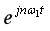文章目录
- 一、先验知识
- 1.FPN
- 2.4D-correlation map
- 二、论文框架
- 1.动机
- 2.网络结构
- 三、实验结果
- 参考文献
一、先验知识
1.FPN
【目标检测】FPN(Feature Pyramid Network)这篇文章讲的挺好的。
2.4D-correlation map
4D指的是4个维度,因为输入两幅图片,每幅图片得到的特征图大小为hxw(2D),且要进行像素级语义对应故需要计算两个特征图上每个点的对应关系,故需要得到hxwxhxw次,这便是4D的含义,correlation表示互信息。4D correlation map如何得到呢,下面我放一下pytroch的代码,大家就一目了然了。
class FeatureCorrelation(torch.nn.Module):def __init__(self, normalization=True):super(FeatureCorrelation, self).__init__()self.normalization = normalizationself.ReLU = nn.ReLU()def forward(self, feature_A, feature_B):b, c, hA, wA = feature_A.size()b, c, hB, wB = feature_B.size()# reshape features for matrix multiplicationfeature_A = feature_A.view(b, c, hA * wA).transpose(1, 2) # size [b,c,h*w]feature_B = feature_B.view(b, c, hB * wB) # size [b,c,h*w]# perform matrix mult.feature_mul = torch.bmm(feature_A, feature_B)# indexed [batch,row_A,col_A,row_B,col_B]correlation_tensor = feature_mul.view(b, hA, wA, hB, wB).unsqueeze(1)if self.normalization:correlation_tensor = featureL2Norm(self.ReLU(correlation_tensor))return correlation_tensor
通过对4D correlation map进行一定的处理就可以用来计算得到语义对应关系了。
举一个计算对应关系的例子,图片A、B的特征图为FA、FB,大小均为(h,w),那么对应的4D correlation map大小为(h,w,h,w),任取图片A上一点a,对应的特征图FA上的点为Fa,那么Fa一个点便和FB一张图进行对应,利用一定的规则如点与点之间的距离作为衡量标准,那么取FB上距离Fa距离最小点Fb变为Fa的对应点。
二、论文框架
1.动机
目的:
- 寻找一种网络结构用来进行像素级的语义对应。
问题:
- 颜色、尺度、方向、照明和非刚性变形的大类内变化,语义对应问题仍然非常具有挑战性。
- 虽然现阶段的特征提取器能够提取得到具有丰富语义的特征,但是,在语义对应中,最顶层相邻像素之间的模糊性会导致性能下降。
启发:
- 人观看图像是先看整体,后看细节,这体现一种从粗粒度到细粒度。
- 特征提取器高阶特征具有丰富的语义但缺少位置信息,低阶特征语义信息较少,但是位置信息丰富。
- 利用Transformer可以缓解最顶层相邻像素之间的模糊性。
创新点:
- 第一个是特征增强路径(Feature Enhancement),它对空间上更粗糙但语义上更强的特征图进行上采样,并将它们与来自横向连接的特征融合以产生更高分辨率的特征。
- 第二个是匹配增强路径(Matching Enhancement),它学习更精细和互补的匹配细节,以增强较低分辨率的粗糙匹配结果。我们从解码器的第一层开始生成最粗略的匹配结果,并在不同语义级别使用互补匹配细节对它们进行上采样和增强。
特征增强路径通过尺度内增强和跨尺度增强来增加特征图的表示能力。匹配增强路径从较粗级别学习与匹配结果互补的匹配细节。
- 在提取特征阶段,设计了一种新颖的尺度内特征增强模块(Inner-scale Enhancement),它同时融合了每个卷积组中的所有特征图,并进一步提高了融合特征图与局部变换器的判别能力。
2.网络结构

注: 这个不是UNet结构,Encoder部分没有串联,我一开始也认为是UNet结构,重新阅读论文并看了代码后才发现不是UNet结构。
关于细节和公式论文中说的很细,这里不再介绍。
论文框架主要在干两件事情:
- 提取特征并将不同尺度特征进行融合从而增强特征
- 计算4D correlation map,并将不同尺度特征获得的4D correlation map进行融合从而增强得到的4D correlation map(因为4D correlation map是通过两幅图像的特征map进行矩阵相乘得到的,故相当于特征的二次加强。)
a.Feature Enhancement


