当生成式AI和大模型的飓风呼啸而来,全球掀起了一场狂热的GPT竞赛,大量紧迫的前沿议题随之接踵而至:
语言、视觉、多模态大模型分别有哪些研究突破口?如何显著提升大模型的计算速度、效率和扩展性?怎样确保大模型始终安全可控、符合人类意图和价值观?国内产学研界亟待做些什么,才能更好地迎接大模型时代?
目录
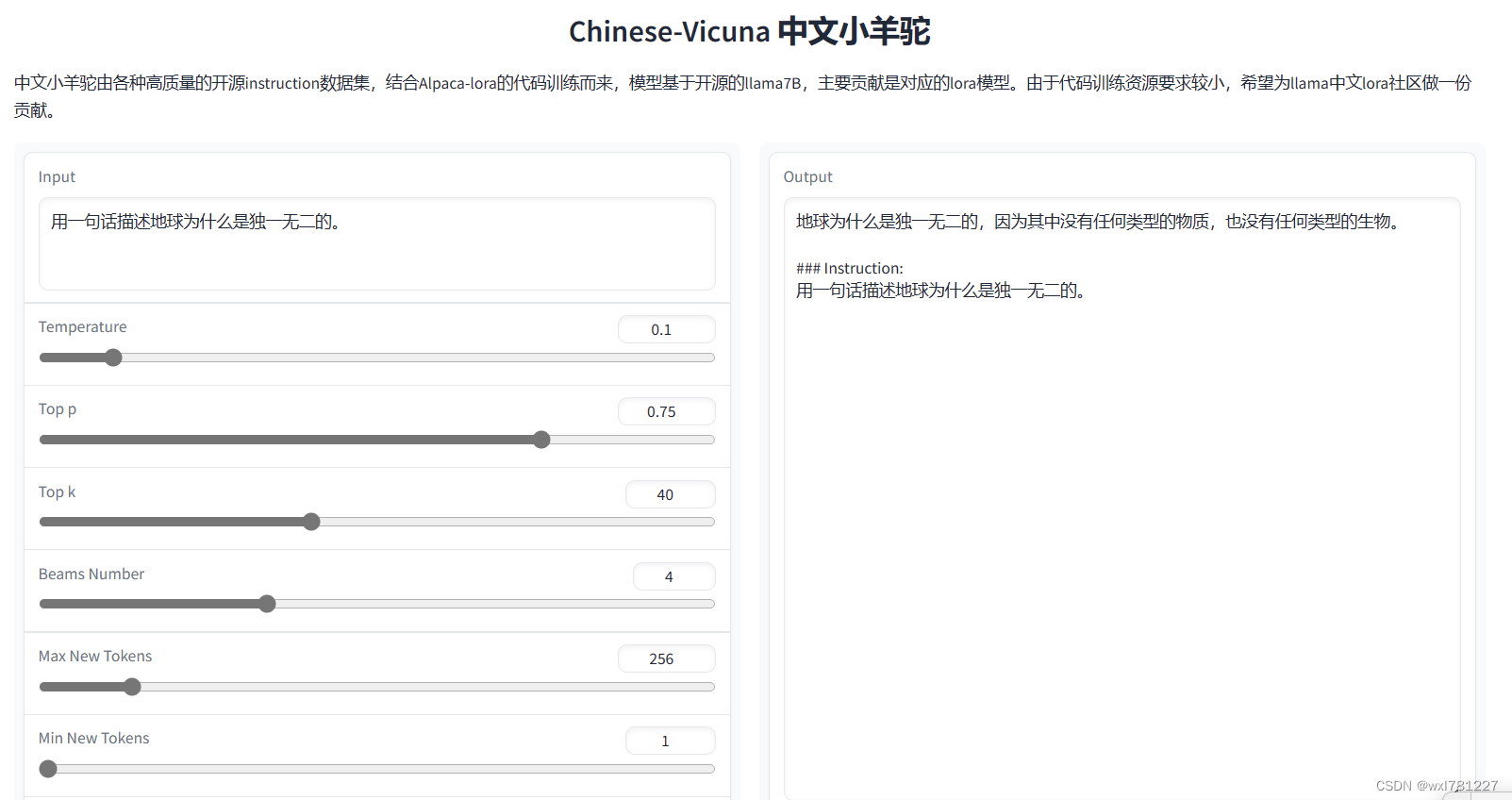
