#6.6版本
###ELK stack:是软件集合elksticsearch、logstash、kibana的集合,都是开源软件
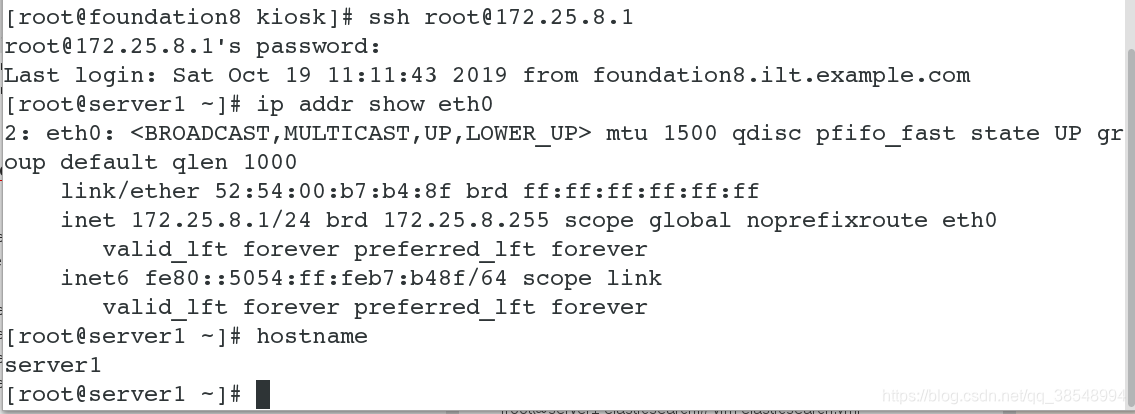
#这是集群cluster,若为单机节点,直接起;
本次实验是:一个master 两个:worker node
msater:一般3台;一般服务器
node:消耗大;
client:内存多;
搭建实验环境
3台虚拟机redhat7.5系统,内存:2G,cpu:2
| 主机信息 | 作用 |
|---|---|
| server1(172.25.8.1) | master节点 |
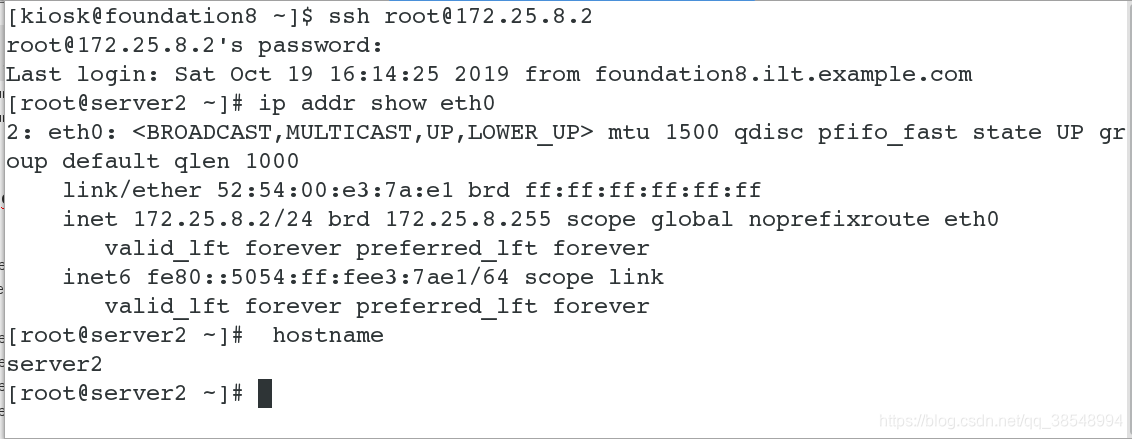
| server2(172.25.8.2) | node1节点 |
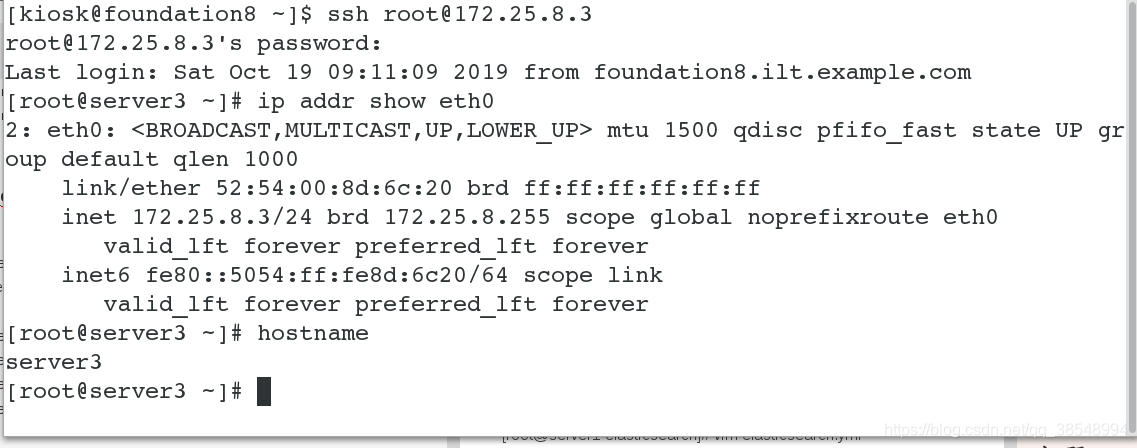
| server3(172.25.8.3) | node2节点 |
(1)用真机创建三个虚拟机
[root@foundation8 images]# qemu-img create -f qcow2 -b rhel7.5-1.qcow2 elk1
[root@foundation8 images]# qemu-img create -f qcow2 -b rhel7.5-1.qcow2 elk2
[root@foundation8 images]# qemu-img create -f qcow2 -b rhel7.5-1.qcow2 elk3
(2)用真机连接三台虚拟机
关闭防火墙和selinux
elksticsearch(6.6版)环境部署
软件包的下载:
清华大学开源软件镜像站
[root@server1 ~]# ls
elasticsearch-6.6.1.rpm elasticsearch-head-master.zip jdk-8u171-linux-x64.rpm #这些安装包是我提前下载好的
[root@server1 ~]# rpm -ivh jdk-8u171-linux-x64.rpm #安装jdk
[root@server1 ~]# rpm -ivh elasticsearch-6.6.1.rpm #安装es
[root@server1 ~]# systemctl daemon-reload #重新加载服务程序的配置文件
[root@server1 ~]# systemctl enable elasticsearch.service
[root@server1 systemd]# cd /etc/elasticsearch/
