背景
公司研发了一个系统——基于客户交易行为,利用算法得出各个用户的各式各样的特征,暂且称之为“标签”。这些“标签”是利用大数据平台计算而得的结果。计算得到的近三四百个“标签“数据会会落到中台N张表中。操作员,在管理平台,能够通过特定”标签“获取某类满足此”标签“的用户,或者搜索某个用户的账户,查询该用户的”标签“。
在测试过程中,没有数据是一个很苦恼的事情。手工插入数据,三四百个字段,插入十条后,人也瘫了。于是想:可否用一个脚本实现。
分析
分析下功能:
1、上述两个场景中,不管是查满足某”标签“的用户还是查某用户的”标签“都是通过条件去数据库取数据即可,不需要对数据进行处理(在大数据层已经处理好了)。那么,数据间不存在业务逻辑。
2、如何确定插入数据的值?可这么处理:通过desc table 来获取该表的各个字段,以及字段类型,字段长度。根据这些信息,可造符合条件的数据。
实现
上面确认了可行性。接下来就是实现了。
创建一个Generate_Data类,写一个方法,获取表字段相关信息。如下:
class Generate_Data:def get_cols(self,table):"""获取表字段名、字段类型"""sql = "desc " + tablecur.execute(sql)result = cur.fetchall()return result
在sql中结果是:
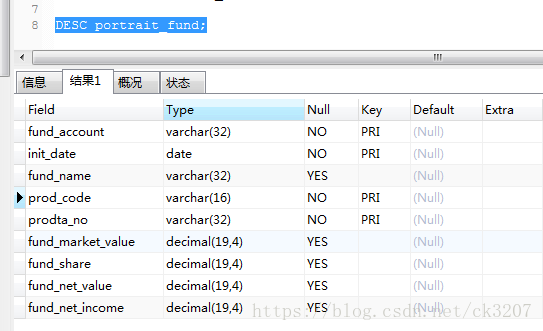
获取到数据后,解析上述type列的字段,得到字段类型,字段长度(像date就没有字段长度标识)。比如解析上述 fund_acccount 得到类型:varchar,长度:32。对于数值型的数据 有可能还有正负之分。比如tinyint 类型:若无正负,即unsined ,范围为:[0,255];若有正负之分,范围为:[-128,127]。
for col in columns:col_name = col[0]col_type_info = col[1]index = int(col_type_info.rfind("(")) # 通过左右括号获取括号内的数据# 处理无长度字段 eg:dateif index == -1:col_type = col_type_infoelse:col_type = col_type_info[:index]# 处理数值类型有符号与无符号if "unsigned" in col_type_info:is_unsigned = 1else:is_unsigned = 2接下来是造符合各字段的数据(以下为常用的一些类型作了处理)
# 对于不同类型的字段,生成数据值的格式、内容等处理# char,varcharif "char" in col_type:col_length = int(col_type_info[index + 1:-1]) # 获取字段允许长度if len(col_name) > (col_length-6):if col_length < 6:value = str(random.randint(0, 9*10**col_length))else:value = str(random.randint(0, random_range))else:value = col_name + str(random.randint(0, random_range))insert_sql = "{0}'{1}',".format(insert_sql, value)elif col_type == "tinyint":# 编码为gbk时,每个字符最多占2个字节;编码为utf8时,每个字符最多占3个字节;此处以utf8编码占用空间计算,下同random_range = 255//(3*1*is_unsigned)value = random.randint(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%d,") % valueelif col_type == "smallint":random_range = 65535//(3*2*is_unsigned) # 除考虑编码外,每个数字占用2个字节value = random.randint(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%d,") % valueelif col_type == "mediumint":random_range = 65535//(3*2*is_unsigned) # 除考虑编码外,每个数字占用2个字节value = random.randint(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%d,") % value# int,integer,bigintelif "int" in col_type:value = random.randint(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%d,") % valueelif col_type in ["decimal", "double", "numeric", "real","float"]:value = random.uniform(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%f,") % valueelif col_type == "date":value = get_date(random.randint(-300, 0))insert_sql = "{0}'{1}',".format(insert_sql, value)elif col_type == "time":value = get_time()insert_sql = "{0}'{1}',".format(insert_sql, value)# timestamp,datetimeelif "time" in col_type:value = get_date(random.randint(-300, 0)) + " " + get_time()insert_sql = "{0}'{1}',".format(insert_sql, value)elif col_type == "year":value = str(random.randint(1901, 2155))insert_sql = "{0}'{1}',".format(insert_sql, value)
以上为第一版代码的,之后对代码稍加改动,支持表关联造数据。当A表中有一个字段为fund_account,B表中有一个字段为fund_account。关联后,A表中的fund_account在B表中都能找到对应的数据。此外还支持一种情况:当A表中还有一个字段clinet_name 字段值与fund_account一致时,可通过配置造出A表中fund_account和clinet_name 与 B表中的fund_account都一致的数据。
