專 欄

伟楠,Python中文社区专栏作者,数据分析师,知乎专栏:数据故事会。
https://www.zhihu.com/people/hao-wei-nan
❈前段时间上映的《羞羞的铁拳》可谓是票房大丰收啊,截止到我写这篇文章时,我看了眼猫眼的数据,票房已经21.7亿了。这也使它成为继《战狼2》、《美人鱼》和《捉妖记》后第四部票房过 20 亿的国产电影,在国内票房史上排第6位啊啊啊~

猫眼数据
那么面对这么一部票房收割机,投资人肯定是笑的合不拢腿【大雾】嘴了,那么我不禁想问,观众呢,观众到底对这部电影怎么看。要知道很多电影那可是票房高涨口碑垫底啊,比如说.....算了不说了,我怕他们粉丝打我....(逃
为了搞清楚到底观众是怎么看待这部电影的,而刚好我的好基友 @Marco Zhang 又说最近他想研究研究爬虫,那可真是太好了,又省的自己爬了,全部拜托他搞定。(而且他还说他想写一篇爬虫的文章,虽然我表示不知道啥时候能等到)
选择从豆瓣上爬取数据,原因是豆瓣有星级的指标,这对于我们在Part 2做情感分类时有巨大帮助啊。(情感分类本质上是一个有监督学习的分类问题)
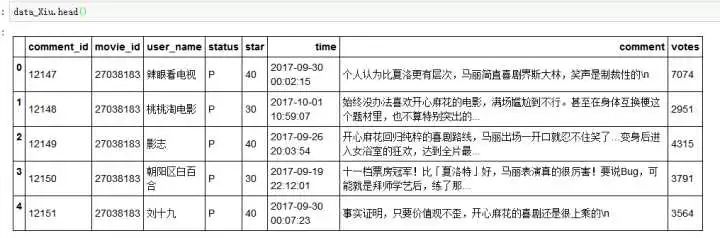
嗯,截止到爬取之日,共爬取77726条评论(对的,没有8万,我四舍五入下了,主要是标题这样好听些),大体格式如下:
那么开始干活吧~
一、 特征预处理
导入数据

除了《羞羞的铁拳》同时还爬取了开心麻花另外两部电影《夏洛特烦恼》和《驴得水》,留待后面做情感分析时的训练样本。
(这里不得不吐槽下,好像最新的Python (3.6.1)下在用Pandas读取csv文件的时候,如果直接用 pd.read_csv() 的话会报错,必须要做如上处理才行(与中文路径无关,我测试过了),但是神奇的是用pd.read_excel()读取Excel文件就不会报错。还望知道怎么回事的大神,不吝赐教啊~~~ )
处理缺失值
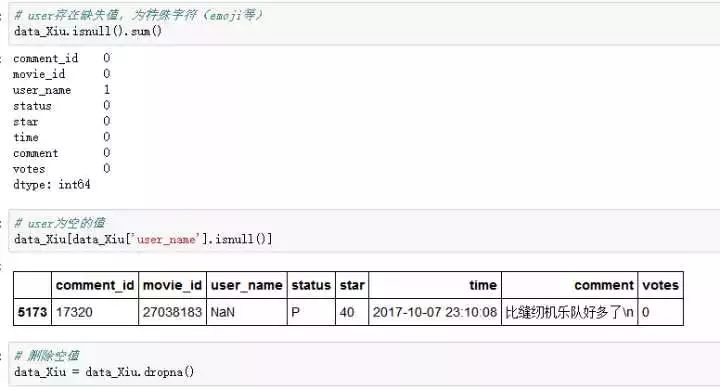
数据还是非常干净的,只有"user_name"有一个缺失值,可能是这名用户的用户名含有什么emoji之类的特殊字符吧~
对于缺失值的处理,我们一般可以采取以下方式
1、删除缺失值
2、填充缺失数据(均值等)
3、机器学习预测缺失值
如果缺失的数据不多,可以直接删掉,但是如果缺失的数据比较多,那这样做可能会删除过多的样本,导致分析结果可靠性不高。如果删除过多特征列的话则会导致面临丢失有价值信息的风险。而填充数据的话,最常用的就是插值技术,可以插均值、中位数或最高频词等。当然更复杂的你也可以用机器学习建模,来预测下缺失值。
不过对于我这次源数据有将近8万条,所以这条就直接删除了,影响不大。不过查看了下这条数据,其实有价值的信息都还在,直接给他随便补个名字也没问题。
二、 EDA
好了,我们常说用户一向“用脚投票”(当然这里没有恶意),一部电影好看不好看最直观的就是看观众的评分了。电影拍得好,观众买账,自然评分高;拍得烂片,观众觉得这钱花的不值,既浪费钱有浪费时间,自然打个低分,再正常不过了。
各星级评分人数
那么我们首先就先来看看,不同星级之间打分人数的分布吧。其中0星要特别说一下,这些是标记了想看但是还没看的用户,我们可以认为这些用户是对这部片子有好感的,至少是感兴趣的。(对,你成功引起我的注意了)

