3D车道线检测:Gen-LaneNet
Gen-LaneNet: A Generalized and Scalable Approach for 3D Lane
Detection
论文链接:https://arxiv.org/abs/2003.10656
摘要
提出了一种广义的、可扩展的方法,称为Gen-LaneNet,用于从单个图像中检测3D车道。该方法受到最新最先进的3D LaneNet的启发,是一个统一的框架,可在单个网络中解决图像编码、特征空间变换和3D车道预测。这个设计方案复杂度为Gen-LaneNet两倍。首先,在一个新的坐标系中引入一种新的几何引导车道锚定表示,并应用特定的几何变换直接从网络输出中计算出真实的三维车道点。将车道点与新坐标系中的基础俯视图特征对齐对于处理不熟悉场景的通用方法至关重要。其次,提出了一个可扩展的两阶段框架,该框架将图像分割子网和几何编码子网的学习分离开来。与3D-LaneNet相比,本文提出的Gen-LaneNet大大减少了在实际应用中实现稳健解决方案所需的3D车道标签数量。此外,还发布了一个新的合成数据集及其构建策略,以鼓励开发和评估三维车道检测方法。在实验中,进行了广泛的消融研究,以证实所提出的Gen-LaneNet在平均精度(AP)和F评分方面明显优于3D-LaneNet。
- 论文主要创新点
本文提出了一种通用的、可扩展的三维车道检测方法3D-LaneNet。在新的坐标系中引入了一种新的几何导向车道锚定表示设计,并应用特定的几何变换直接从网络输出计算出真实的三维车道点。将锚与俯视图特征对齐,可推广到未观察到的场景。提出了一个可扩展的两阶段框架,允许图像分割子网和几何编码子网的独立学习,这大大减少了学习所需的3D标签的数量。得益于廉价的二维数据,昂贵的三维标签局限于某些视觉变化,两阶段框架优于端到端学习框架。最后,提出了一个具有丰富视觉变化的高逼真度图像合成数据集,为三维车道检测的发展和评价服务。在实验中,进行了广泛的消融研究,以证实LaneNet基因在AP和F评分方面显著优于先前的最新水平[6],在一些测试集中高达13%。

- Gen-LaneNet
首先,3D LaneNet在锚定表示中使用了一个不合适的坐标系,其中地面真实车道与视觉特征不一致。这在丘陵道路场景中最为明显,如图2顶行所示,投影到虚拟俯视图的平行车道看起来是非平行的。三维坐标系中的地面真实车道(蓝线)与基础视觉特征(白色车道标记)不对齐。训练一个模型来对抗这种“垃圾”的基本事实可能会迫使该模型学习整个场景的全局编码。该模型很难推广到与训练中观察到的场景部分不同的新场景。
由于端到端学习网络将三维几何推理与图像编码紧密结合,使得几何编码不可避免地受到图像外观变化的影响。3D LaneNet可能需要成倍增加的训练数据量,以便在存在部分遮挡、变化的照明或天气条件下产生相同的3D几何体。标记3D车道要比标记2D车道贵得多。它通常需要建立在昂贵的多传感器(激光雷达、摄像机等)上的高分辨率地图、精确的定位和在线校准,以及在3D空间中更昂贵的手动调整来产生正确的地面真实感。这些限制阻止了3D LaneNet在实际应用中的可伸缩性。

Geometry in 3D Lane Detection
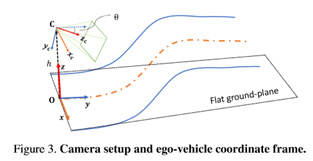
回顾几何学,以建立理论激励我们的方法。在如图3所示的普通车辆摄像机设置中,3D车道在由x、y、z轴和或数字O定义的ego车辆坐标框中表示。定义了摄像机中心在道路上的垂直投影。在简单的设置之后,用摄像机高度h和俯仰角θ来表示摄像机姿态,建立由xc、yc、zc轴和原点C定义的摄像机坐标框架。先通过投影变换将3D场景投影到图像平面,然后将捕获的图像投影到平面道路平面。由于涉及摄像机参数,虚拟俯视图中的点原则上与ego车辆系统中相应的3D点相比具有不同的x、y值。本文将虚拟顶视图形式化地看作一个由x、y、z轴和原O轴定义的唯一坐标系,并推导了虚拟顶视图坐标系与ego车辆坐标系之间的几何变换。


