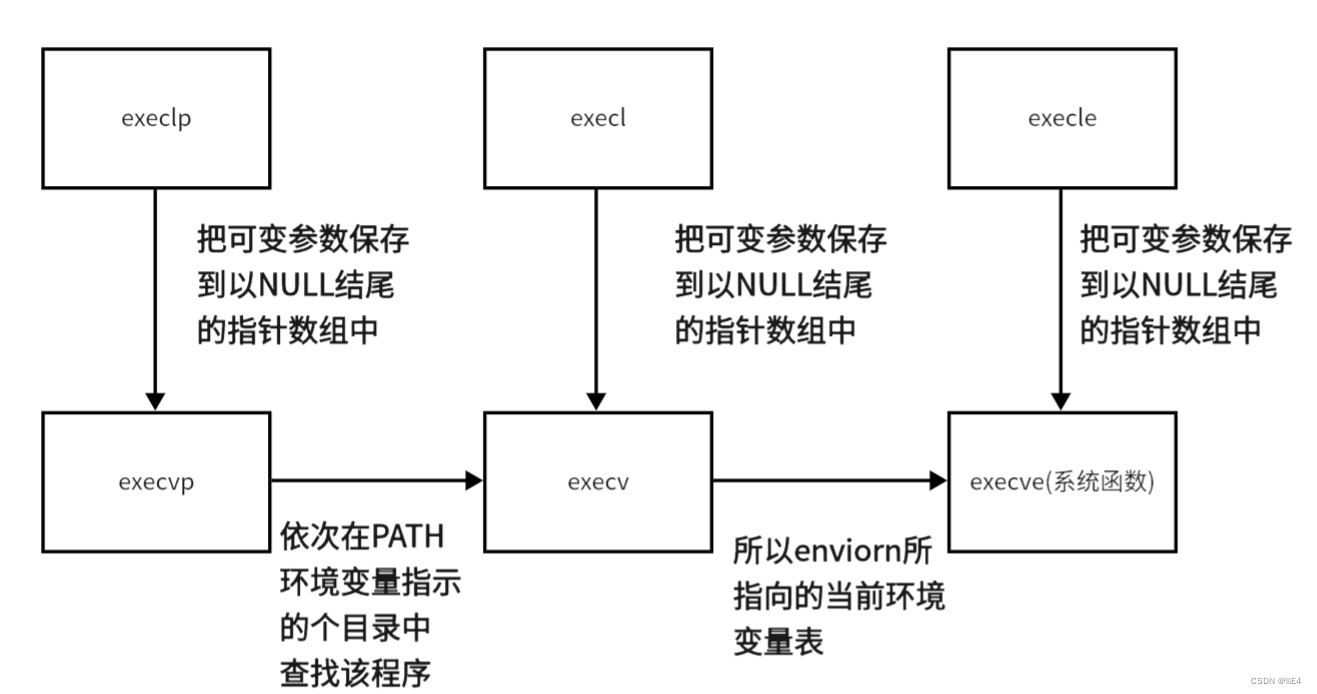
1.所有权的传递
适用移动语义可以将一个unique_lock赋值给另一个unique_lock,适用move实现。
void myThread1()
{unique_lock<mutex> myUnique (testMutex1,std::defer_lock);unique_lock<mutex>myUnique1(std::move(myUnique));//myUnique 则实效 myUnique1 相当于原来的myUnique
}std::lock_guard<std::mutex>(testMutex1,std::adopt_lock); 加上了std::adopt_lock就是lock_guard不会再次加锁了。
2.可多次lock的锁 std::recursive_mutex
工程中难免有多个地方要加锁,如果存在交叉调用则会出现异常,递归独占互斥量 std::recursive_mutex 可解决这个问题。
- 就像互斥锁(mutex)一样,递归互斥锁(recursive_mutex)是可锁定的对象,但它允许同一线程获得对互斥锁对象的多级所有权(多次lock)。
- 这允许从已经锁定它的线程锁定(或尝试锁定)互斥对象,从而获得对互斥对象的新所有权级别:互斥对象实际上将保持对该线程的锁定,直到调用其成员 unlock 的次数与此所有权级别的次数相同。
3.std::call_once
在多线程执行中,如果希望整个生命周期仅调用一次或者变量仅初始化一次,可以适用call_once.
