DeepAR代码详析(pytorch版)实现用电量预测 – 潘登同学的RNN学习笔记
文章目录
- DeepAR代码详析(pytorch版)实现用电量预测 -- 潘登同学的RNN学习笔记
- 数据集说明
- 数据预处理代码
- 构造模型
- Loss函数
- 评估指标相关
- utils工具类
- 训练模型
前言: 上次用Amazon中的glount-ts框架做了一个deepar的股价预测,但是我感觉用的是人家的API,不太好,所以今天来搂一把pytorch的deepar,看看效果如何
数据集说明
数据集说明
- 2011 ~2014期间;
- 370 个 家庭的用电量;
- 频率为 15分钟,但是取的时候是以一个小时为单位取的;
下载地址,下载好解压后放到./data/elect/目录下
超参数
- 滑动窗口长度: 192 换算为天数为 192/24 = 8
- 已知序列(上下文)长度: 168 换算为天数 168/24 = 7
- 预测序列长度: 24 换算为天数 24/24 = 1
了解数据预处理之前,我们需要明确我们的输入与输出
- 输入:上下文长度的协变量(covariates) X t X_t Xt与上一时刻的结果 Z t − 1 Z_{t-1} Zt−1,加上一个指示向量(表示哪一户人家,one-hot形式)
- 输出:这一时刻的结果 Z t Z_t Zt
训练集与测试集
- 训练集的开始时间是: 2011-01-01 00:00:00
- 训练集的结束时间是: 2014-08-31 23:00:00
- 测试集的开始时间是: 2014-08-25 00:00:00 因为要有7天的上下文
- 测试集的结束时间是: 2014-09-07 23:00:00
数据预处理的几个关键
- 有些家庭可能在2011的时候没有入住或者没有开始使用,要将前面全零的这部分去掉
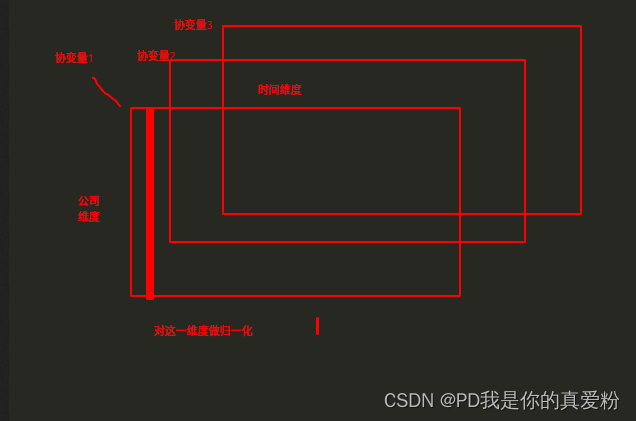
- 该文是将数据的时间维度按照星期几、小时数(比如上午8:00)、月份当作了协变量
- 对协变量做数据归一化的时候,是按照协变量级别来做的(将所有家庭,所有时间点的星期几这一变量放到一起做归一化),因为在这里协变量都是周而复始的,所有家庭都共用相同的协变量,所以对对所有时间点,所有家庭的协变量做归一化其实跟只将所有家庭的写变量分不同时间点做归一化是一样的;我认为在协变量不同的情况下,就比如股价预测,每个公司的四价一量都不一样,如果做归一化的话(当前时间点的四价一量与过去时间点的四价一量表达的含义一定不一样),应该对每个时间点做归一化;
数据预处理代码
建议先把数据下载下来,不然会很慢

构造模型
deepAR的模型本质上是一个RNN,RNN cell使用的是LSTM,只是在最后输出接了两个全连接层,一个是预测均值的,一个是预测标准差的(一开始我认为只要接一个就可以,最后输出两个神经元即可,后来发现标准差的那个要经过一个softplus激活函数,这个激活函数是relu的一个改进版本,最后接这个的目的也是为了保证标准差为正)
输入的时候,还将one-hot经过embedding层(这都是比较常规的操作啦)

Loss函数
Loss的构造比较容易理解,在论文中我都没太看懂loss,但是代码里面我看懂了;思路就是根据预测出来的均值与标准差重构一个正态分布,再计算对数似然(就是计算label在该分布下的对数概率),最小化负平均似然即可

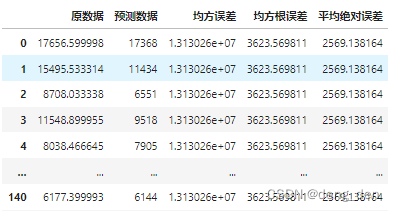
评估指标相关

utils工具类
工具函数中写了很多params,画图,评估函数,保存模型等的工具类,总之复用性很高,可以借鉴,我这里也贴出来

训练模型
训练模型这个操作就比较常规了,不详细讲解了,这个的日志写的也不错,贴一下吧;然后test也在evaluate中被调用,所以就没必要另说test了,test的代码也在构造模型中,也比较简单,是一个decoder的过程

写在最后,该代码不是我写的,源码在github上获取,这里只是我的解读,不懂的可以跟我探讨,总的来说我认为这个pytorch的复现版本写的很优秀,如果想改的话,只需要改改数据预处理部分即可; 如果真的想用该源码做股价预测,就改数据预处理部分吧…