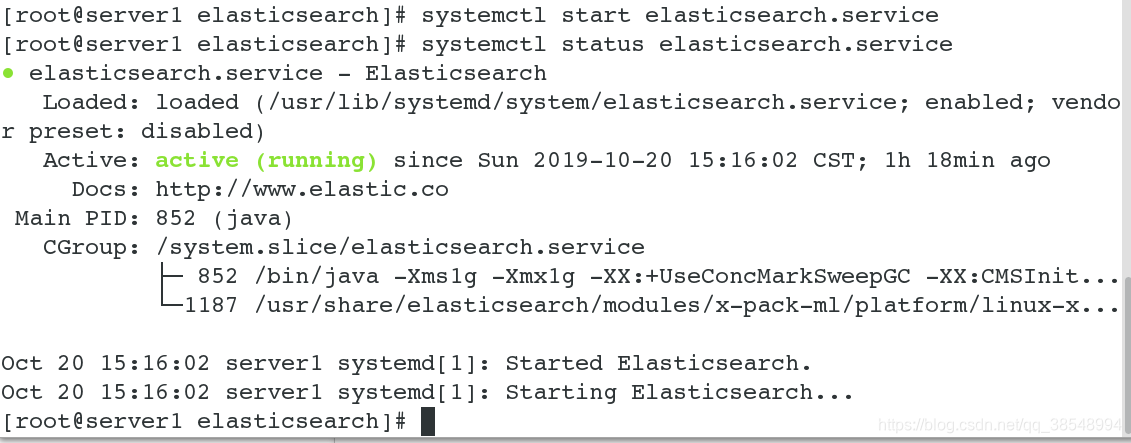
[root@server1 elasticsearch]# vim elasticsearch.yml #修改配置文件17 cluster.name: my-es #集群名称23 node.name: server1 #节点主机名称35 path.data: /var/lib/elasticsearch #数据路径39 path.logs: /var/log/elasticsearch #日志路径45 bootstrap.memory_lock: true 57 network.host: 172.25.8.161 http.port: 9200[root@server1 elasticsearch]# systemctl start elasticsearch.service #开启es服务
[root@server1 elasticsearch]# systemctl status elasticsearch.service #查看es服务状态
[root@server1 elasticsearch]# cat /var/log/elasticsearch/my-es.log#查看es的日志 #会有debug报错
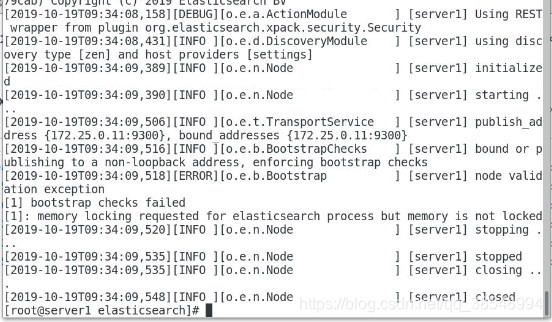
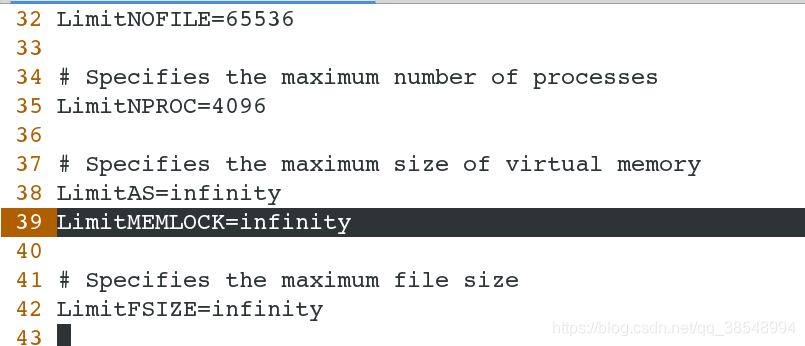
[root@server1 elasticsearch]# vim /etc/security/limits.conf 62 elasticsearch soft memlock unlimited63 elasticsearch hard memlock unlimited
[root@server1 elasticsearch]# systemctl status elasticsearch.service #查看服务状态有报错
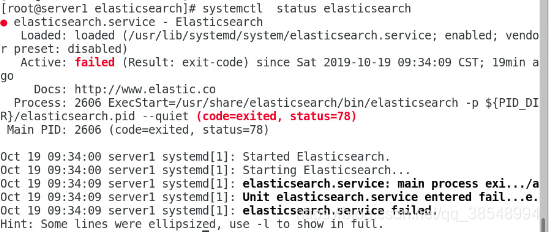
[root@server1 elasticsearch]# vim /usr/lib/systemd/system/elasticsearch.service39 LimitMEMLOCK=infinity
[root@server1 elasticsearch]# systemctl daemon-reload
[root@server1 elasticsearch]# yum install -y bash-* #下载可以tab补齐

