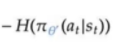A2C是一个很好的policy-based框架,是一种on-policy算法。但是由于其Critic部分是一个输入信号连续的nn,有神经网络基础的应该知道,这样的网络是学不到东西的。根据A2C中Actor的更新公式,既然Advantage Function估计不准确,那么Actor中 θ \theta θ的更新就更糟糕了。换句话说,由于输入相关性太大,导致Critic网络收敛不稳定,进而导致A2C算法收敛效果差。
因此,接下去就得想办法打破输入的相关性。故A2C之后,存在2大方向,一个是DDPG,采用经验回放池打破相关性,另一个是A3C,采用异步执行多个Actor来打破相关性。
A3C的显著优势如下:
①:打破相关性来使nn学到到东西。
②:相比较于经验回放池,异步框架算法有利于节约资源。
③:异步框架下使得on-policy算法也可以用nn来训练。
④:采用多核的CPU可以实现比GPU更快的收敛速度。
以上就是我去学习A3C论文的原因。
Asynchronous Methods for Deep Reinforcement Learning
Abstract
- 作者提出了四种标准的强化学习算法的异步变体算法。也就是说在2种经典的TD(0)算法Sarsa、Q-learning、以及n-step Q-learning算法、A2C算法中加入异步思想从而在nn的训练上有稳定的表现。
- 作者着重强调了Asynchronous在A2C上的优越表现,仅仅只需要在一块多核的CPU上实现A3C,就可节省在GPU上一半的时间。
- A3C算法可以成功的在许多连续动作空间的游戏中运行。
1、Introduction
作者间接提出了对于A2C这种on-policy算法(或者叫在线online算法),其输入相关性太大,导致神经网络的训练不稳定,因此之前普遍认为on-policy的RL算法不适合于神经网络结合在一起,比如DQN,就是将off-policy的代表Q-learning和神经网络结合在一起,为啥不是Sarsa呢?因为Sarsa是on-policy算法,他无法做到和Q-learning一样,可以学习过去的现在的、不同策略的经验,效率很高。Sarsa的目标策略和行为策略是同一个,意味下一个step执行的动作同时来自于网络训练TD error中的动作a’,比如我们在DQN中选择a’是这么做的:
Q_target = reward_1 + gamma * np.max(self.target_Q(states_1), axis=1) * (~ is_done)
Sarsa使用的 ϵ − g r e e d y \epsilon-greedy ϵ−greedy也是一样的操作,那么一旦你采样的states_1是不好的状态,那么这次训练更新就会出问题。而Q-learning的两个策略是不一样的,训练归训练,探索归探索,因此这就要求网络的训练就不能是minibatch格式了,只能是单样本更新。因此,问题就出现了,单样本不能是从经验池里抽取,因为经验池里有不好的样本,万一抽到不好的,那么对Q-learning倒没事,而Sarsa的容错率很小,这点在悬崖寻路中分析过,万一目标策略选中的动作是不好的动作,那么就会导致错误的收敛结果。因此单样本只能是输入样本,但这种做法使得输入端相关性太强,使得网络训练不稳定。这也体现了off-policy的3个优点:
- 学习效率高,速度快,啥经验都能学,节省探索时间。
- 经验利用率高,Sarsa的经历是即学即用,而Q-learning可结合nn对同一个经验重复学习多次。
- on-policy算法由于行为策略和目标策略是同一个策略,因此在选择动作的时候需要谨慎,容错率低,比如最明显的就是无法结合nn(在不讨论本论文的情况下)。而Q-learning由于双策略分开,目标策略对动作的选取和行为策略执行的动作是独立的,而且其目标策略是最优策略(贪心策略),即其总能向着最佳的方向优化。
对于打破相关性,以往都是采用Experience Reply来解决的,但是这种方式带来了2个缺陷:
限制了算法只能基于Off-policy。需要消耗一定的存储空间和计算资源。
因此本文旨在打破相关性的同时,又可以避免上述2个缺陷:通过异步并行执行多个Actor从不同的环境中(指同一个环境的不同observation)进行on-policy或者off-policy学习,打破输入网络输入相关性且不需消耗大量存储资源。
除此之外呢,作者还指出了咋们异步算法的另一个好处,在以往训练nn的时候,我们都会选择GPU,因为CUDA可以加速张量的运算速度。但是作者提出的异步算法却可以在多核的CPU上运行,且速度远小于基于GPU的那些算法(这里应该指用了经验回放池的nn算法)。
2、Related Work
这里是讲历史了,略。
3、Reforcement Learning Background
前面的都是一些背景知识,该段后面讲述了DQN算法的一个缺陷,DQN是基于Q-learning的,Q-learning是TD(0)算法,其千辛万苦交流来的奖励r只能去更新一个Q(s,a)。而后面更新的Q只能等待当前Q被更新之后。这种单步更新的方式很没有效率,学习较慢。一个更为有效率的做法就是,采用TD( λ \lambda λ)。
接下来作者介绍了下A2C算法。
4、Asynchronous RL Framework
开始进入正题了。
通过设计异步的四种算法为训练nn而节约所需存储资源,并且不像DQN,DDPG训练网络一样需要off-policy算法,本论文提出的算法也可用于on-policy算法,如Sarsa、A2C。
本算法基于CPU的多线程处理,每个线程下是一个独立的Agent,这种处理方式使得整个算法的每个Agent都在使用不同的策略在探索不同的环境。

