2023年的深度学习入门指南(12) - PEFT与LoRA
大家都知道,大模型的训练需要海量的算力。其实,即使是只对大模型做微调训练,也是需要大量的计算资源的。
有没有用更少的计算资源来进行微调的方法呢?研究者研发出了几种被Hugging Face统称为参数高效微调PEFT(Parameter-Efficient Fine-Tuning)的技术。
这其中常用的几个大家应该已经耳熟能详了,比如广泛应用的LoRA技术(Low Rank Adapters,低秩适配),Prefix Tuning技术,Prompt Tuning技术等等。
我们先学习如何使用,然后我们再学习其背后的原理。
用Huggingface PEFT库进行低秩适配
首先我们先安装相关的库,主要有量化用的bitsandbytes库,低秩适配器loralib库,以及加速库accelerate。
另外,PEFT库和transformers库都用最新的版本。
pip install -q bitsandbytes datasets accelerate loralib
pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git
我们来尝试训练一个7B左左的模型,我们选用opt-6.7b模型,它以float16的精度存储,大小大约为13GB!如果我们使用bitsandbytes库以8位加载它们,我们需要大约7GB的显存。
但是,这只是加载用的,在实际训练的时候,16G显存都照样不够用。最终的消耗大约在20G左右。
加载大模型仍然使用我们前面学过的AutoModelForCausalLM.from_pretrained()函数,只是我们需要加上load_in_8bit=True参数来调用bitsandbytes库进行8位量化。
import osos.environ["CUDA_VISIBLE_DEVICES"] = "0"
import torch
import torch.nn as nn
import bitsandbytes as bnb
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("facebook/opt-6.7b",load_in_8bit=True,device_map="auto",
)tokenizer = AutoTokenizer.from_pretrained("facebook/opt-6.7b")
下面PEFT就正式出场了,我们先针对所有非int8的模块进行预处理以提升精度:
from peft import prepare_model_for_int8_trainingmodel = prepare_model_for_int8_training(model)
我们再配置下LoRA的参数,参数的具体含义我们后面结合原理再讲。
from peft import LoraConfig, get_peft_modelconfig = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM"
)model = get_peft_model(model, config)
我们选用名人名言数据集作为训练数据:
from datasets import load_datasetdata = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
然后就可以开始训练了:
trainer = transformers.Trainer(model=model,train_dataset=data["train"],args=transformers.TrainingArguments(per_device_train_batch_size=4,gradient_accumulation_steps=4,warmup_steps=100,max_steps=200,learning_rate=2e-4,fp16=True,logging_steps=1,output_dir="outputs",),data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()
最后,我们做一个推理测试下效果:
batch = tokenizer("Two things are infinite: ", return_tensors="pt")with torch.cuda.amp.autocast():output_tokens = model.generate(**batch, max_new_tokens=50)print("\n\n", tokenizer.decode(output_tokens[0], skip_special_tokens=True))
输出的结果如下:
Two things are infinite: the universe and human stupidity; and I'm not sure about the universe. -Albert Einstein
I'm not sure about the universe either.
基本上,我们除了配置了一个LoRA参数之外什么也没干。
LoRA的原理
LoRA的思想是将原始的权重矩阵分解为两个低秩矩阵的乘积,这样就可以大大减少参数量。其本质思想还是将复杂的问题拆解为简单的问题的组合。
LoRA通过注入优化后的秩分解矩阵,将预训练模型参数冻结,减少了下游任务的可训练参数数量,使得训练更加高效。并且在使用适应性优化器时,降低了硬件进入门槛。
因为我们不需要计算大多数参数的梯度或维护优化器状态,而是仅优化注入的、远小于原参数量的秩分解矩阵。
光定量地这么讲,大家没有观感,我们以上面训练的例子来看看LoRA的效果。
我们写一个函数来计算模型中的可训练参数数量:
def print_trainable_parameters(model):"""Prints the number of trainable parameters in the model."""trainable_params = 0all_param = 0for _, param in model.named_parameters():all_param += param.numel()if param.requires_grad:trainable_params += param.numel()print(f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}")
运行一下:
print_trainable_parameters(model)
输出结果如下:
trainable params: 8388608 || all params: 6666862592 || trainable%: 0.12582542214183376
我们看到,原始的模型参数有66亿多个,但是我们只训练了838多万个,只占了0.125%。
所以这也就是为什么我们经常看到有6b,7b,还有13b参数的大模型了。因为这个量级的模型,刚好可以在一张40G或者80G的A100显卡上训练。甚至在24G的3090上也能训练。
下面我们来解释一下低秩更新的原理。
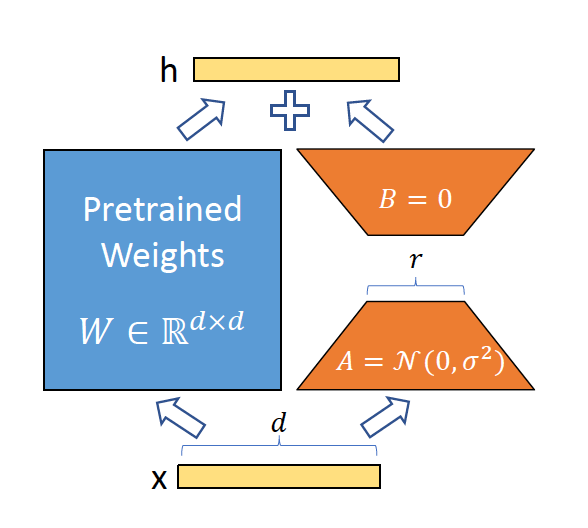
如图所示,输入为x,x是d维的向量,输出是h。
我们将参数分为冻结的权重 W 0 W_0 W0和可以训练的参数 Δ W \Delta W ΔW。然后我们把 Δ W \Delta W ΔW分解成A和B两个可训练参数的矩阵,其中A矩阵取随机值,而B矩阵全取0.