[root@server1 elasticsearch]# vim /etc/security/limits.conf 65 elasticsearch - nofile 65535 #打开最大文件数66 elasticsearch - nproc 4096 #打开最大进程
#记住每次修改过配置文件都要进行重启服务

[root@server1 elasticsearch]# cat /var/log/elasticsearch/my-es.log#查看es的日志 ,显示服务以生效

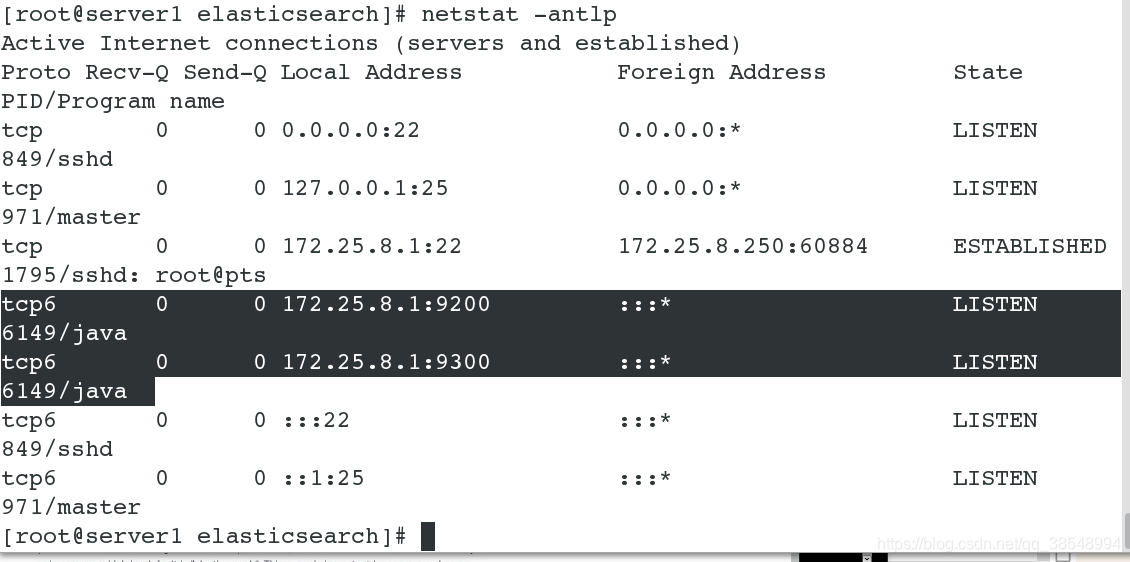
查看端口:9200和9300被打开
[root@server1 ~]# unzip elasticsearch-head-master.zip
[root@server1 ~]# cd elasticsearch-head-master/
[root@server1 ~]# ls
elasticsearch-6.6.1.rpm nodejs-9.11.2-1nodesource.x86_64.rpm
elasticsearch-head-master
elasticsearch-head-master.zi jdk-8u171-linux-x64.rpm
[root@server1 ~]# rpm -ivh nodejs-9.11.2-1nodesource.x86_64.rpm

#打开网络在主机上进行地址伪装和路由转换



[root@server1 ~]# cd elasticsearch-head-master/
[root@server1 elasticsearch-head-master]# npm install #npm进行下载,`注意路径`,有可能会出现报错,一定要注意你的taoba镜像的路径设置

[root@server1 ~]# tar jxf phantomjs-2.1.1-linux-x86_64
[root@server1 phantomjs-2.1.1-linux-x86_64]# ls
[root@server1 phantomjs-2.1.1-linux-x86_64]# cd bin/
[root@server1 bin]# cp phantomjs /usr/local/bin/ #将脚本启动文件存放在 /usr/local/bin/

[root@server1 elasticsearch-head-master]# yum install -y libfontconfig.so.1
[root@server1 elasticsearch-head-master]# yum install -y fontconfig #注意下载64位的
[root@server1 elasticsearch-head-master]# phantomjs
phantomjs>


