摘要
以往的注意力机制,要么只关注同一空间不同通道的信息,要么只关注不同空间同一通道的信息,这会导致模型容易忽略小的对象,并错误分割较大的对象。本文提出了一种新的注意力机制,综合考虑两方面的信息。

NL=non-local,全局的
方法
架构
用ResNet-101或HRNetV2-W48提取特征图X,其中ResNet-101的最后两层为空洞卷积。X经过一个卷积处理减少通道数得到Fin,Fin经过全注意力模块(Fully Attentional block,FLA)处理得到Fo,最终Fo放入预测器进行分割。
FLA
从架构可知,本文的创新点在于FLA模块。该模块如下图。

Q的尺度和V的尺度均为(H+W)XCXS,K的尺度为(H+W)XSXC,因为本文H=W,因此作者直接令S=H=W
QKV都是通过同一套流程得到的,只不过参数值不共用,K的过程与Q和V稍有区别。
以Q为例,F会经过一个池化和一个线性层,得到一个CX1XW的矩阵,然后将这个矩阵复制H份,切割,便得到了H个CXW大小的矩阵。另一方面,通过池化和线性层得到的是CXHX1的矩阵,将这个矩阵复制切割后得到了W个CXH大小的矩阵。将这两堆矩阵放在一起,就是Q。
因为H=W,因此用S来表示融合后的那堆矩阵的一条边的长度,减少代码歧义,不然描述矩阵大小为CXH时,代码中不确定是融合后的还是融合之前的。
然后通过Affifinity操作,将QK融合。具体计算公式如下
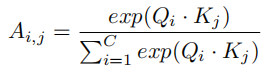
因为这一步是计算不同通道之间的关系,所以ij下标的范围均为1到C,C是通道数。Qi,Kj尺寸为(H+W)XS。结合图像可以看到,Qi实质上是一堆横向量,Kj是一堆竖向量,两者相乘会得到一个数。每次相乘会有(H+W)对向量,因此Ai,j实质上是一个向量,长度为(H+W)。
又因为要计算每一对通道之间的关系,包括自身,总共有C个通道,所以要得到CXC个向量,因此A最终尺寸为(H+W)XCXC。
然后,用A与V做矩阵相乘,得到(H+W)个CXS的矩阵。将这对矩阵从中间分开分成两份,每一份都有S个CXS大小的矩阵。将这两堆矩阵各自重新拼合,调整下标顺序,得到两个CXHXW的特征图。两者相加即为最终输出Fo
实验

在Cityscape数据集上的结果

从这几个例子可以看出,本文方法分割地更加精准,不容易忽略或扭曲较小的对象。

在ADE20K数据集上的结果

在PASCAL VOC数据集上的结果。那个像个竖起来的哑铃的图标表示模型未使用在COCO上预训练的backbone
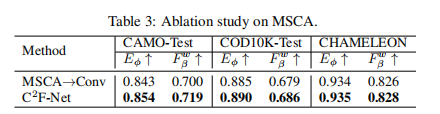
消融实验
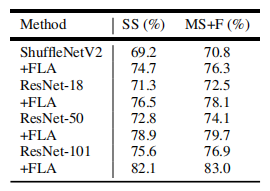
消融实验探讨了FLA模块的有效性,可以看出,使用了FLA模块后,特征图变得更加利于分割。