上图是异步Q-learning算法的伪代码。从算法中我们可以看出:
- 这只是单个Agent的算法,异步算法的强大在于多个Agent同时在进行和环境交流、训练网络。
- 每个Agent都在独立工作,边探索边累计梯度,而不忙着立马更新,这里区别于online算法的及时更新,最后到时间了,或者某个Agent率先完成了,就立马更新主网络参数。
- 从算法整体来看,主Agent相当于一个坐在家里坐等收钱的老板,那些子Agent拿着老板给的钱出去招兵买马,做各种不同的生意,最后年底了就把钱全部上缴给老板。
- 从伪代码看出,异步的作用相当于顶替了DQN中经验回放池的作用,
节省了大量的存储资源,另外Target网络仍然存在, - 从子Agent角度看,每个Agent都是
独立的,由于探索策略的随机性使得每个Agent都在探索不同的环境。当某个Agent在使用过 θ 1 \theta_1 θ1之后,可能下个step用来探索的 θ \theta θ就变成了 θ 2 \theta_2 θ2了,因为参数可能已经被另一个Agent更新掉了。因此由于各个子Agent在时间上的错位,使得我每个子Agent用来更新网络的经验来自于不同的策略,在时间上是不相关的,从而达到了减弱相关性的作用。 - 从主Agent角度看,由于每个子Agent探索策略的不同,经历的环境也不同,故他们完成的情况也不同,这种时间上的错位,使得主Agent几乎每时每刻都在更新参数,或者说更新的很频繁。
个人认为,这和DQN利用经验训练网络不一样,DQN抓取经验是按uniform来提取minibatch个trans,其中会有初级策略的trans,也会有比较后面的、好的策略形成的trans。但是异步算法用来训练网络的trans是越来越好的策略通过行为策略获得的,每个Agent都在利用越来越好的策略形成的经验去累计梯度。看似每个Agent是独立的,但是他们又是通过主Agent的参数 θ \theta θ为桥梁,相互帮助,互相依次给其他Agent做垫脚石,齐心协力往上冲,直到收敛。因此,各个子Agent是互相独立,互相帮助的。 - 总结一下,异步算法的核心思想:
通过异步执行各个并行的Agent来减弱nn输入的相关性,从而使得网络能学到东西。
接下来作者指出了异步算法在实战中的优势:
- 利用异步算法在时间上的减少粗略与子Agent个数呈线性关系。
- 由于可以不再使用经验回放池,所以我们可以在on-policy算法,比如Sarsa、Actor-Critc中训练nn。
接下来就是文章的核心内容:介绍四种RL经典算法:one-step Sarsa、one-step Q-learning、n-step Q-learning、A2C结合异步思想后形成的Asynchronous RL Framework。
Asynchronous one-step Q-learning
Asyn Q-learning算法的伪代码如上所示,基本上的分析如上,这里补充2点:
- 异步算法的加入是为了打破相关性,因此Target网络 θ − \theta^- θ−仍然需要。
- 梯度经过累积,然后 ∗ I A s y n c U p d a t e ∗ *I_{AsyncUpdate}* ∗IAsyncUpdate∗或者终止状态到来后再更新,这就类似于
minibatch的效果,在收敛稳定性和收敛速度上都能取得不错的效果。不仅如此,这样的做法减少经验多样性的损失,想象一下,如果几个子Agent每过一个step就更新一次主Agent的参数,那么就会导致许多子Agent的更新结果会被覆盖,这样直接导致了参数 θ \theta θ多样性下降,从而使经验多样性下降,而我们知道输入的多样性间接提升了探索能力,因此minibatch的处理方式很适合Asyn算法。这个思想在后面三个算法中都会用到。 - 作者还从另一方面赞扬了Asyn算法的多样性(diversity):由于每个子Agent拥有不同的行为策略,因此探索能力强,使得算法更加鲁棒。
Asynchronous one-step Sarsa

one-step的Asyn Sarsa算法和上述Asyn Q-learning算法大致相同,除了y的赋值不同之外,这是Sarsa与Q-learning本身原因造成的。
Asynchronous n-step Q-learning