[root@server1 elasticsearch-head-master]# node -v
v9.11.2
[root@server1 elasticsearch-head-master]# npm -v
5.6.0



[root@server1 elasticsearch-head-master]# npm run start &
[root@server1 elasticsearch-head-master]# netstat -antlp | grep 9100


#在浏览器上测试,输入:172.25.8.1.9100 es:http://172.25.8.1:9200

#无显示 是因为存在es跨域的问题
[root@server1 elasticsearch-head-master]# vim /etc/elasticsearch/elasticsearch.yml63 http.cors.enabled: true64 http.cors.allow-origin: "*" #允许所有的跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain) 上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。


[root@server1 ~]# systemctl restart elasticsearch.service
[root@server1 ~]# cat /var/log/elasticsearch/my-es.log #查看日志

#在浏览器上再次测试,会出现server1的服务;
#查看文件发现是9100端口


#在浏览器上再次测试,再次点击图中my-es的连接
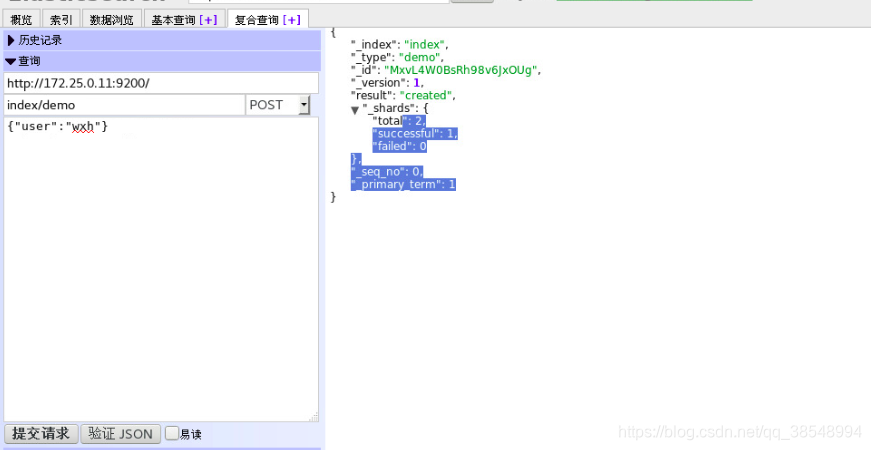
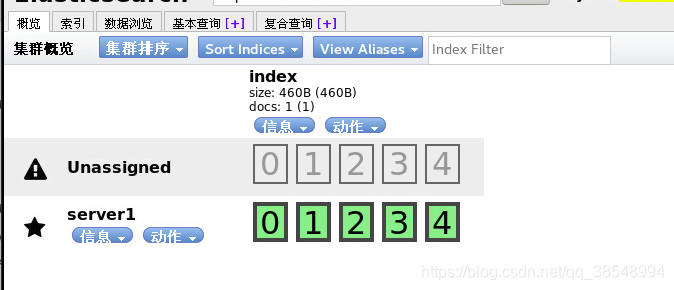
#将jdk和es的rpm包发送给server2和server3

server2(node1)环境部署
[root@server2 ~]# ls
elasticsearch-6.6.1.rpm jdk-8u171-linux-x64.rpm #这些安装包是我提前下载好的
[root@server2 ~]# rpm -ivh jdk-8u171-linux-x64.rpm #安装jdk
[root@server2 ~]# rpm -ivh elasticsearch-6.6.1.rpm #安装es


[root@server2 elasticsearch]# vim /etc/security/limits.conf 62 elasticsearch soft memlock unlimited63 elasticsearch hard memlock unlimited65 elasticsearch - nofile 65535 #打开最大文件数66 elasticsearch - nproc 4096 #打开最大进程[root@server2 elasticsearch-head-master]# vim /etc/elasticsearch/elasticsearch.yml17 cluster.name: my-es #集群名称23 node.name: server2 #节点主机名称35 path.data: /var/lib/elasticsearch #数据路径39 path.logs: /var/log/elasticsearch #日志路径45 bootstrap.memory_lock: true 57 network.host: 172.25.8.261 http.port: 9200101 discovery.zen.ping.unicast.hosts:["server1","server2","server3"]

[root@server2 elasticsearch]# vim /usr/lib/systemd/system/elasticsearch.service39 LimitMEMLOCK=infinity
#重启服务
[root@server2 conf.d]# systemctl daemon-reload
[root@server2 conf.d]# systemctl start elasticsearch.service

#浏览器再次测试,输入ip:port:172.25.8.1:9100,在es处输入:http://172.25.8.1:9200 再次刷新,会出现server2的服务

