html
https://zhuanlan.zhihu.com/p/379681768
https://cloud.tencent.com/developer/article/1540284
https://www.cnblogs.com/bakari/p/8309638.html
https://www.cnblogs.com/bakari/p/7858029.html
NVIDIA 白皮书《Comparision of OVS vRouter Acceleration Techniques:SR-IOV vs. Virtio》
原文链接:https://cloud.tencent.com/developer/article/1902466