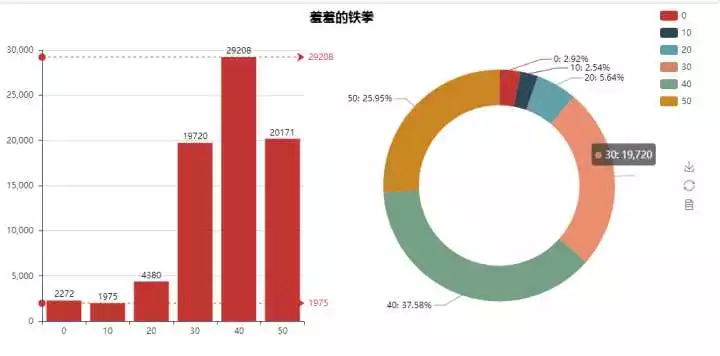
那我们来看一看,打一星的人数最少,占2.54%;打四星的人最多,占37.58%。三星跟五星的基本差不多,都在25%左右。可以说大家的打分区间基本集中在三星到五星,看来这部电影还是不错的。另外标记想看的人数并没有很多,只占2.92%,估计是已经上映这么久了,真正想看的人早就看过了。而且会使用“想看”这个功能的人数估计也不是很多,大抵都是影视发烧友,或者说是某个演员、导演的粉丝吧。
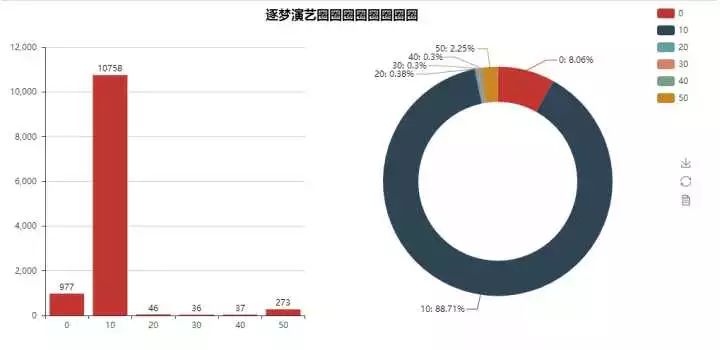
另外,作为对比,给大家看一个前段时间可以说是非常之火的豆瓣有史以来第一烂片(没有之一,评分2.1分)的分布~竟然还有977个人表示想看,你们是抱着奇文共赏的想法来的么 【扶额】
P.S. 最近刚知道,原来奇文共赏最开始是夸人文章写得好的 【再次扶额】
随时间变化趋势
接下来我们看看随着时间的变化能不能发现神马规律咧~
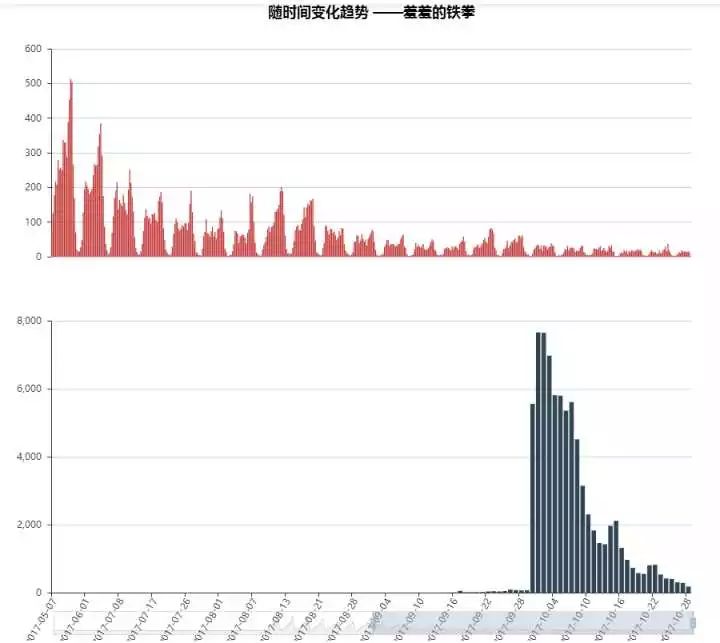
嗯,从评论时间上来看,基本上每天都是晚上10点的时候,大家发言最多。估计大部分人都是在外面happy了一天,晚上找家饭店吃个饭,然后吃完刚好看8点多到9点场次的电影,然后看完10点多出来赶紧发个朋友圈,上上豆瓣写写影评,简直是一气呵成,吃饭电影一条龙啊~ 【对了,插播条广告,关于吃什么好,可以看看我之前写的文章哈~值得一去的饭店在哪里?——让数据分析告诉你】
另外,每天凌晨2点-6点之间的评论是最少的,毕竟夜猫子还是少数啊。(至于像我这样每天4点睡的,已经不能称谓夜猫子了,我是在修仙...)不过,在12点到1点这段时间大家评论数量也还是有不少的,然后过了2点数量就骤降了。看来有不少人的睡眠时间是在1点左右,而且有相当一部分朋友喜欢在睡前看看豆瓣~
至于上映时间嘛,我看了下电影是在9月30日上映的,所以从30日开始评论数量激增,在10月1日2日的时候达到顶峰,7日开始逐渐下降,在11号左右开始渐渐趋稳。热度大约持续了十天左右。当然这十天中包含了一个国庆中秋假期,全年最长假期给了很多平时根本没时间进影院的朋友一次看电影的机会,我想这也是为何在9号10号的时候评论数量出现骤降的原因吧——大家都上班了。【哭】
不过值得一提的是,在14、15日两天,原本下降趋势的数量来了一拨小反弹,我查看了下,这两天是国庆假期结束后的第一个周末。这说明什么呢,说明有一部分朋友在国庆期间并没有看该片,但是又想看该片,所以选择了国庆后的第一个周末。那么这部分朋友,大概率国庆应该是出去旅游了。毕竟这么长的假期宅在家里是对假期的不尊重,而在假期选择出去旅(看)游(人)则是对智商的不尊重【扶额】所以请选择加班吧~此外21、22日又有个小反弹,同样是周末。
我本来是想看看一部电影的热度大概能持续多久,不过由于《羞羞的铁拳》是一部上映没多久的电影,所以用它来分析不太合适。因此我分别看了下同为“开心麻花”在2015、2016年出品的两部电影——《夏洛特烦恼》和《驴得水》的情况。
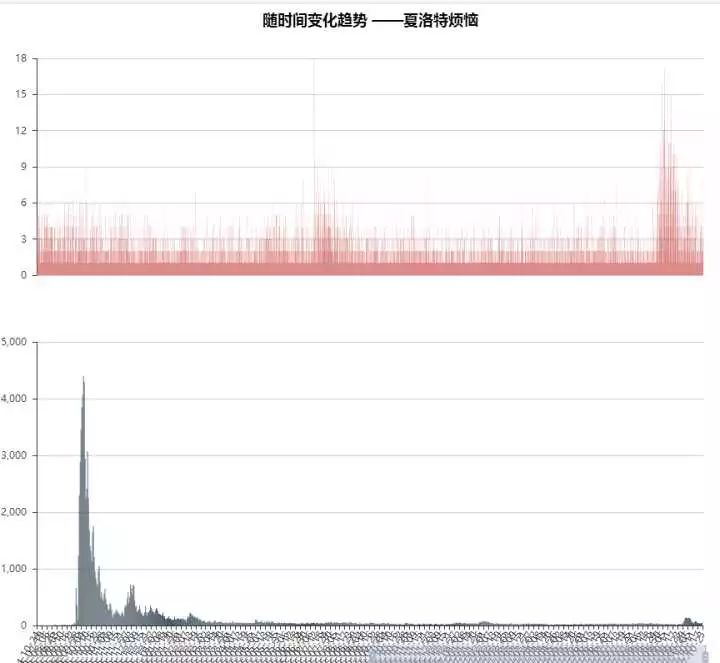
《夏洛特》是2015年9月30日上映的,评论高峰期出现在10月6日,最终大约在11初热度归于平稳,整个热度持续时间大约一个月,中间同样跨过了一个国庆假期。不过有一点奇怪的地方引起了我的注意,在热度已经消失后的11月底到12月初这段时间竟然有出现了一波小高潮。这不由得让我陷入了深深地沉思,良久我有了一个大胆的想法。。。。
我去验证了下,对的请看图。