C++11提供了一个函数 std::call_once(标记(once_flag), 函数名);
头文件在#include <mutex>
#include <iostream>
#include <thread>
#include <string>
#include <mutex>using namespace std;std::once_flag one_flag;void myThread()//定义线程入口函数
{cout << "a value " << endl;
}int main() {std::call_once(one_flag, myThread);std::call_once(one_flag, myThread);return 0;
}看到这里可能会有些疑惑用互斥锁同样可以实现这个需求,显然互斥锁效率是要低的,因为每次使用这个线程都要上锁然后判断标记位 这样消耗的时间还会更长。
4.线程和协程
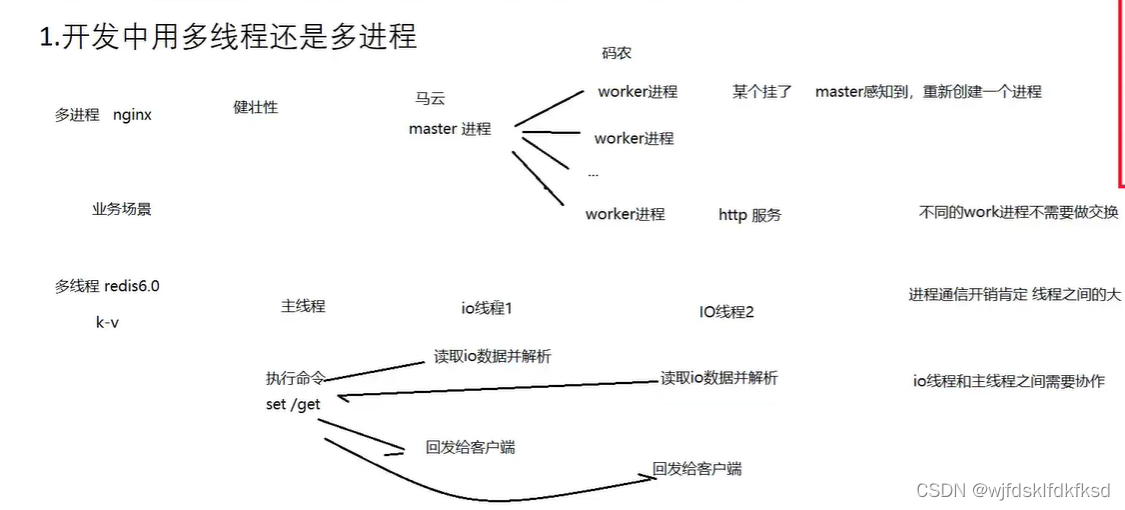


进程具有独立的内存地址空间。多个线程共用同一个地址空间。
- 每个线程有自己的栈区,寄存器。
- 多个线程共享代码段,堆区,全局数据区,打开的文件
- 共享地址空间
从操作系统层级上看,虚拟地址空间主要分为两个部分内核区和用户区。
内核区:
- 内核空间为内核保留,不允许应用程序读写该区域的内容或直接调用内核代码定义的函数。
- 内核总是驻留在内存中,是操作系统的一部分。
- 系统中所有进程对应的虚拟地址空间的内核区都会映射到同一块物理内存上(系统内核只有一个)。
用户区:存储用户程序运行中用到的各种数据。
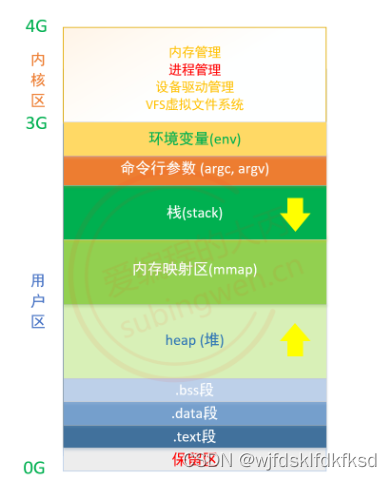
每个进程的虚拟地址空间都是从 0 地址开始的,我们在程序中打印的变量地址也其在虚拟地址空间中的地址,程序是无法直接访问物理内存的。虚拟地址空间中用户区地址范围是 0~3G,里边分为多个区块:
- 保留区: 位于虚拟地址空间的最底部,未赋予物理地址。任何对它的引用都是非法的,程序中的空指针(NULL)指向的就是这块内存地址。
- .text段: 代码段也称正文段或文本段,通常用于存放程序的执行代码 (即 CPU 执行的机器指令),代码段一般情况下是只读的,这是对执行代码的一种保护机制。
- .data段: 数据段通常用于存放程序中已初始化且初值不为 0 的全局变量和静态变量。数据段属于静态内存分配 (静态存储区),可读可写。
- .bss段: 未初始化以及初始为 0 的全局变量和静态变量,操作系统会将这些未初始化变量初始化为 0
- 堆(heap):用于存放进程运行时动态分配的内存。堆向高地址扩展 (即 “向上生长”),是不连续的内存区域。这是由于系统用链表来存储空闲内存地址,自然不连续,而链表从低地址向高地址遍历。
- 内存映射区(mmap):作为内存映射区加载磁盘文件,或者加载程序运作过程中需要调用的动态库。
- 栈(stack): 存储函数内部声明的非静态局部变量,函数参数,函数返回地址等信息,栈内存由编译器自动分配释放。栈和堆相反地址 “向下生长”,分配的内存是连续的。
- 命令行参数:存储进程执行的时候传递给 main() 函数的参数,argc,argv []
- 环境变量: 存储和进程相关的环境变量,比如:工作路径,进程所有者等信息。