根据作者描述,这部分主要分为两个部分:尺度内和跨尺度 融合。
- 首先看一下尺度内特征融合。通过ResNet提取得到的特征后通过SEM+卷积层得到尺度内的高阶特征,将这几个高阶特征进行concentrate后输入进入Local Self Attention中,便得到尺度内融合后的特征。关于将几个特征进行融合意义不用多说,这个虽然会增加计算量,但便于在训练过程中特征的选择增多。使用SEM模块作者解释是为了扩大单个神经元的感受野并捕获不同尺度的语义(我看了一下SEM的源码好像就是利用了空洞卷积去增大感受野)。使用Local Self Attention目的视为了解决高阶特征相邻像素之间的模糊性。
关于Local Self Attention论文中有详细的介绍,这里不在多说。 - 跨尺度融合过程不用多说。通过反卷积扩大上一层得到融合后特征的尺寸并和当前层的特征进行融合。
b.Matching Enhancement


首先将得到的两个Feature Map转化为4D correlation map,接着通过插值法提高尺寸大小用来和下一个尺寸的4D correlation map进行融合。
该结构采用了和FPN的top to down结构,即每一层得到的结果单独做一个预测,此外传递到下一层进行增强。
预测部分参考了另一篇文章《Correspondence Networks with Adaptive Neighbourhood Consensus》中的预测方法,然后作者在此基础上利用概率值计算损失函数。
具体做法为(以下均为看源码加参考文献所得,为本人思考,若有问题敬请批评指正):
- 因为GT中的关键点在图像上,而我们的预测结果是特征图,故需要进行缩放到特征图的空间维度(乘以一个缩放因子),参考ANC Net的做法,因为缩放过程中原来在GT上的坐标点是整数值,缩放后就可能变成带有小数的值,故无法进行准确定位,这时便可以取缩放后点的4个距离最近邻来进行代替。同样,因为要利用概率值计算损失函数,故需要计算4个最近邻的概率值(利用距离缩放后点的欧式距离的倒数取softmax得到)。因为要得到一张和Feature map一样大小(c×w)的预测图,故除了4个最近邻的概率值外,其余点的概率值为0。这样我们便得到了GT的一个关键点对应的概率图,共有n个关键点,便有n个概率图。得到概率图后要利用高斯滤波器过滤一下使得概率图更加平滑并可以进行去噪。
- 4D correlation map对应的概率图做法便比较简单了,因为GT用了4个最近邻,故4D correlation map这的对应点需要融合4个最近邻的对应的特征图(具体做法为加权求和),然后便得到了cxw大小的概率图。(不是一个点吗,为啥得到的是cxw大小的概率图,因为4D指的是4个维度,分别对应两张特征图的两个维度,故图片A得到的特征图上的点a对应图B特征图便是cxw大小)
- 最后便可以带入损失函数公式进行计算了。
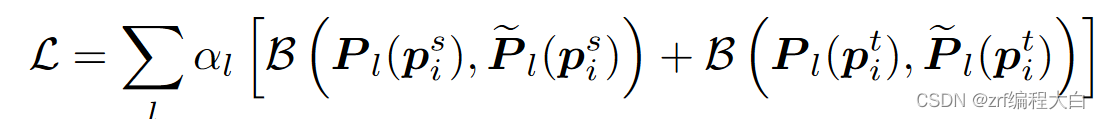

首先将Ground Truth中的关键点重新缩放到与不同尺度下的特征图相同的分辨率。然后,根据ANC - Net,我们选择它的四个最近邻,并根据距离设置它们的概率,以建立每个尺度上的二维真值匹配概率。然后我们在概率图上应用大小为3的二维高斯平滑。
三、实验结果





参考文献
1.论文笔记(2):Deep Crisp Boundaries: From Boundaries to Higher-level Tasks
2.FlowNet : simple / correlation 与 相关联操作
3.【目标检测】FPN(Feature Pyramid Network)
4.关键点估计之 PCK, PCKh, PDJ 评价度量