1 API说明
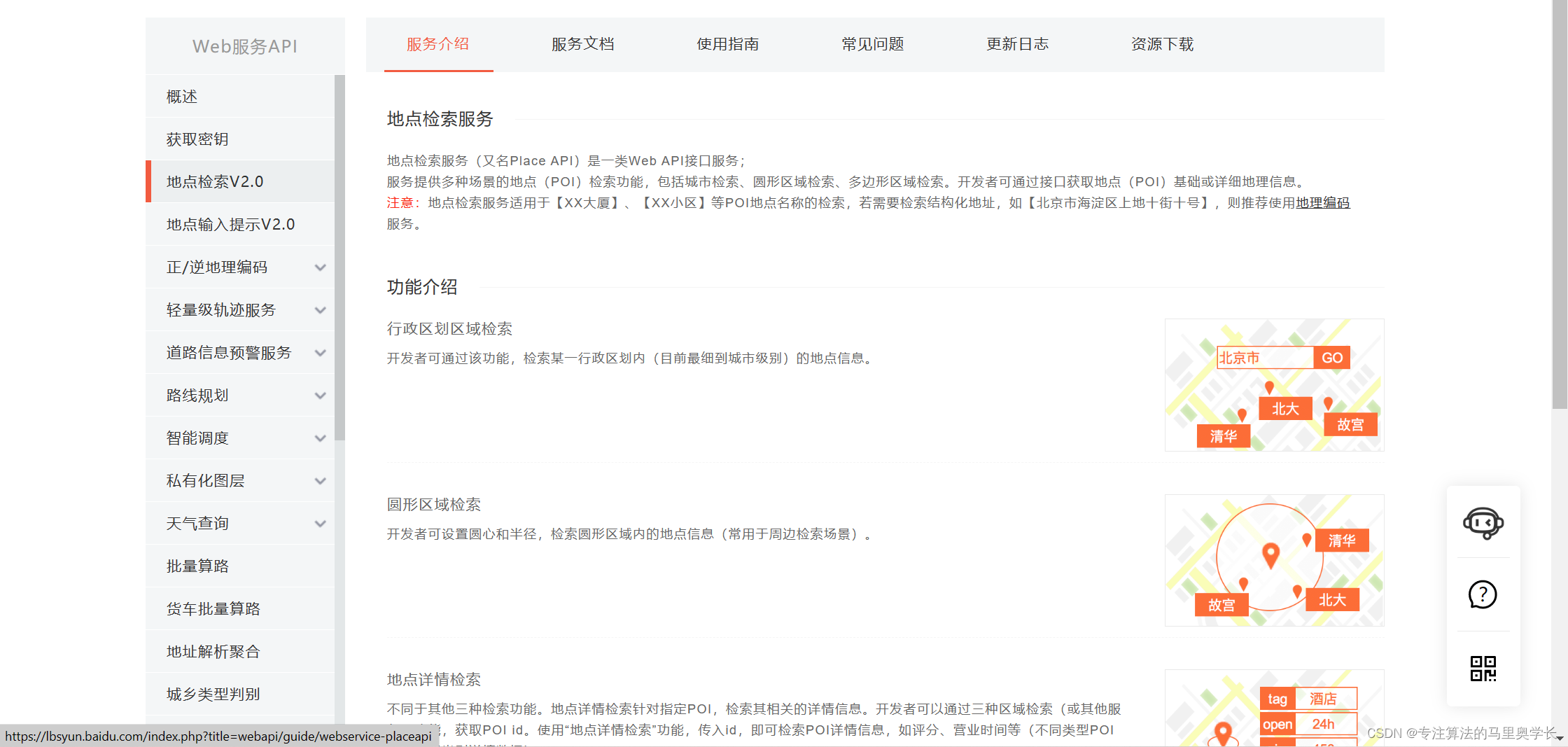
目前百度地图的最新版为地图检索V2.0服务。详细介绍可以通过开发文档-web服务Api-地点检索V2.0获取。
在使用API前需要提前注册账号获取ak。对于免费账号:目前的每日访问次数是100次,最多可以获取2000条数据。
如不需讲解仅需要下载代码:链接直达
2 代码分块讲解
2.1 空表头建立
首先构建一个新的csv文件,用于存储后续我们爬到的API数据。
import requests
import pandas as pdheader = [['province', 'city', 'area', 'name', 'lng', 'lat']]
out = pd.DataFrame(header)
save_path = '文件保存路径与文件名'
out.to_csv(save_path, mode='a', header=False,index=False, encoding='ANSI')
在后面我们需要保存API的省市区以及名称、经纬度信息,因此前面在建立空表时先将表头建立好。
2.2 构建请求与网页访问
本次以行政区划区域检索为例,希望检索某市的全部温泉商户。
query = '温泉' # 检索关键字
region = '281' # 检索行政区划区域(增加区域内数据召回权重,如需严格限制召回数据在区域内,请搭配使用city_limit参数)
city_limit = 'true' # 区域数据召回限制,为true时,仅召回region对应区域内数据。
page_size = '20' # 单次召回POI数量,默认为10条记录,最大返回20条。
page_num = '0' # 分页页码,默认为0,0代表第一页
ak = '你的ak'url = f'https://api.map.baidu.com/place/v2/search?query={query}®ion={region}&city_limit={city_limit}&' \f'page_size={page_size}&page_num={page_num}&coord_type=1&output=json&ak={ak}'对于构造的url,前面https://api.map.baidu.com/place/v2/search?为产品信息,不需更改。后面的参数可以根据个人需求设置,并可按任意顺序组合。可设置的参数有:



