qq技术群,一群逗比天天不聊技术,都在摸鱼,未读消息动不动就99+,丝毫不考虑我这电脑内存小的怎么办。来,让我们看看这群逗比群友整天都在聊什么。
一、导出QQ聊天文件
手机上或者Mac上的QQ数据库是加密的,但是手机备份出来的却是明文的数据,所以我们直接用最简单的,从备份拿数据,我这里用爱思助手搞了。
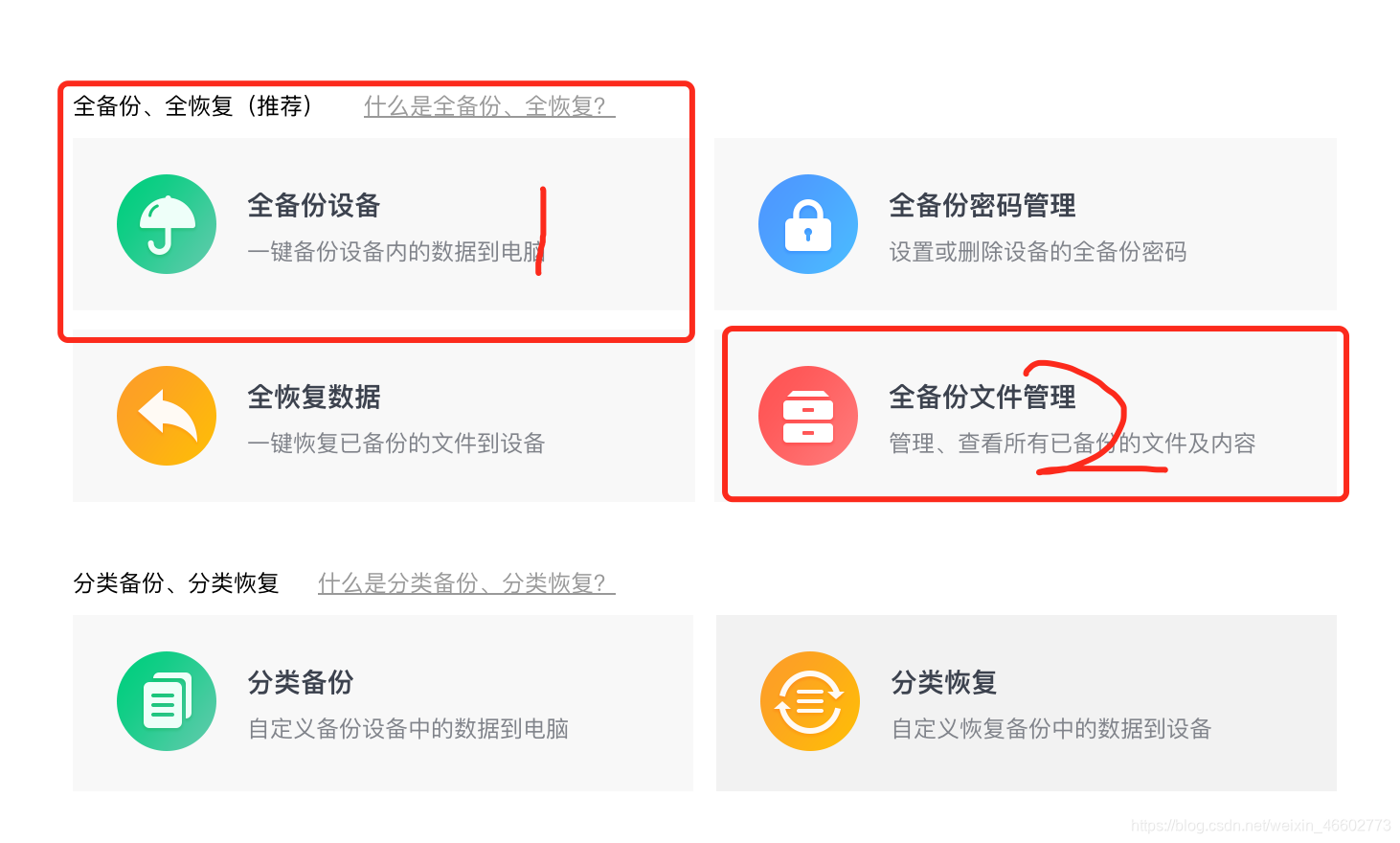
- 打开爱思助手然后点击 工具箱->备份/恢复数据->选择全备份,然后等几分钟备份完成,打开全备份文件管理。
- 点击立即查看
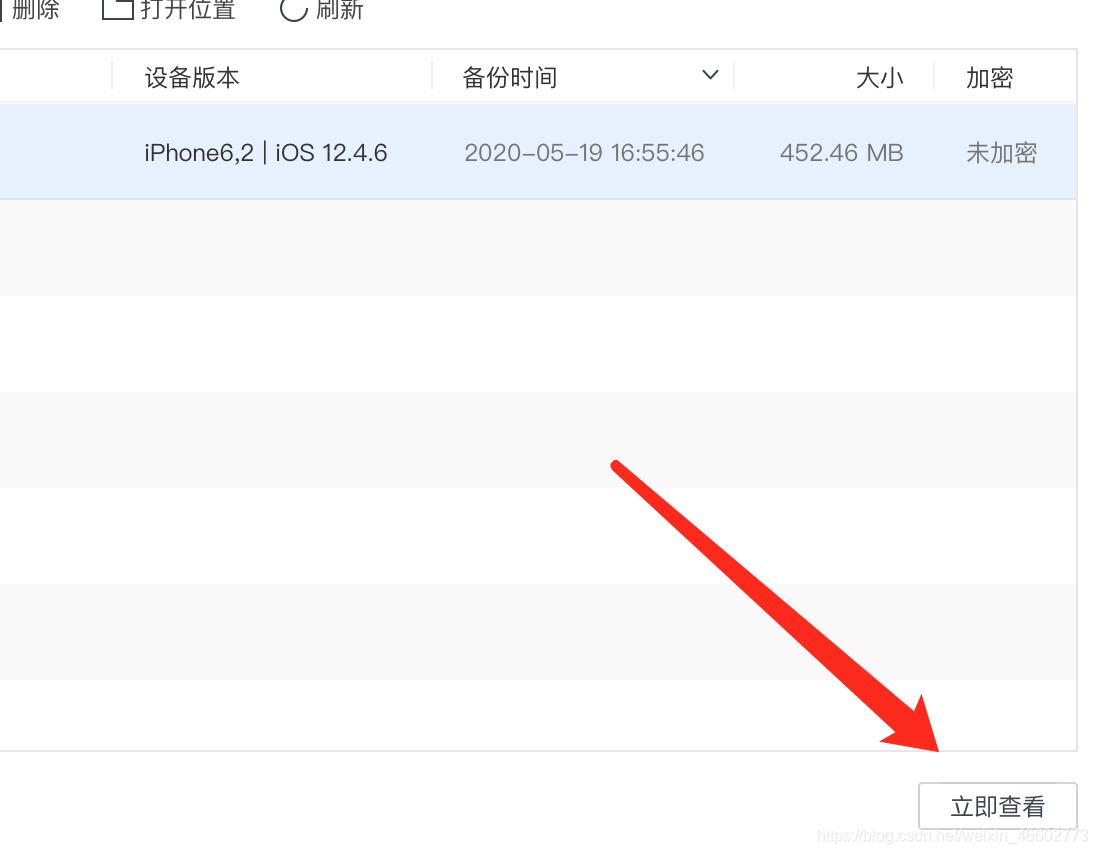
- 列表有一个