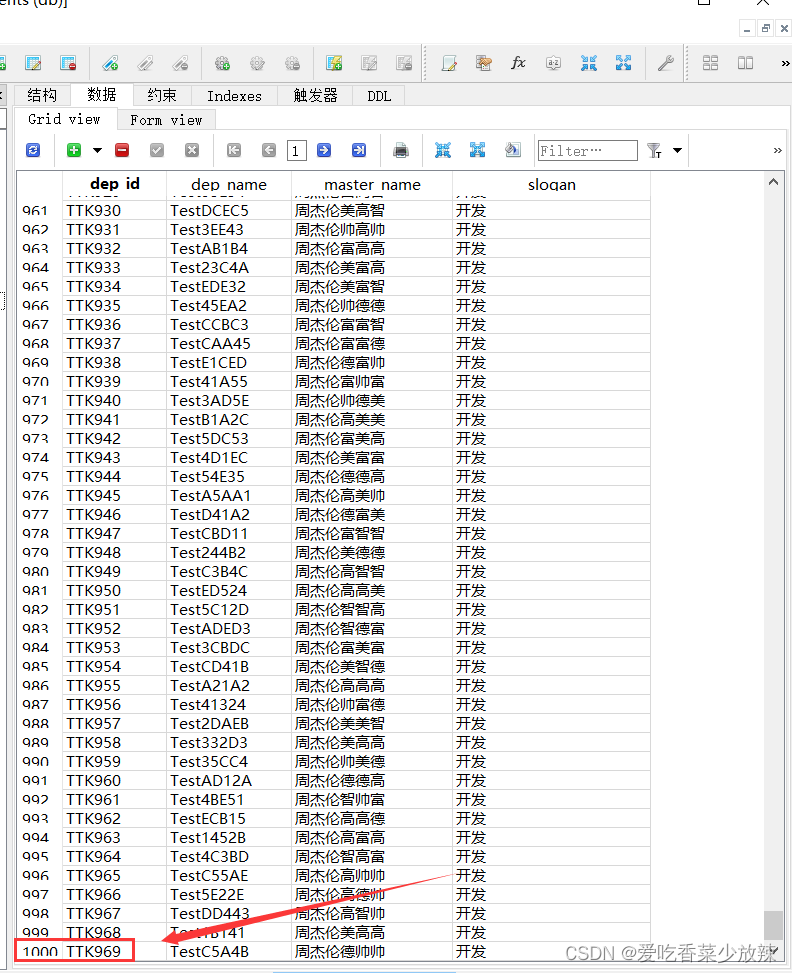
脚本执行后的数据结果如下图:
全部代码如下
# -*- coding: utf-8 -*-
__author__ = "chenk"
from connect_to_mysql import Connect_mysql
import random,datetime,timeclass Generate_Data:def get_cols(self,table):"""获取表字段名、字段类型"""sql = "desc " + tablecur.execute(sql)result = cur.fetchall()return resultdef generate_data_for_mysqldb(self,columns,commit_num,commit_times):"""通用造数据函数columns 是表的所有字段元祖,commit_num 是每次插入数据库的数量,commit_times*commit_num是插入的总数据量"""global linkfieldcommit_num_temp = commit_numlinkfield_index = 0while commit_times:sql = "" # 被执行的sqlsql_value = "" # 数据组集commit_num = commit_num_tempwhile commit_num:insert_sql = "" # 单组数据for col in columns:col_name = col[0]col_type_info = col[1]index = int(col_type_info.rfind("(")) # 通过左右括号获取括号内的数据# linkfield["pass_colunm"] 中的字段是一个标识,可判断防止获取linkfield中产生的数据if linkfield.get(col_name):if not (table+col_name) in linkfield["pass_colunm"]:insert_sql = "{0}'{1}',".format(insert_sql, linkfield[col_name][linkfield_index])linkfield_index += 1continue# 处理数值类型有符号与无符号if "unsigned" in col_type_info:is_unsigned = 1else:is_unsigned = 2# 处理无长度字段 eg:dateif index == -1:col_type = col_type_infoelse:col_type = col_type_info[:index]# 数值类型根据有/无符号,变更输入数据的区间g = lambda x, y: -y - 1 if x == 2 else 0# 处理字段长度random_range = 999999# 对于不同类型的字段,生成数据值的格式、内容等处理# char,varcharif "char" in col_type:col_length = int(col_type_info[index + 1:-1]) # 获取字段允许长度if len(col_name) > (col_length-6):if col_length < 6:value = str(random.randint(0, 9*10**col_length))else:value = str(random.randint(0, random_range))else:value = col_name + str(random.randint(0, random_range))insert_sql = "{0}'{1}',".format(insert_sql, value)elif col_type == "tinyint":# 编码为gbk时,每个字符最多占2个字节;编码为utf8时,每个字符最多占3个字节;此处以utf8编码占用空间计算,下同random_range = 255//(3*1*is_unsigned)value = random.randint(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%d,") % valueelif col_type == "smallint":random_range = 65535//(3*2*is_unsigned) # 除考虑编码外,每个数字占用2个字节value = random.randint(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%d,") % valueelif col_type == "mediumint":random_range = 65535//(3*2*is_unsigned) # 除考虑编码外,每个数字占用2个字节value = random.randint(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%d,") % value# int,integer,bigintelif "int" in col_type:value = random.randint(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%d,") % valueelif col_type in ["decimal", "double", "numeric", "real","float"]:value = random.uniform(g(is_unsigned,random_range), random_range)insert_sql = (insert_sql + "%f,") % valueelif col_type == "date":value = get_date(random.randint(-300, 0))insert_sql = "{0}'{1}',".format(insert_sql, value)elif col_type == "time":value = get_time()insert_sql = "{0}'{1}',".format(insert_sql, value)# timestamp,datetimeelif "time" in col_type:value = get_date(random.randint(-300, 0)) + " " + get_time()insert_sql = "{0}'{1}',".format(insert_sql, value)elif col_type == "year":value = str(random.randint(1901, 2155))insert_sql = "{0}'{1}',".format(insert_sql, value)# 判断字段是否在配置 linkfield_judge中,若是,则需存储数据值if col_name in linkfield_judge.keys():if not linkfield.get(col_name):linkfield[col_name] = list()linkfield[col_name].append(value)# 处理同一张表中多个字段值相同的情况for k, w in linkfield_judge.items():if k != col_name and w == linkfield_judge[col_name]:if not linkfield.get(k):linkfield[k] = list()linkfield[k].append(value)# 对于正常生成数据的字段,放在过滤字段列表中,以作标识if not table+col_name in linkfield["pass_colunm"]:linkfield["pass_colunm"].append(table+col_name)sql_value += "({0}),".format(insert_sql[:-1])commit_num -= 1sql += "insert into {0} values {1};".format(table, sql_value[:-1])# 执行拼接的SQLtry:cur.execute(sql)conn.commit()print("Insert into {0} successfully!".format(table))except:print("SQL ERROR:{0}".format(sql))commit_times -= 1def get_date(num=0):"""获取今日日期"""if num == 0:return datetime.date.today().strftime("%Y%m%d")else:return (datetime.date.today() + datetime.timedelta(days=num)).strftime("%Y-%m-%d")def get_time():"""获取今日日期"""return time.strftime("%H:%M:%S")if __name__ == "__main__":# 连接数据库connect_mysql = Connect_mysql()mysql_config = connect_mysql.get_config("mysql_config.json")conn, cur = connect_mysql.conn_mysql(host=mysql_config["localhost_cf_test"]["host"],port=mysql_config["localhost_cf_test"]["port"], \user=mysql_config["localhost_cf_test"]["user"],password=mysql_config["localhost_cf_test"]["password"], \database=mysql_config["localhost_cf_test"]["database"],charset=mysql_config["localhost_cf_test"]["charset"])generate_data = Generate_Data()tables = ["portrait_all","portrait_fund"] # 配置需要插入数据的表名# 配置各表关联字段的关系,值相同的键为关联字段 eg: linkfield_judge = {"fund_account":0,"client_id":0, "client_name":1}# 下述配置的意思为 配置的表中若有fund_account 与 client_id,各表中字段fund_accout、client_id都做关联;# 各表的client_name值都会关联。linkfield_judge = {"fund_account":0,"client_name":0}# 例如:linkfield: {'pass_colunm':['portrait_allfund_account'],'client_name':['fund_account91', 'fund_account01'}linkfield = {"pass_colunm":[]} # 存储关联字段的值for table in tables:# print("linkfield:",linkfield)cols = generate_data.get_cols(table) # 获取表字段generate_data.generate_data_for_mysqldb(columns=cols,commit_num=10,commit_times=5) # 生成数据以上代码运行时需要配置的是:
tables = ["portrait_all","portrait_fund"] # 配置需要插入数据的表名
linkfield_judge = {"fund_account":0,"client_name":0}
以及下述 commit_num 每次提交插入数据的sql值的个数;每张表中造的数据总是=commit_num*commit_times
generate_data.generate_data_for_mysqldb(columns=cols,commit_num=10,commit_times=5) # 生成数据有关 from connect_to_mysql import Connect_mysql 这个方法以及相关配置可查阅此文章:https://blog.csdn.net/ck3207/article/details/80233204