【注意力机制】
核心思想:在decoder的每一步,把encoder端所有的向量提供给decoder,这样decoder根据当前自身状态,来自动选择需要使用的向量和信息.
【注意力带来的可解释性】
decoder在每次生成时可以关注到encoder端所有位置的信息。
通过注意力地图可以发现decoder所关注的点。
注意力使网络可以对齐语义相关的词汇。
【注意力机制的优势】
RNNs顺序计算阻碍了并行化
论文:Attention is all you need
【Transformer的结构】
概览encoder-decoder结构

把句子/单词序列切分成一个个的单元,每个单元叫做token,通过embedding幻化为一个向量。
输入层:token的byte pair encoding+token的位置向量(表示它在文本中的位置)
中间模型结构:一些编码和解码块的堆叠。
输出: 一个在词表上的概率分布
损失函数:交叉熵
【输入层:BPE + PE】
BPE byte pair encoding一种分词算法
解决了OOV(out of vocabulary)问题,把罕见字词和未知词编码为字词,例如用一些词根组合来表示。
PE:位置编码
因为不像RNN顺序依次处理每个单词,所以要把位置信息编码后喂给模型。
input=bpe+pe
以上就是论文中比较经典的图啦,对于小白来说太复杂了,暂时不建议深究。
【对transformer的感性认识】
作为一个实用主义者,为了更好的理解和方便后续应用大模型,此处粗略从感性角度讲一下,不妥之处请大拿评论区斧正。
【tansformer由两部分组成】
Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。
如论文中图1所示:Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。橘黄色部分为 Multi-Head Attention(多头注意力),是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
【自注意结构和多头注意力结构】
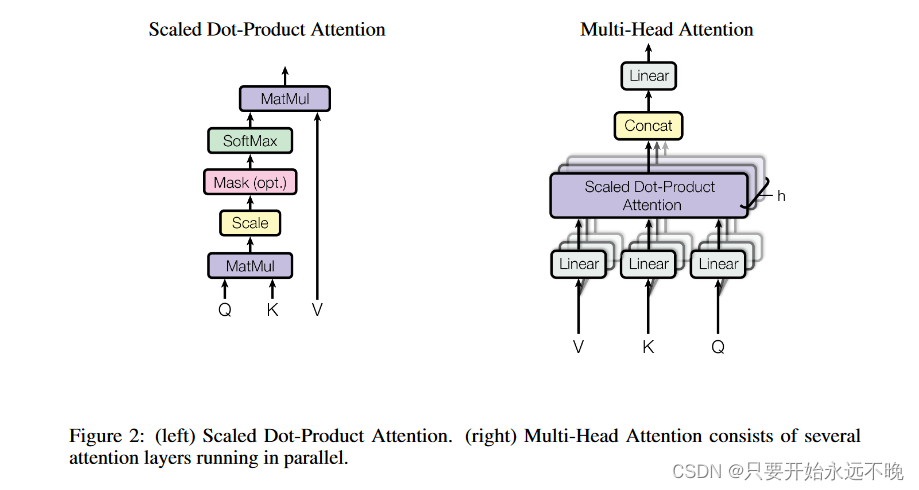
图2左边是 Self-Attention 的结构,右边是多头,即Self-Attention 重复N遍。
Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。而Q,K,V正是通过 Self-Attention 的输入层(词嵌入表示+位置编码)进行线性变换得到的。
其中有个操作时:每个词的Q矩阵都要与其他每个单词的K进行内积,我猜以此来表征句子中每个单词间关系,同时通过权重来反映“注意力”落在了哪里。
那多头就是重复N次自注意力结构的结算,Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
Feed Forward 层比较简单,是一个两层的全连接层,将高维变低维度,方便后续的分类或其他任务。
【decoder块】
1、自底向上方法第一个多头的是masked多头,就是遮盖的意思,在生成第i个词的时候遮住第i个以后的词。它的输入是:样本输出句子编码矩阵/翻译后的句子编码矩阵+masked矩阵。
2、自底向上方法第二个多头矩阵和encoder里的多头计算基本一致。 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q 。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息。
原理的知识暂且分享到这里,后面以更加实用的应用知识为主。
课后阅读:
transformer模型详解