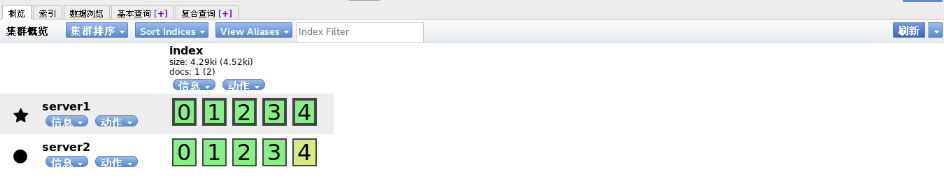
server3(node2节点)环境部署,和server2类似
[root@server1 ~]# scp jdk-8u171-linux-x64.rpm elasticsearch-6.6.1.rpm server3: #将这两个包发送给server3
[root@server3 ~]# ls
elasticsearch-6.6.1.rpm jdk-8u171-linux-x64.rpm #这些安装包是我提前下载好的
[root@server3 ~]# rpm -ivh jdk-8u171-linux-x64.rpm #安装jdk
[root@server3 ~]# rpm -ivh elasticsearch-6.6.1.rpm #安装es
[root@server2 elasticsearch]# vim /etc/security/limits.conf 62 elasticsearch soft memlock unlimited63 elasticsearch hard memlock unlimited65 elasticsearch - nofile 65535 #打开最大文件数66 elasticsearch - nproc 4096 #打开最大进程[root@server2 elasticsearch-head-master]# vim /etc/elasticsearch/elasticsearch.yml17 cluster.name: my-es #集群名称23 node.name: server3 #节点主机名称35 path.data: /var/lib/elasticsearch #数据路径39 path.logs: /var/log/elasticsearch #日志路径45 bootstrap.memory_lock: true 57 network.host: 172.25.8.361 http.port: 9200101 discovery.zen.ping.unicast.hosts:["server1","server2","server3"]

[root@server2 elasticsearch]# vim /usr/lib/systemd/system/elasticsearch.service39 LimitMEMLOCK=infinity
#重启服务

[root@server3 elasticsearch]# cat /var/log/elasticsearch/my-es.log#查看es的日志
#再次浏览器测试:连接刷新

#修改server1的配置文件
[root@server1 elasticsearch-head-master]# vim /etc/elasticsearch/elasticsearch.yml
node.master:true #表示节点是否具有成为主节点的资格。 ==[注意:此属性的值为true,并不意味着这个节点就是主节点。因为真正的主节点,是由多个具有主节点资格的节点进行选举产生的。所以,这个属性只是代表这个节点是不是具有主节点选举资格]==但是该实验指任server1是作为es集群的主节点
node.data:false #节点是否存储数据。bootstrap.memory_lock:true
[root@server1 elasticsearch-head-master]# systemctl restart elasticsearch #重启服务



#修改server2的配置文件
[root@server2 elasticsearch-head-master]# vim /etc/elasticsearch/elasticsearch.yml
node.master:fasle #表示节点是否具有成为主节点的资格。
node.data:true
[root@server2 elasticsearch-head-master]# systemctl restart elasticsearch #重启服务

#修改server3的配置文件
[root@server3 elasticsearch-head-master]# vim /etc/elasticsearch/elasticsearch.yml
node.master:fasle #表示节点是否具有成为主节点的资格。
node.data:true
[root@server3 elasticsearch-head-master]# systemctl restart elasticsearch #重启服务
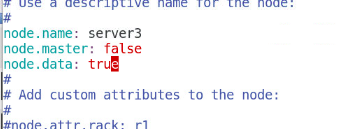
#在浏览器上会发现数据的server1上数据不存在

logstash:数据采集
#在server2上进行数据的采集;
主要的使用过程:hosts->logstash(input filter(过滤) output)->发送给es-->es->kibana(在web页面进行呈现)
[root@server2 ~]# ls
elasticsearch-6.6.1.rpm jdk-8u171-linux-x64.rpm logstash-6.6.1.rpm
[root@server2 ~]# rpm -ivh logstash-6.6.1.rpm
[root@server2 ~]# systemctl start logstash #启动服务
[root@server2 ~]# cd /etc/logstash/conf.d/
[root@server2 conf.d]#
[root@server2 conf.d]# rpm -ql logstash | less
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { stdout{}}' #进行安装测试:

#随便输入内容即可
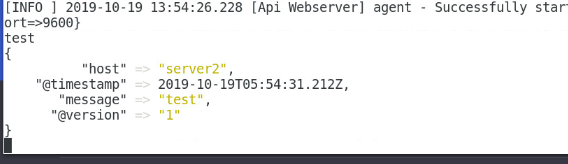
[root@server2 conf.d]# pwd/etc/logstash/conf.d/
作为系统服务启动测试:默认加载的配置文件为 /etc/logstash/logstash.yml 中的 path.config 配置路径 /etc/logstash/conf.d/*.conf
[root@server2 conf.d]# vim test.conf #自己根据自己需求编写测试input { stdin{} #stdin是标准输入,一般指键盘输入到缓冲区里的东西。
}
output { stdout{} #stdout是标准输出
}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/ test.conf



#手动输入,进行数据采集,将数据发送server1(es),在server1上进行呈现
[root@server2 conf.d]# vim test.conf #自己根据自己需求编写测试
input {
stdin{} #stdin是标准输入,
}
output {
stdout{} #stdout是标准输出
elasticsearch {
hosts => “172.25.8.1:9200” #指定es主机,server1是主节点,也是es
index => “logstash-%{+YYYY.MM.dd}” #索引名称
}
}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/ test.conf

