文章目录
- 时间序列(TimeSeries)
- 执行多个聚合
- 上采样和填充值
- 通过apply传递自定义功能
- DataFrame对象
时间序列(TimeSeries)
#创建时间序列数据
rng = pd.date_range('1/1/2012', periods=300, freq='S')ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
ts2012-01-01 00:00:00 44
2012-01-01 00:00:01 54
2012-01-01 00:00:02 132
2012-01-01 00:00:03 70
2012-01-01 00:00:04 476...
2012-01-01 00:04:55 178
2012-01-01 00:04:56 83
2012-01-01 00:04:57 184
2012-01-01 00:04:58 223
2012-01-01 00:04:59 179
Freq: S, Length: 300, dtype: int32
时间频率转换的参数如下
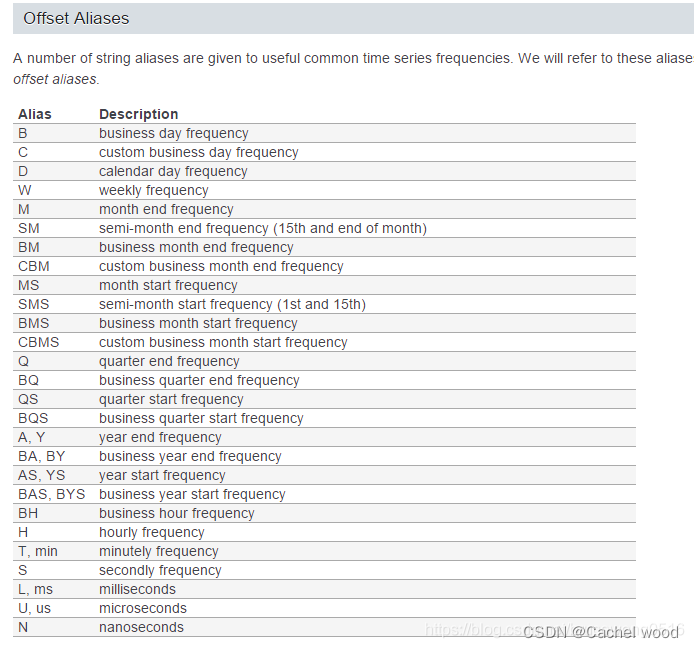
resample重采样
ts.resample('1T').sum() #按一分钟重采样之后求和
ts.resample('1T').mean() #按一分钟重采样之后求平均
ts.resample('1T').median() #按一分钟重采样之后求中位数2023-01-01 00:00:00 275.5
2023-01-01 00:01:00 245.0
2023-01-01 00:02:00 233.5
2023-01-01 00:03:00 284.0
2023-01-01 00:04:00 245.5
Freq: T, dtype: float64
执行多个聚合
使用agg函数执行多个聚合。
ts.resample('1T').agg(['min','max', 'sum'])min max sum
2023-01-01 00:00:00 0 492 15536
2023-01-01 00:01:00 3 489 15840
2023-01-01 00:02:00 3 466 14282
2023-01-01 00:03:00 2 498 15652
2023-01-01 00:04:00 6 489 15119
上采样和填充值
上采样是下采样的相反操作。它将时间序列数据重新采样到一个更小的时间框架。例如,从小时到分钟,从年到天。结果将增加行数,并且附加的行值默认为NaN。内置的方法ffill()和bfill()通常用于执行前向填充或后向填充来替代NaN。
rng = pd.date_range('1/1/2023', periods=200, freq='H')ts = pd.Series(np.random.randint(0, 200, len(rng)), index=rng)
ts2023-01-01 00:00:00 16
2023-01-01 01:00:00 19
2023-01-01 02:00:00 170
2023-01-01 03:00:00 66
2023-01-01 04:00:00 33...
2023-01-09 03:00:00 31
2023-01-09 04:00:00 61
2023-01-09 05:00:00 28
2023-01-09 06:00:00 67
2023-01-09 07:00:00 137
Freq: H, Length: 200, dtype: int32
#下采样到分钟
ts.resample('30T').asfreq()2023-01-01 00:00:00 16.0
2023-01-01 00:30:00 NaN
2023-01-01 01:00:00 19.0
2023-01-01 01:30:00 NaN
2023-01-01 02:00:00 170.0...
2023-01-09 05:00:00 28.0
2023-01-09 05:30:00 NaN
2023-01-09 06:00:00 67.0
2023-01-09 06:30:00 NaN
2023-01-09 07:00:00 137.0
Freq: 30T, Length: 399, dtype: float64
通过apply传递自定义功能
import numpy as npdef res(series):return np.prod(series)ts.resample('30T').apply(res)2023-01-01 00:00:00 16
2023-01-01 00:30:00 1
2023-01-01 01:00:00 19
2023-01-01 01:30:00 1
2023-01-01 02:00:00 170...
2023-01-09 05:00:00 28
2023-01-09 05:30:00 1
2023-01-09 06:00:00 67
2023-01-09 06:30:00 1
2023-01-09 07:00:00 137
Freq: 30T, Length: 399, dtype: int32
DataFrame对象
对于DataFrame对象,关键字on可用于指定列而不是重新取样的索引
df = pd.DataFrame(data=9*[range(4)], columns=['a', 'b', 'c', 'd'])
df['time'] = pd.date_range('1/1/2000', periods=9, freq='T')
df.resample('3T', on='time').sum()Out[81]: a b c d
time
2000-01-01 00:00:00 0 3 6 9
2000-01-01 00:03:00 0 3 6 9
2000-01-01 00:06:00 0 3 6 9

![[2023-DAS x SU战队2023开局之战] crypto-sign1n](https://img-blog.csdnimg.cn/ffaa9d0b9f984ad889432e4da1d052cb.png)