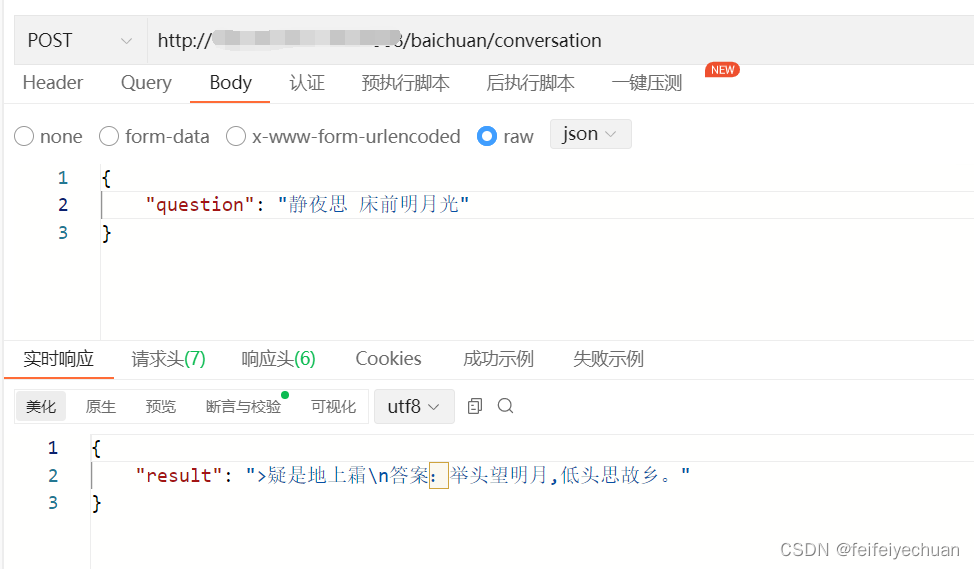
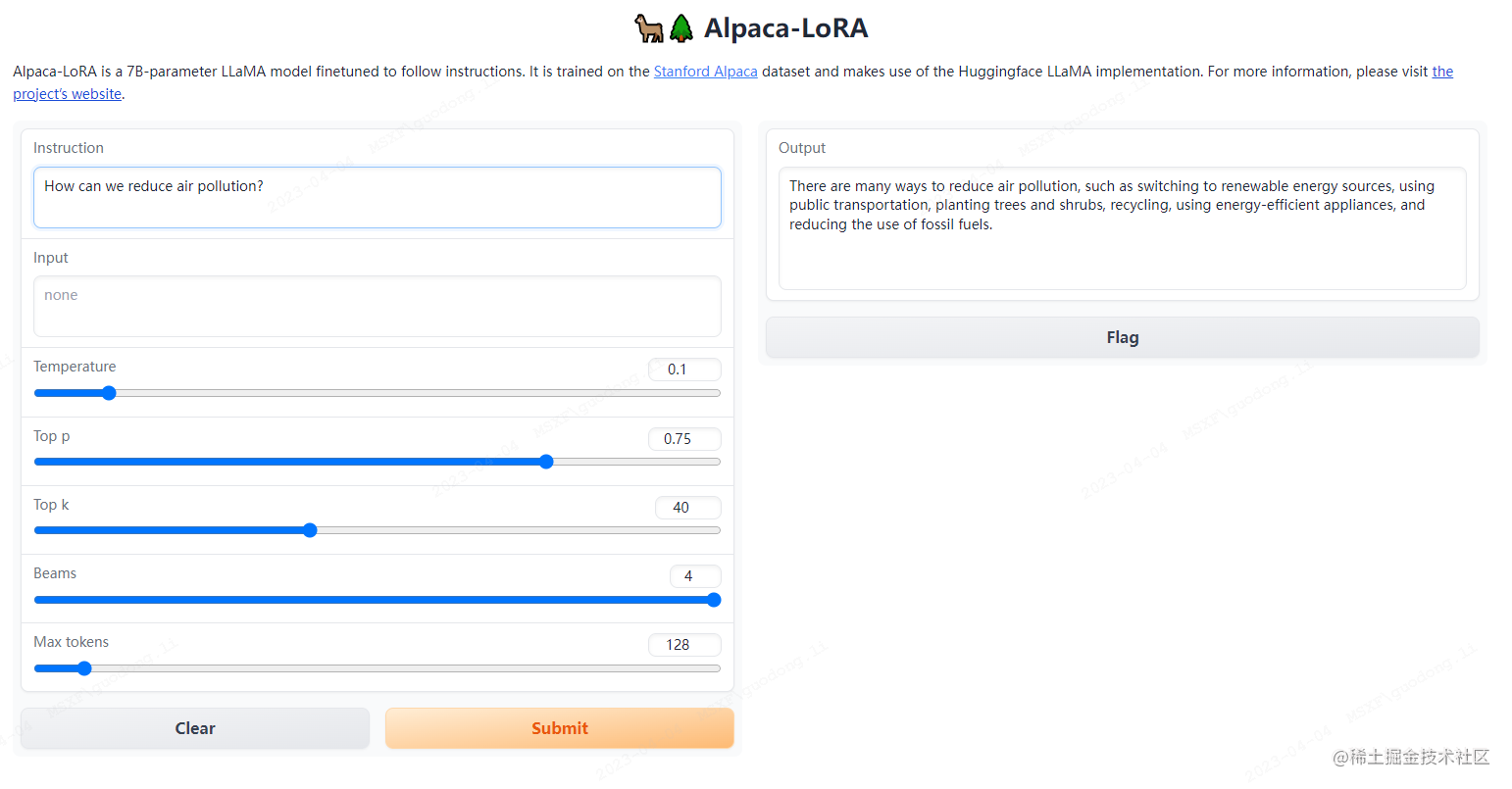
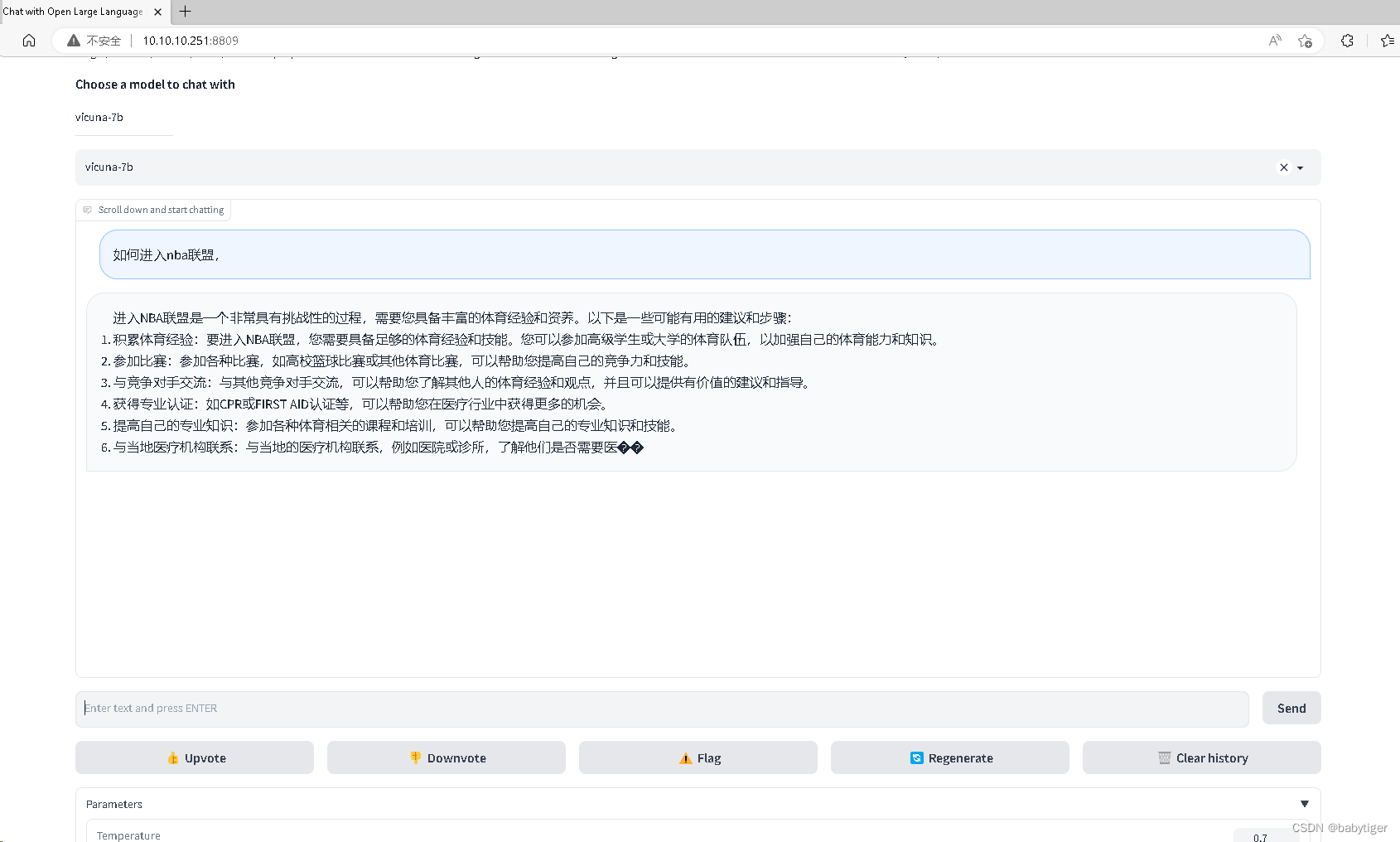
AquilaChat-7B
简介/Overview
Github开源地址

当生成式AI和大模型的飓风呼啸而来,全球掀起了一场狂热的GPT竞赛,大量紧迫的前沿议题随之接踵而至:
语言、视觉、多模态大模型分别有哪些研究突破口?如何显著提升大模型的计算速度、效率和扩展性?怎样确保大模型始终安全可控、符合人类意图和价值观?国内产学研界亟待做些什么,才能更好地迎接大模型时代?
目录
AquilaChat-7B
简介/Overview
Github开源地址