#手动随机输入

#在浏览器上进行再次测试:


在server2上再次输入redhat,在浏览器上会发现生成新的数据

#保存数据到文件中
[root@server2 conf.d]# vim test.conf #自己根据自己需求编写测试input { stdin{} #stdin是标准输入,
}
output { stdout{} #stdout是标准输出elasticsearch {hosts => "172.25.8.1:9200" #指定es主机,server1是主节点,也是esindex => "logstash-%{+YYYY.MM.dd}" #索引名称}file {path => " /tmp/logstash.txt" #文件格式无所谓codec => line { format => "custom format : %{message}"}}}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/ test.conf

#随便输入数据


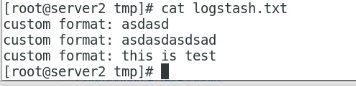

#file 从日志文件中读取,进行采集,然后自动读取;
[root@server2 conf.d]# vim test.conf
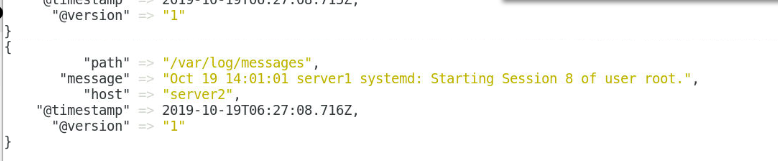
input {file {path => "/var/log/messages"start_position => "beginning"}
}output {stdout{}elasticsearch {hosts => "172.25.8.1:9200"index => "messages-%{+YYYY.MM.dd}"}
}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/ test.conf


#自动读取,不需要手动输入

#在浏览器上进行再次连接刷新:




#删除messages数据收集的信息,然后进行再次测试

#删除成功,但是再次测试的话,还需要删除配置文件中的真正的数据,否则收集的还是原先的数据


[root@server2 conf.d]# cd /usr/share/logstash/
[root@server2 logstash]# cd data/plugins/inputs/file/
[root@server2 file]# ls

#再次测试

#从514端口进行采集,采集server1上的数据
[root@server2 conf.d]# vim test.conf
input {
# file {
# path => "/var/log/messages"
# start_position => "beginning"
# }
}syslog {port => 514}output {stdout{}elasticsearch {hosts => "172.25.8.1:9200"index => "syslog-%{+YYYY.MM.dd}"}
# file {
# path => " /tmp/logstash.txt" #文件格式无所谓
# codec => line { format => "custom format : %{message}"}
# }
}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf #不能关闭,保持测试打开的状态

#修改server1的采集数据的端口
[root@servre1 etc] vim /etc/rsyslog.conf
#倒数第二行
*.* @@172.25.8.2:514
[root@servre1 etc]# systemctl restart rsyslog
[root@servre1 etc]# logger westos
[root@servre1 etc]# logger hello


#server2的显示

#查看server2上514端口,server1是否对server2打开

#在浏览器上查看



EOF是END Of File的缩写,表示自定义终止符.既然自定义,那么EOF就不是固定的,可以随意设置别名,在linux按ctrl-d就代表EOF.
EOF一般会配合cat能够多行文本输出.
通过cat配合重定向能够生成文件并追加操作,;
#多行录入EOF结束输入
[root@server2 conf.d]# vim es.conf
input {stdin {codec => multiline {pattern => "EOF" #输入重定向negate => "true"what => "previous"}}
output {stdout{}
}}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/es.conf



#多行收集server2上的my-es.log日志数据;
[root@server2 conf.d]# vim test.conf
input {file {path => "/var/log/elasticsearch/my-es.log"start_position => "beginning"codec => multiline {pattern => "^\[" #查找以[开头的数据negate => "true"what => "previous"}}
}output {stdout{}elasticsearch {hosts => "172.25.8.1:9200"index => "es-%{+YYYY.MM.dd}"}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/es.conf


#查看浏览器



#采集apache日志数据
[root@server2 ~] # yum install httpd -y
[root@server2 ~] # systemctl start httpd
[root@server2 ~]# cd /var/www/html/
[root@server2 html]# cat index.html
<h1>www.westos.org</h1>
#在server1上进行测试:

[root@foundation8 Desktop]# ab -c 1 -n 100 http://172.25.8.2/index.html #物理机对server2进行压力测试;
| ab(apache bench)是apache下的一个工具,主要用于对web站点做压力测试, |
|---|
| 基础用法: 其中-c选项为一次发送的请求数量,及并发量。 -n选项为请求次数。 |
[root@server2 conf.d]# cat /var/log/httpd/access_log #查看登陆日志信息


[root@server2 conf.d]# pwd
/etc/logstash/conf.d
[root@server2 conf.d]# vim apache.conf
input {file {path => "/var/log/httpd/access_log" #查看的文件路径start_position => "beginning"}
# syslog {
# port => 514
# }
}output {stdout{}elasticsearch {hosts => "172.25.8.1:9200"index => "apache-%{+YYYY.MM.dd}"}# file {
# path => "/tmp/logstash.txt"
# codec => line { format => "custom format: %{message}" }
# }
}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/ test.conf

