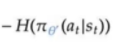联想下我们之前是怎么算的,
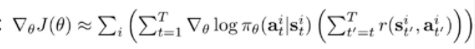
然后由此构建奖励函数
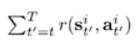
又因为这个过程存在着太多的随机性
故我们引入baseline对其进行微调
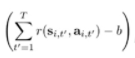
并且使用
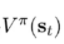
来估计偏置值b
再回想下函数Q
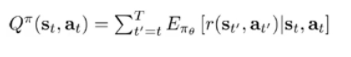
优势函数
函数表达式
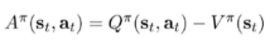
就是在某状态state下,衡量选择某一动作有多好,Q相当于我们得到的结果,V是我们的期望(平均的估计值,根据大数定律,用平均去估计一组数的值是有数学依据的)
这个东西联想导数里面而的一阶损失函数,二阶损失函数,如果A是正的就说明效果不错,方向是很合理的
解读与分析
AC算法要解决的问题
先把之前的算法涉及打分公式给展示下

如果按照这个公式来的话就是要多进程并行计算两个神经网络对电脑的计算负担非常地大,
那么为了计算A,我就要计算Q和V两个网络了,我们将公式换个写法
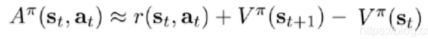
这样写地好处就是只要训练V一个网络了
AC算法地整体计算流程
1获取数据:
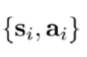
通过策略函数不断地与环境交互得到这些数据,具体地公式表现为
2前向传播的计算
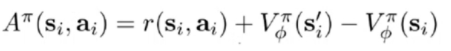
3梯度计算
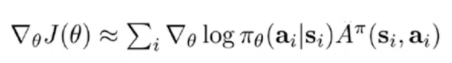
4更新参数
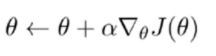
这个可不是训练两个网络,是将该网络同时连接两个全连接层

用于分别计算其对应的目标函数
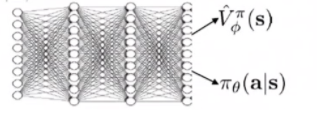
简单来说就是在同一个网络中嫁接两个全连接层借此减少计算负担
同时·我们要让它进行多步计算,而不是只计算一步
故公式为
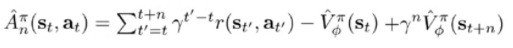
在公式中还引入了折扣系数。降低其对后续选择的影响(联想K近邻,越近越准)
整体架构.


实际上用多进程去做就行
损失函数整理
策略损失函数
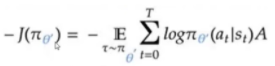
价值网络的损失
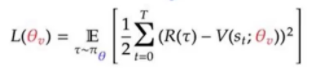
整体损失函数
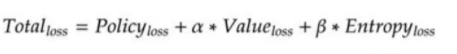
熵