线程的上下文切换比进程要快的多。切换之前保存当前任务状态。
线程的创建:
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
// Compile and link with -pthread, 线程库的名字叫pthread, 全名: libpthread.so libptread.a参数:
- thread: 传出参数,是无符号长整形数,线程创建成功,会将线程 ID 写入到这个指针指向的内存中
- attr: 线程的属性,一般情况下使用默认属性即可,写 NULL
- start_routine: 函数指针,创建出的子线程的处理动作,也就是该函数在子线程中执行。
- arg: 作为实参传递到 start_routine 指针指向的函数内部
- 返回值:线程创建成功返回 0,创建失败返回对应的错误号
// pthread_create.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>// 子线程的处理代码
void* working(void* arg)
{printf("我是子线程, 线程ID: %ld\n", pthread_self());for(int i=0; i<9; ++i){printf("child == i: = %d\n", i);}return NULL;
}int main()
{// 1. 创建一个子线程pthread_t tid;pthread_create(&tid, NULL, working, NULL);printf("子线程创建成功, 线程ID: %ld\n", tid);// 2. 子线程不会执行下边的代码, 主线程执行printf("我是主线程, 线程ID: %ld\n", pthread_self());for(int i=0; i<3; ++i){printf("i = %d\n", i);}// 休息, 休息一会儿...// sleep(1);return 0;
}
gcc pthread_create.c -lpthread
动态库名为 libpthread.so 需要使用的参数为 -l,根据规则掐头去尾最终形态应该写成:-lpthread(参数和参数值中间可以有空格)
线程退出
线程退出函数
#include <pthread.h>
void pthread_exit(void *retval);参数:线程退出的时候携带的数据,当前子线程的主线程会得到该数据。如果不需要使用,指定为 NULL
线程 | 爱编程的大丙
与临界资源相关的上下文代码块成为临界区。
死锁:枷锁后忘记解锁。重复枷锁,造成死锁。
场景描述:
1. 有两个共享资源:X, Y,X对应锁A, Y对应锁B
- 线程A访问资源X, 加锁A
- 线程B访问资源Y, 加锁B
2. 线程A要访问资源Y, 线程B要访问资源X,因为资源X和Y已经被对应的锁锁住了,因此这个两个线程被阻塞
- 线程A被锁B阻塞了, 无法打开A锁
- 线程B被锁A阻塞了, 无法打开B锁
读写锁:读锁是共享的,写锁是独占的。
调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作,调用这个函数依然可以加锁成功,因为读锁是共享的;如果读写锁已经锁定了写操作,调用这个函数的线程会被阻塞