可能大家已经意识到了,没错就是盗版片源放出来了。很多没去电影院观看,一直苦苦等待盗版资源的朋友开始在观看完电影后发表他们的影评了。老实说,这部分人还是不少的,大约占到了评论最高峰时期的五分之一了。对于一部这样热门的电影(当时也算是半个现象级电影了),我认为这还是一个相当可观的数量了。估计片方们在吐血吧,确实盗版对他们的利益损失不小。在此还是呼吁下大家,对于能在电影院看到的,口碑又不错你又想看的,那就还是去电影院看吧。影院的视听感觉是家里没法比拟的。毕竟不是谁都能像思聪一样买得起100寸的电视【请脑补思聪配图】
另外还有一点特别的发现是作为一部2015年的老片子,竟然在2017年10月份还出现了一波小小高潮。。。。 这。。。大家应该都想到了哈。很多人并没有看过他们早期的电影,而是从《铁拳》才开始接触开心麻花的,看完发现他们拍的电影还有点意思,因而有翻回去看了看他们以前拍的电影
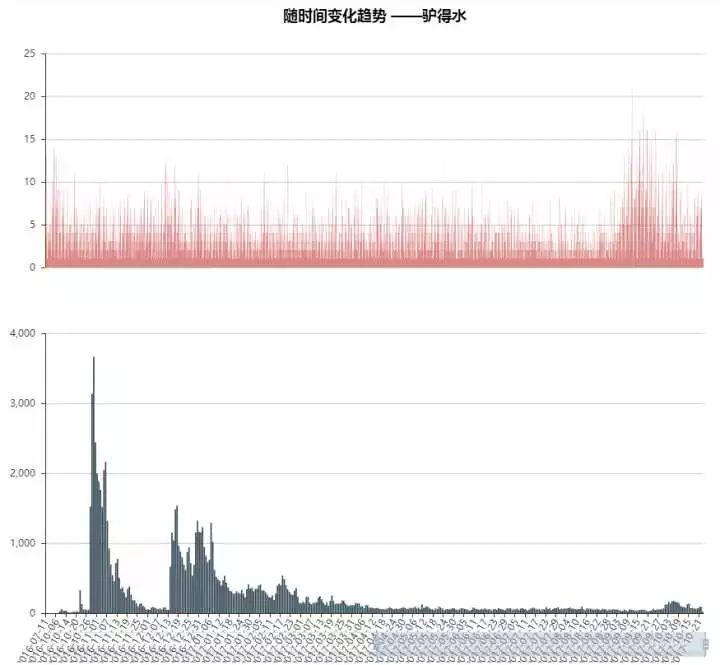
《驴得水》的情况大体跟《夏洛特》差不多,热度持续时间从2016年10月末持续到11月中。持续时间不如《夏洛特》久,可能是缺少了国庆节的助攻吧。同样在热度消失后的某一天,如平地惊雷般的出现了一大批评论,这回不用看也知道,又是盗版资源出来了。(然而作为一个严谨的数据分析师,我还是去验证了下....嘴上说的不要,身体还是很诚实的。。。逃)
不过可以看出这次的盗版的影响应该比上次要严重,评论数快占到最高峰时的一半了 另外还是相似的,在2017年10月老树发新芽,出现了波小高潮,原因就不说了~
不同星级的词云
我们来看看不同星级之间,大家的评论主要都说了些什么。
对于打一星二星的朋友来说,普遍表示:尴尬、不好看、垃圾、烂片、低俗、不好笑等等。去掉像垃圾、烂片等无实质信息的描述,我们可以发现打一星的观众,普遍认为这部电影非常尴尬,而尴尬的原因很大一部分是笑点低俗,另外就是剧情老套。这部分观众应该不是该片的主要受众,就好像爸妈那一辈人也无法理解星爷的无厘头一样,都是正常的。我不由得想起王晶导演拍的《澳门风云》系列,这部片可真是厉害了,引起了我深深的思考,而且还把这个思考从戏内延伸到了戏外——王晶究竟是多缺钱?发哥究竟是多缺钱?他们的晚年生活很悲惨么?是不是娱乐圈普遍都是这种情况?????