#查看浏览器测试

#在这里我们发现有个问题,就是还有个问题就是过滤,那么需要匹配的正则模式
#举一反三,我们尝试输出一下/var/log/httpd/access_log字段的时间信息。
这个时候我们可以去找匹配的正则有哪些,要去这个路径下找:/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns目录下的grok-patterns这个文件;

#grok匹配进行过滤fifter,可以采集需要内容
[root@server2 patterns]# cd /etc/logstash/conf.d/
[root@server2 conf.d]# vim grok.conf
input {stdin{}
}
filter {grok{match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}}
}
output{stdout{}}[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/grok.conf #启动logstash55.3.244.1 GET /index.html 15824 0.043


ELK(ElasticSearch+Logstash+ Kibana)搭建实时日志分析平台
#该实验是在以上的实验基础上,进行了logstash收集apache的日志信息发送给es传到kibana
[root@server2 conf.d]# pwd
/etc/logstash/conf.d
[root@server2 conf.d]# vim apache.conf
input {file {path => "/var/log/httpd/access_log" #日志登陆文件路径start_position => "beginning"}
# syslog {
# port => 514
# }
}
filter { #过滤的出HTTPD_COMBINEDLOGgrok{match => {"message" => "%{HTTPD_COMBINEDLOG}"}}
}output {stdout{}elasticsearch {hosts => "172.25.8.1:9200"index => "apache-%{+YYYY.MM.dd}"}# file {
# path => "/tmp/logstash.txt"
# codec => line { format => "custom format: %{message}" }
# }
}
[root@server2 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/apache.conf #启动logstash ,将其发送给es,然后传至kibana,切忌不要关闭logstash的启动服务


#删除之前收集apache的信息,以及配置文件中的信息


#server2上的收集apache日志信息 的启动logstash服务必须保证在启动的状态

##在server3上添加kibana服务
[root@server3 ~]# ls
elasticsearch-6.6.1.rpm kibana-6.6.1-x86_64.rpm
jdk-8u171-linux-x64.rpm Kibana_Hanization-master.zip
[root@server3 ~]# rpm -ivh kibana-6.6.1-x86_64.rpm
[root@server3 ~]# cd /etc/kibana/
[root@server3 kibana]# ls
[root@server3 kibana]# vim kibana.yml
2 server.port: 5601
7 server.host: "172.25.8.3" #将server设置成本机
28 elasticsearch.hosts: ["http://172.25.8.1:9200"] #将es的设置成的hosts
37 kibana.index: ".kibana" #kibana的信息收集的名称为.kibana[root@server3 kibana]# systemctl start kibana.service





#将Kibana进行汉化
[root@server3 ~]# ls
elasticsearch-6.6.1.rpm kibana-6.6.1-x86_64.rpm
jdk-8u171-linux-x64.rpm Kibana_Hanization-master.zip #这个包也可以在github上面download ,#这里这个包是6.6的包,因为kibana服务使用的就是6.6的版本
[kibana的汉化包的github的地址](https://github.com/anbai-inc/Kibana_Hanization)
[root@server3 ~]# yum install -y unzip
[root@server3 ~]# unzip Kibana_Hanization-master.zip #将其汉化包进行解压
[root@server3 ~]# ls
elasticsearch-6.6.1.rpm Kibana_Hanization-master
jdk-8u171-linux-x64.rpm Kibana_Hanization-master.zip
kibana-6.6.1-x86_64.rpm
[root@server3 Kibana_Hanization-master]# cp -r translations/ /usr/share/kibana/src/legacy/core_plugins/kibana/
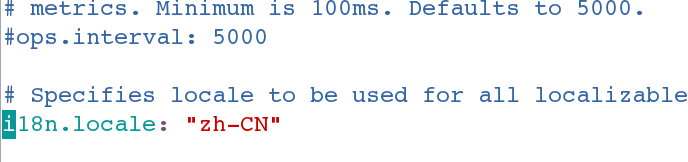
[root@server3 Kibana_Hanization-master]# vim /etc/kibana/kibana.yml
113 i18n.locale: "zh-CN" #汉化kibana
[root@server3 Kibana_Hanization-master]# systemctl start kibana


#server2的启动服务一定要保持不变


#查看server3的5601的端口是否打开

#在物理机上对server2进行压力测试
[root@foundation8 Desktop]# ab -c 1 -n 1200 http://172.25.8.2/index.html

#server1对server2进行访问,以及压力测试
[root@server1 elasticsearch-head-master]# cd
[root@server1 ~]# yum install -y httpd-tools #安装apache,压力测试的命令
[root@server1 ~]# curl 172.25.8.2 #访问server2
<h1>www.westos.org</h1>
[root@server1 ~]# ab -c 1 -n 1200 http://172.25.8.2/index.html #sever1对server2进行压力测试



#server3对server2进行访问,以及压力测试
[root@server3 kibana]# curl 172.25.8.2
<h1>www.westos.org</h1>
[root@server3 kibana]# curl 172.25.8.2
<h1>www.westos.org</h1>
[root@server3 kibana]# yum install -y httpd-tools #安装apache,压力测试的命令
[root@server3 kibana]# b -c 1 -n 400 http://172.25.8.2/index.html




