目录
01 前言
02 GSMap-MVK的存储方式和数据集介绍
03 代码实现
01 前言
这么晚了我还是希望将这篇博客写一下,记录生活。
我所下载的数据集为GSMap-MVK数据集,延迟大概2.5月左右我记得.边下载我就想着先处理着吧。
例如,其中一个文件如下:
gsmap_mvk.20190101.1400.v7.2112.0.dat.gz
解压之后:
gsmap_mvk.20190101.1400.v7.2112.0.dat
发现是ENVI默认格式,于是尝试使用ArcGIS打开,发现是一种不支持的格式,我想可能是因为这种.dat只能ENVI打开吧,于是使用ENVI再次打开,无果。猜测是否可能是hdf4/hdf5/nc4,发现均不是,我明白我遇到对手了,再次确认数据没有下载错误并尝试了其他文件,均是如此。于是寻找博客文档等。发现确实一些博客解决了问题,但是没有说清楚为什么需要如此操作,于是去找官网等等途径了解数据集。现如下。
02 GSMap-MVK的存储方式和数据集介绍
这是JAXA关于GSMap相关数据格式的解释文档链接:http://sharaku.eorc.jaxa.jp/GSMaP/document/DataFormatDescription.pdf

或许该文档已经过时了,因为我的数据集是GSMap-MVK,但是我并没有找到MVK的说明,然后既然MVK是标准版,那我们就拿和他最接近的GSMap-Gauge数据集(不仅仅是这个原因而是通过文档发现大部分的.dat数据集都是以该方式进行存储)的存储方式进行解析。
通过Gauge的Data format我们了解到,其.dat文件是由4个字节的浮点数构成的,那么这就好办了。一开始我以为.dat里面应该存在很多其他东西,没想到只含有一堆关于降水率的四字节浮点数,没有存储其他任何东西包括坐标系等。
所以,坐标系等等呢?继续翻看文档:

发现经纬度的分辨率为0.1°,覆盖范围为0~360, 60°N~60°S,左上角像元的中心坐标为(59.95°N, 0.05°E)。那么基本上仿射参数也就有了。
另外,我们还需要影像的行列数才行,于是翻看文档:
可以发现,对于所有二进制文件(就是那些多少多少字节的浮点数之类的文件),其行列数为3600rows×1200lines,刚刚看到这个时我有点蒙了,为什么都是行,然后猜测既然东西跨度那么大按道理应该时3600行1200列,正好文档有一幅图吻合我的猜测(如下)。
图像的基本信息可视化如下: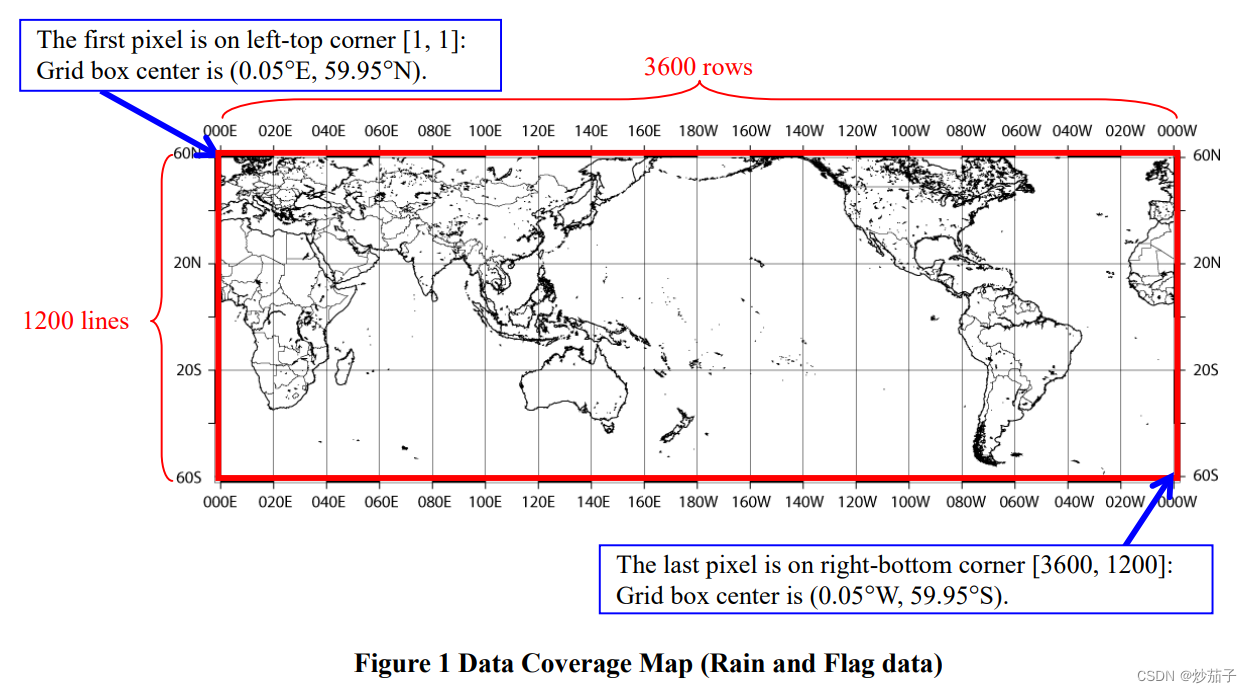
至于坐标系是什么,说实话,对于没有直接说明坐标系或者仅仅提供一些参数或者经纬度数据集的,我一般都是按照WGS84坐标系进行输出,因为它是默认的。
另外需要说明的缺失值问题,参考文档:
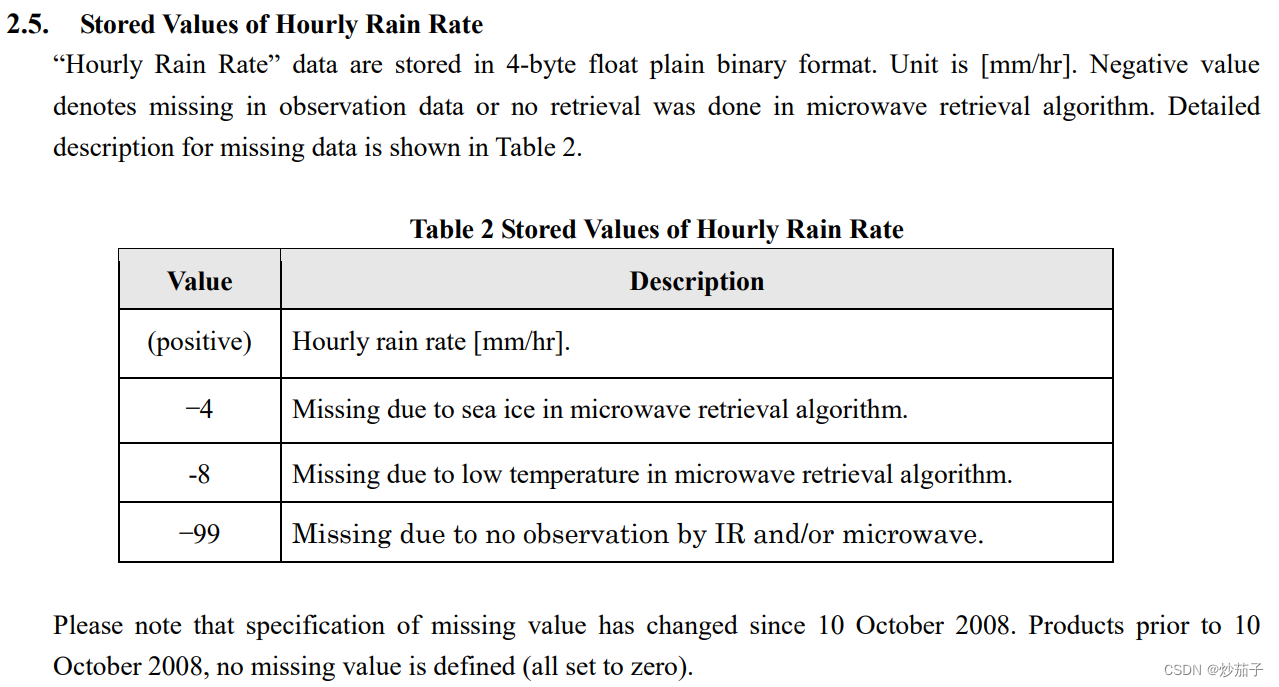
如果你的数据集是2008年前的,那么缺失值全部设置是0,若是2018年往后,那么缺失值设置为-4、-8、-99,因为我一视同仁,而且降水率/降水量不可能为负数,所以将所有为负值的数全部设置为NoData即可。
03 代码实现
知道基本信息之后实现起来就比较简单。
有回答使用QGIS实现,参考:gdal - Reading JAXA GSMaP data in QGIS? - Geographic Information Systems Stack Exchange
也有官方文档使用ENVI IDL, fortran语言实现等,链接FTP后在类似sample文件夹 中