一星的词云

二星的词云
三星的朋友表示(那苹果的朋友呢 【这句划掉笑点低俗】):还行、一般、有笑点等等,提及最高的竟然是“夏洛特烦恼”,看来大家都还是习惯于将同一部导演的不同影片做横向对比。

而打四星、五星的观众则表示:哈哈哈哈哈哈哈。当然除了哈哈哈之外还说了,笑点密级、从头笑到尾等,作为一个喜剧片获得这样的评价无意识成功的。另外我问一下,“好运来”是什么梗,我看出现的频次也很高啊,是电影里面的么?

四星的词云

五星的词云
三、 总结
这只是在做文本情感分析之前,先顺手做个EDA,看一下数据大体的情况。了解数据的情况对于下一步情感分析会起到一定的帮助,比如我们从目前得到信息可以发现,大家对这部电影的评分还是比较高的,情感普遍倾向于正面。这样我们在接下来的时候,要注意下这个数据是不是不平衡的,会不会出现99%都是给出了正面评价,1%给出了负面评价这样的情况发生。如果出现这种情况,不作处理的话,训练出来的模型是没有意义的。模型只要全部都预测为正,那都能有99%的正确率,但是没有毛线用啊啊啊~~~
近期热门文章:
开源项目Trip: 给Requests加上协程
机器学习算法实践:树回归
如何快速爬取B站全站视频信息
机器学习算法实践-标准与局部加权线性回归
【特别供稿】Limber教你如何进行调参

长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
合作、投稿请联系微信:
pythonpost
1MEwnaxmMz7BPTYzBdj751DPyHWikNoeFS