本次我们根据需求设置了多个参数构建了url,其中5个考虑到可能日后会多次修改,以变量形式存在,其余的直接写进了url之中。如果不确定url是否正确可以使用print将其打印出来,用浏览器访问这个url来测试。如果访问正常,其返回内容应该是类似下面的json格式信息:

对于json格式信息的查看,建议使用JSON-handle等插件进行阅读,其层次结构会更加直观。

确认url可以访问后,访问网址并保存网址返回的json格式数据。
html = requests.get(url) # 获取url
data = html.json() # 通过json()解析数据
html.close() # 关闭网页链接
count = data['total']
page_total = int(count/20)+1]
在total中,表示此次访问共可以返回的数据数量,因为我们设置了每页返回20条数据,所以经过简单的计算便可得出总页数,用于后续的循环中。
保存爬取的结果
num = 0 # 计数器
try:for page_num in range(page_total):url = f'https://api.map.baidu.com/place/v2/search?query={query}®ion={region}&city_limit={city_limit}&' \f'page_size={page_size}&page_num={page_num}&coord_type=1&output=json&ak={ak}'html = requests.get(url) # 获取urldata = html.json() # 通过json()解析数据html.close() # 关闭网页链接for i in range(20):province = data['results'][i]['province']city = data['results'][i]['city']area = data['results'][i]['area']name = data['results'][i]['name']lng = data['results'][i]['location']['lng']lat = data['results'][i]['location']['lat']information = [[province, city, area, name, lng, lat]]out = pd.DataFrame(information)out.to_csv(save_path, mode='a', header=False,index=False, encoding='ANSI')num = num + 1print('当前获取第' + str(num) + '条数据中。')
except Exception as e:print('获取完成')print('结束代码:', str(e))
在最外层使用了一个try-except结构,因为在爬取到最后时,一页可能不满20条数据,即产生报错。如果这是全部程序不加这个结构也没问题,但是如果程序外部有嵌套,建议加上以保证程序正常运行。
这段代码有两层循环,第一层是遍历不同的页数,第二层是遍历每页各条数据进行保存。每读取一条数据后,使用追加的方式保存在csv文件中。
3 完整代码
'''
使用的是百度开发者平台地图检索功能
用于爬取营口市的洗浴数据
'''import requests
import pandas as pd# 构建表头
header = [['province', 'city', 'area', 'name', 'lng', 'lat']]
out = pd.DataFrame(header)
save_path = 'F:\代码包\产品中心代码\温泉POI结果.csv'
out.to_csv(save_path, mode='a', header=False,index=False, encoding='ANSI')# 构建请求并计算所需页码
query = '温泉' # 检索关键字
region = '281' # 检索行政区划区域(增加区域内数据召回权重,如需严格限制召回数据在区域内,请搭配使用city_limit参数)
city_limit = 'true' # 区域数据召回限制,为true时,仅召回region对应区域内数据。
page_size = '20' # 单次召回POI数量,默认为10条记录,最大返回20条。
page_num = '0' # 分页页码,默认为0,0代表第一页
ak = '你的ak'url = f'https://api.map.baidu.com/place/v2/search?query={query}®ion={region}&city_limit={city_limit}&' \f'page_size={page_size}&page_num={page_num}&coord_type=1&output=json&ak={ak}'html = requests.get(url) # 获取url
data = html.json() # 通过json()解析数据
html.close() # 关闭网页链接
count = data['total']
page_total = int(count/20)+1# 保存结果
num = 0 # 计数器
try:for page_num in range(page_total):url = f'https://api.map.baidu.com/place/v2/search?query={query}®ion={region}&city_limit={city_limit}&' \f'page_size={page_size}&page_num={page_num}&coord_type=1&output=json&ak={ak}'html = requests.get(url) # 获取urldata = html.json() # 通过json()解析数据html.close() # 关闭网页链接for i in range(20):province = data['results'][i]['province']city = data['results'][i]['city']area = data['results'][i]['area']name = data['results'][i]['name']lng = data['results'][i]['location']['lng']lat = data['results'][i]['location']['lat']information = [[province, city, area, name, lng, lat]]out = pd.DataFrame(information)out.to_csv(save_path, mode='a', header=False,index=False, encoding='ANSI')num = num + 1print('当前获取第' + str(num) + '条数据中。')
except Exception as e:print('获取完成')print('结束代码:', str(e))