APPDomain-com.tencent.mqq的文件夹 ,账号数据路径为/AppDomain-com.tencent.mqq/Documents/contents/xxQQ账号xxx/QQ.db - 然后用支持SQlite的软件 Navicat Premium 或者 DB Browser for SQLite打开QQ.db。
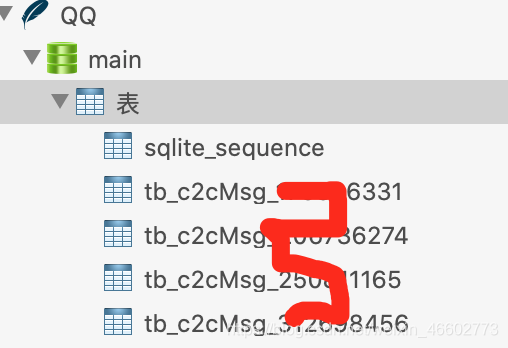
- 其中表名为tb_c2cMsg_xxxxQQ账号xxx的表,是单对单的聊天信息,tb_TroopMsg_xxx群号xxx的表,是群聊天的记录。
- 我们就选话最多的那个群号,然后找出来对应的表,选择导出全部数据。
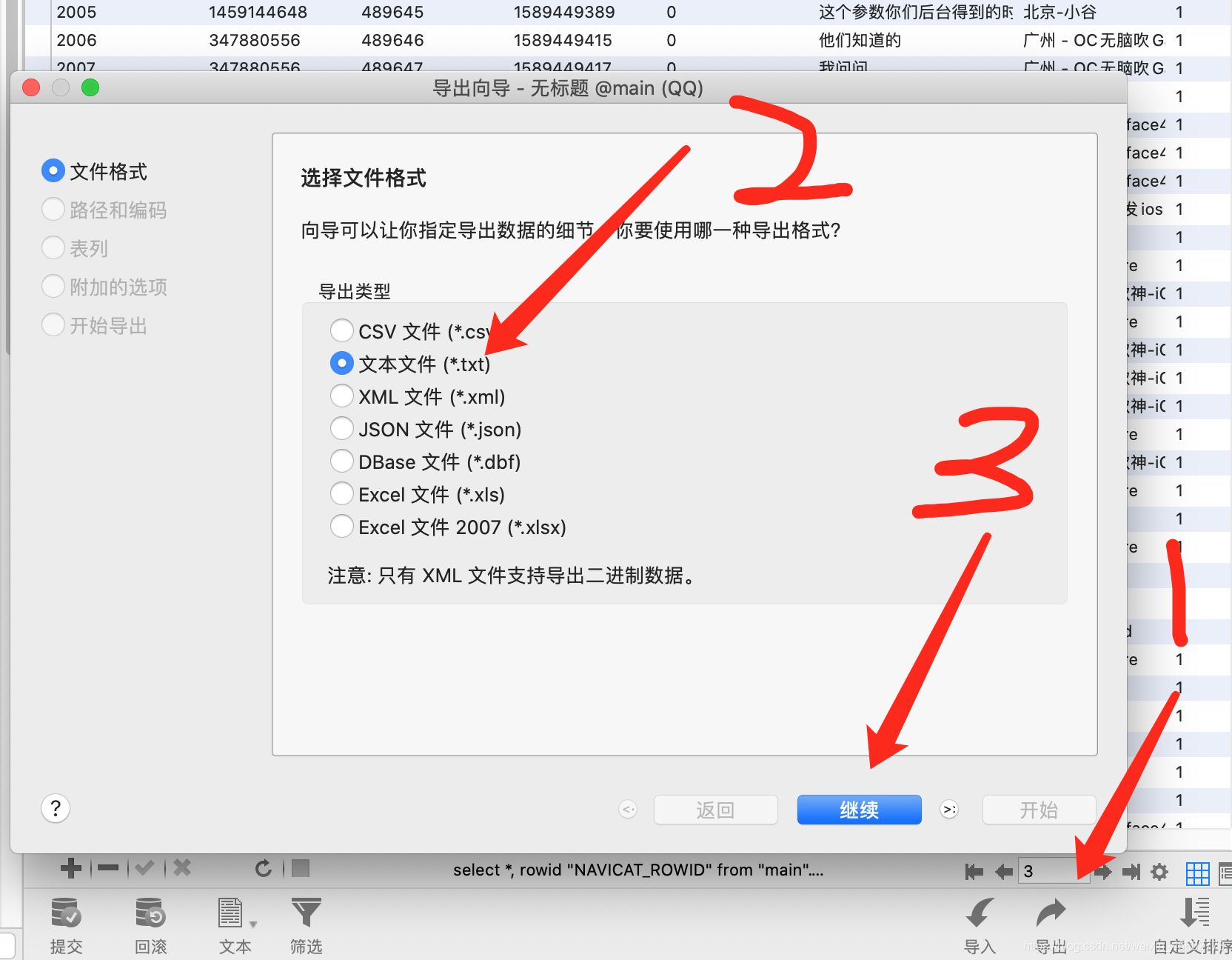
7.编码选择UTF-8,导出字段不用选择全部字段,只用选择strMsg字段,然后一直点击下一步就可以了。
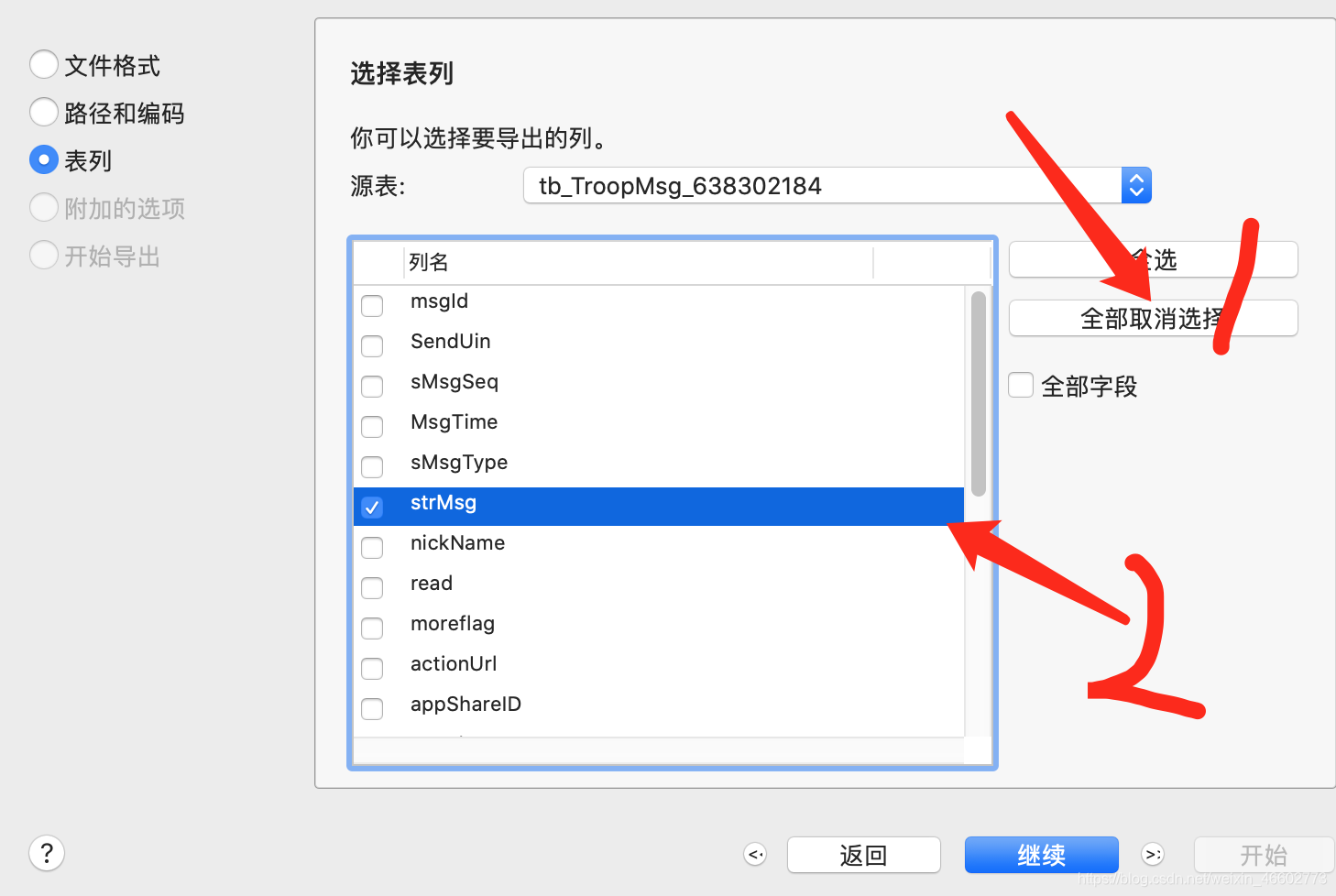
8.导出成功
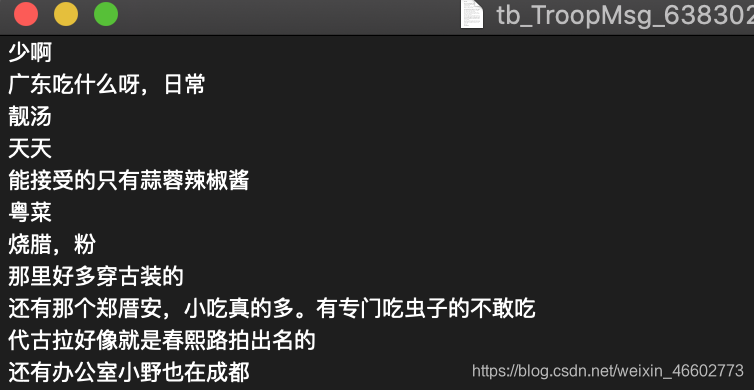
二、jieba分词
import jieba
import re# 对聊天记录文件进行分词
def cut_words():# 把聊天内容读取给contentfp = open("qqjilu.txt", "r", encoding="utf-8")content = fp.read()fp.close()#过滤img标签content=re.compile('<\s*img[^>]*>[^<]*<\s*/\s*img\s*>',re.I).sub('',content)#将br转换为换行jieba.enable_paddle()jieba.load_userdict("dict.txt")words = jieba.cut(content, cut_all=False) # 使用精确模式对文本进行分词counts = {} # 通过键值对的形式存储词语及其出现的次数for word in words:if len(word) == 1: # 单个词语不计算在内continueelse:counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1items = list(counts.items())#将键值对转换成列表items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序for i in range(15):word, count = items[i]print("{0:<5}{1:>5}".format(word, count))if __name__ == "__main__":cut_words()
打印结果:
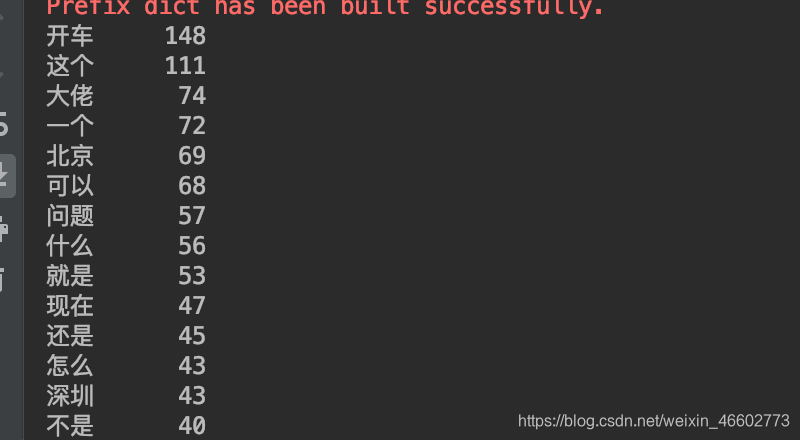
三、总结
一群逗比群友,天天不敲代码,只知道开车。