h = W 0 x + Δ W x = W 0 x + B A x h=W_0 x+\Delta W x=W_0 x+B A x h=W0x+ΔWx=W0x+BAx
其中, W 0 W_0 W0是一个d乘以r维的矩阵, W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k
为了让B乘以A的结果为输入是d维而输出为k维,B矩阵我们取d行r列,而A矩阵为r行k列,这样一相乘就是d行k列:
B ∈ R d × r , A ∈ R r × k B \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k} B∈Rd×r,A∈Rr×k
为了让低秩后的效果更好,r要取一个远小于d和k的值。
为了减少更换r给训练带来的影响,我们再引入一个缩放参数 α \alpha α。我们给 Δ W x \Delta W x ΔWx乘以 α r \frac{\alpha}{r} rα。当使用Adam优化时,如果我们适当地缩放初始化,调整α就大致相当于调整学习率。因此,我们简单地将α设置为我们尝试的第一个r,并不对其进行调整。这种缩放有助于减少在改变r时重新调整超参数的需要。
我们来参照一下前面配置的LoRA config:
from peft import LoraConfig, get_peft_modelconfig = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM"
)model = get_peft_model(model, config)
我们可以看到,r选择的是16,而alpha为32。说明最开始是用32作为r来进行尝试的。后面我们再调参数的时候,就改r而不调整alpha了。
那么,我们为什么只选择了q和v两个参数进行LoRA呢?
我们来看论文中的数据:
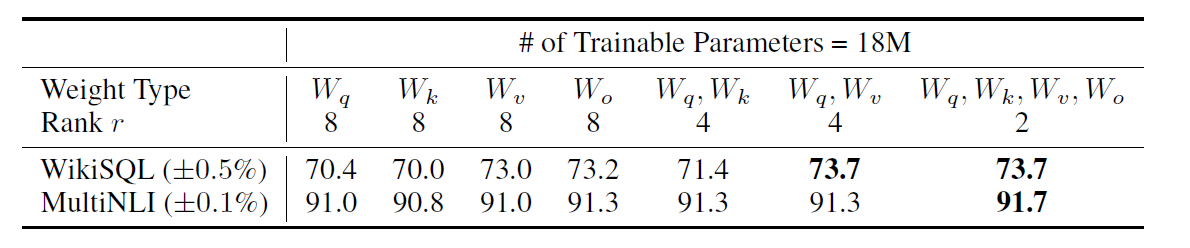
取q和k两组参数的效果,还不如只取v一个的效果好。而把q,k,v,o全都训练了,也没有明显的优势。所以就取相对最有效率的q,v两组。
当然,这也不是金科玉律,大家可以在实践中去探索更好的LoRA策略。
小结
LoRA的一个例子就是alpaca-lora项目,其网址为:https://github.com/tloen/alpaca-lora
alpaca-lora是一个使用LoRA技术对Alpaca模型进行轻量化的项目。Alpaca模型是一个基于LLaMA 7B模型的聊天机器人,使用了Instruct数据集进行微调。alpaca-lora的优点是可以在低成本和低资源的情况下,获得与Alpaca模型相当的效果,并且可以在MacBook、Google Colab、Raspberry Pi等设备上运行。alpaca-lora使用了Hugging Face的PEFT和bitsandbytes来加速微调过程,并提供了一个脚本来下载和推理基础模型和LoRA模型。
现在,PEFT和LoRA对我们来说,已经不再陌生了。