根据所提出的几何模型,分两步来解决三维车道检测问题:
首先应用网络对图像进行编码,将特征转换为虚拟俯视图,并预测虚拟俯视图中表示的车道点;
然后采用几何变换计算ego车辆坐标系中的三维车道点,如图6所示。方程式2原则上保证了这种方法的可行性,因为几何变换与相机角度无关。这是确保方法不受摄像机姿态估计影响的一个重要事实。
与3D LaneNet[6]类似,开发了锚定表示,这样网络可以直接以多段线的形式预测3D车道。锚点表示实际上是结构化场景中边界检测和轮廓分组的网络实现的本质。如图5所示,车道锚定被定义为x位置的N条等距垂直线。

- 实验测试
数据集设置:
为了从不同的角度评估算法,设计了三种不同的规则来分割合成数据集:
(1)平衡场景:
训练和测试集遵循整个数据集的五倍标准分割,用大量无偏数据对算法进行基准测试。
(2)很少观察到的场景:
此数据集分割包含与平衡场景相同的训练数据,但仅使用从复杂城市地图捕获的测试数据的子集。此数据集分割旨在检查方法对很少从训练中观察到的测试数据的泛化能力。由于测试图像在不同的位置呈现稀疏,涉及到剧烈的高程变化和急转,因此很少从训练数据中观察到测试数据中的场景。
(3)具有视觉变化的场景:
与昂贵的三维数据相比,这种数据集分割在光照变化的情况下评估方法,因为与昂贵的三维数据相比,使用更经济的二维数据可以覆盖相同区域的光照变化。具体来说,在我们的Gen-LaneNet的第一阶段,使用与平衡场景相同的训练集训练图像分割子网。然而,在某一天,也就是黎明前,本文的方法(3DGeoNet)和3D LaneNet的3D几何子网的训练中排除了3D示例。在测试中,只使用与排除的时间相对应的示例。

与文献[6]相比,我们首先证明了所提出的几何导向锚表示的优越性。对于每种候选方法,我们都保持体系结构完全相同,只不过锚表示是集成的。如表1所示,无论是端到端的3D LaneNet[6]、“理论上存在的”3D GeoNet,还是我们的两阶段Gen-LaneNet,这三种方法都从新锚设计中受益匪浅。在数据集的所有分割中,AP和F-score都实现了3%到10%的改进。

用两阶段Gen-LaneNet与先前最先进的3D LaneNet之间的整个系统比较来结束实验[6]。如表3所示,对数据集的所有三个部分进行了苹果与苹果的比较。在平衡的场景中,3D LaneNet效果很好,但是Gen-LaneNet仍然实现了0.8%的AP和1.7%的F分数提高。考虑到这种数据分割在训练数据和测试数据之间很好地平衡,并且覆盖了各种场景,这意味着所提出的Gen-LaneNet在各种场景下有更好的泛化能力;
在很少的情况下观察到的场景,本方法AP和F评分分别提高了6%和4.4%,证明了本方法在遇到不常见的测试场景时具有很好的鲁棒性;
最后,在有视觉变化的场景中,本方法在F评分和AP上显著地超过了3D LaneNet约13%,这表明我们的两阶段算法图像编码的解耦学习和三维几何推理的成功应用。
对于特定场景,可以在图像中标注更经济的二维车道,以训练一般的分割子网,同时标记有限数量昂贵的三维车道训练三维车道几何。这使得本方法在实际应用中更具可伸缩性。除了F分数和AP,近距离(0-40米)和远距离(40-100米)分别报告了这些匹配车道上米的误差(欧氏距离)。正如所观察到的,Gen-LaneNet保持较低的误差或与3D LaneNet相当,甚至涉及更多的匹配车道。
- Conclusion
提出了一种通用的、可扩展的三维车道检测方法Gen-LaneNet。介绍了一种几何导向锚定表示方法,并提出了一种两阶段的图像分割学习和三维车道预测解耦框架。此外,我们还提出了一种新的策略来构建三维车道检测的合成数据集。实验证明,本方法在AP和F评分方面都明显优于3D-LaneNet。


![Showstopper [POJ3484] [二分] [思维]](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)