Asyn n-step Q-learning算法如上所示:
- 作者采用前向TD算法,而非反向TD,作者给出的理由是,前向TD更容易用来训练网络。
- 用 t m a x t_{max} tmax来表示往前看的步数,同时也是每个子Agent的minibatch的大小。不同于one-step算法,n-step算法梯度累积的是一路经历过的状态对和距离起始点往后看 t m a x t_{max} tmax步的那个终止点之间的MSE。
Asynchronous A2C

A3C算法是Asyn+A2C:
- 首先不同于一般的A2C,评估点基于单步TD的 δ \delta δ(A2C理论上是优势函数A,但在实现上基于TD error的评估点),A3C采用上述n-step思想,使用
n-step的TD error作为评估点。 - 使用共享的网络参数,也就是说,将策略网络和Critic网络除输出端不同之外,前面部分网络
共享,比如策略网络输出端用softmax层输出离散动作,Critic网络输出端为FC层输出V估计值。 - 作者发现在Actor的目标函数后再加一项
熵的正则化项,类似于L2正则化项,使得算法可以通过阻止算法过早收敛至次优策略来提升探索性。 - 参考了Morvan的代码,找出了该正则化项的具体写法如下:

变量entropy就是熵H,输入是状态 s 1 s_1 s1下动作a的概率。
关于熵的计算公式,可参考熵的计算公式
Optimization
作者通过比对三种不同的优化方式:Momentum SGD、RMSProp、Shared-RMSProp在四种不同的游戏中使用A3C和n-step Q-learning算法,最后得出了Shared-RMSProp是最佳的优化方法。
RMSProp算法更新方式:
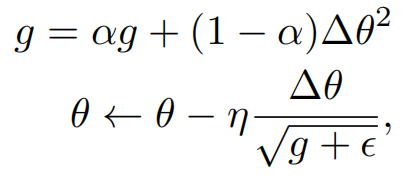
我们可以用Pytorch或者Tf轻松使用出来这个优化器。这里的g是statistics,如果这个g在各个子Agent共用的话,那么RMSProp就叫做Shared-RMSProp,反之,若每个子Agent都有一个单独的g,那么就记为RMSProp。
作者给出的实验:
在四种不同游戏中分别使用A3C和n-step Q-learning算法对三种优化器进行实验,一共进行50次实验,每次实验的学习率和初始条件都是随机的。实验结果如下:

其中,
- 横轴是50次实验的50个model按Agent所获得的游戏分数按降序排列。纵轴是Agent打游戏获得最终的分数。
- 作者使用两个指标,一个是纵轴,即最大累计奖励,也就是我们RL任务的目标;另一个是曲线围成的面积,用于判定算法的鲁棒性。
- 从图中可以看出,Shared RMSProp优化的Agent能获得最高的奖励,且使得Agent变得非常鲁棒,因此作者得出了Shared-RMSProp是一个不错的优化器。
- Shared-RMSProp优化器还有一个好处是,共享的g可以使得每个线程都少使用一个参数向量,节约了存储资源。
5、Experiments
目前以研究算法为主,实战部分略。
6、Conclusions and Discussion
总结如下:
- 异步算法通过打破输入相关性使得nn的训练更加稳定,并且能节约一定的存储资源。
- 异步框架既可以适用于value-based、policy-based方法;适用于on-policy、off-policy算法;也适用于离散动作空间、连续动作空间RL任务。
- 异步算法的多核CPU比用GPU训练DQN更快。
- 进一步的,异步框架还可以结合反向TD。
7、Note
另外,正文中只有one-step Q-learning的伪代码,其余的伪代码在Supplementary补充材料中。补充材料一般都在出版社的官网或者在正文之后,该篇的补充材料在正文之后。这篇炉论文,网上有的地方给出的是没有补充材料的,建议直接去DeepMind的官网下载。本文是基于CPU的异步算法,后续已经出了GPU版的异步算法,显然速度会进一步提升。