当然,也有使用python实现的,例如:
Python reads GSMAP data - Programmer Sought
Python处理GPM(IMERG/GSMaP)卫星降水数据 - 简书 (jianshu.com)
这里我就展示一点新意,大家的文件应该都是.gz的压缩文件,所以如果大家先解压处理那么 数据量翻一倍,然后对解压的数据再处理输出数据又增加了的,因此我是直接输入压缩包进行处理。免去解压这一步,一旦你的数据量特别大时你需要考虑。
代码需要你额外安装rasterio, numpy模块
import gzip
import rasterio
import numpy as np
from rasterio.transform import from_origin# preparation
in_path = r'F:\ExtremePrecipitation\TEMP\gsmap_mvk.20190101.0400.v7.2112.0.dat.gz'
out_path = r'F:\ExtremePrecipitation\TEMP\gsmap_mvk.20190101.0400.v7.2112.0.tif'
rows = 1200
cols = 3600
lon_upper_left = 0
lat_upper_left = 60
lon_res = 0.1
lat_res = 0.1
_type = np.float32 # because 4-Bytes floats means 32 bits floats, 1 Byte = 8 bits# get data from .gz file
with gzip.open(in_path, 'rb') as f:data = f.read()data = np.frombuffer(data, dtype=_type)data = np.array(data).reshape(rows, cols)data[data < 0] = np.nanwith rasterio.open(out_path, 'w', driver='GTiff',height=rows, width=cols,count=1, dtype=data.dtype,crs='+proj=latlong', # the coordinate acrually is WGS84nodata=np.nan,transform=from_origin(lon_upper_left, lat_upper_left, lon_res, lat_res)) as dst:dst.write(data, 1) # write the precipitation dataset into the first band of the tif file我所使用的rasterio模块进行处理,当然你可以使用gdal处理,只是rasterio对于我来说更Pythonic。
另外,如果你有很多文件需要处理,那么你需要注意对代码进行改进时注意内存不要饱满了,建议使用glob.iglob而非glob.glob因为前者得到路径的生成器而后者得到路径的列表,这里不再过多赘述了。(glob为内置模块)
拜~