简单介绍一下kibana
Kibana定义:(一张图片胜过千万行日志)
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
你用Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。
你可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
Kibana使得理解大量数据变得很容易。它简单的、基于浏览器的界面使你能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的变化。
Kibana 的使用场景,应该集中在两方面:
实时监控
通过 histogram 面板,配合不同条件的多个 queries 可以对一个事件走很多个维度组合出不同的时间序列走势。时间序列数据是最常见的监控报警了。
问题分析
关于 elk 的用途,可以参照其对应的商业产品 splunk 的场景:使用 Splunk 的意义在于使信息收集和处理智能化。而其操作智能化表现在:
搜索,通过下钻数据排查问题,通过分析根本原因来解决问题;
实时可见性,可以将对系统的检测和警报结合在一起,便于跟踪 SLA 和性能问题;
历史分析,可以从中找出趋势和历史模式,行为基线和阈值,生成一致性报告。
#在浏览器上编辑server3的kibana服务
#(1)访问kibana服务:在浏览器上输入ip :172.25.8.3:5601(输入安装kibana服务主机的ip:5601)

#(2)
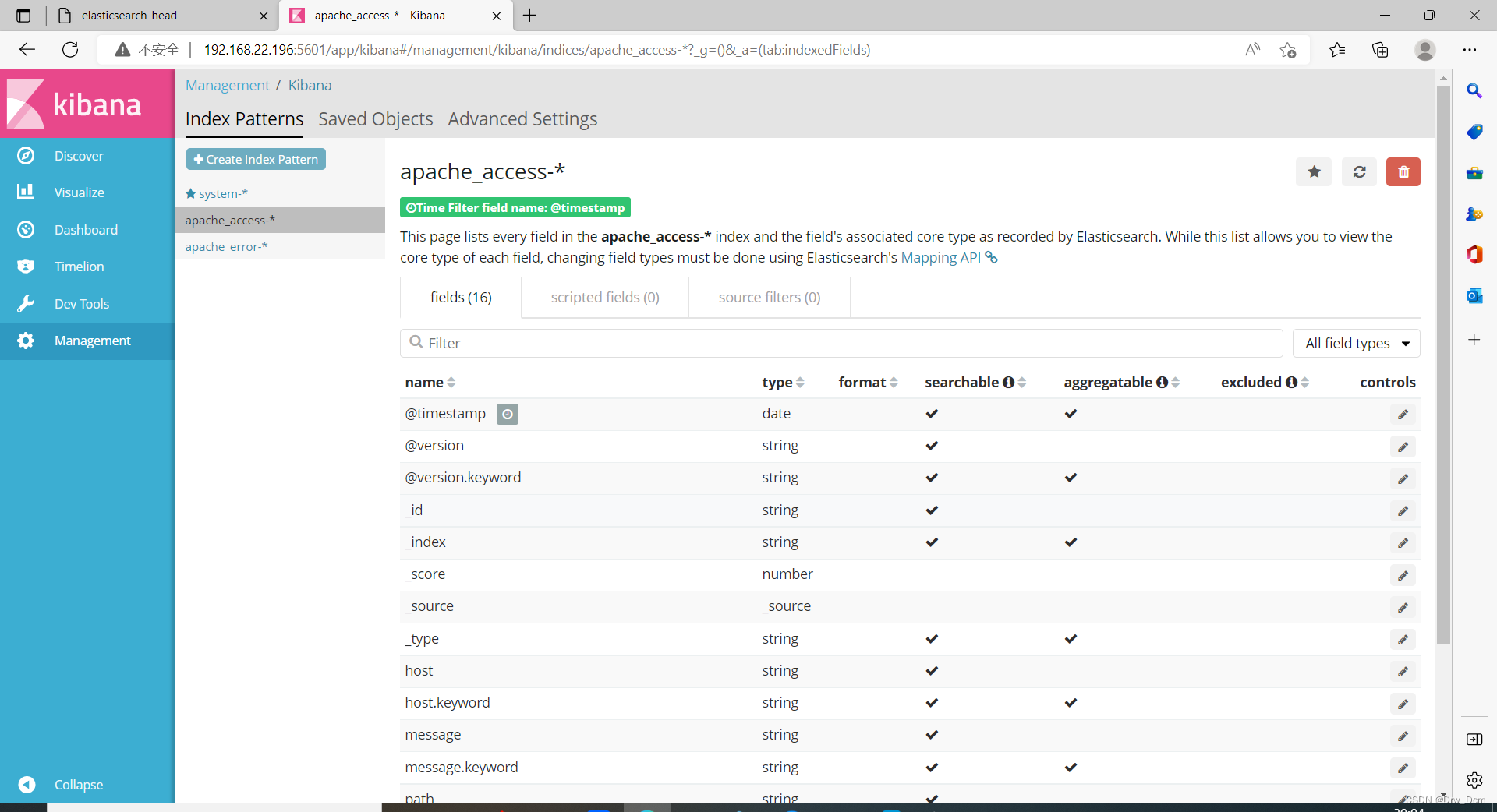
当访问Kibana时,默认情况下,Discover页面加载时选择了默认索引模式。时间过滤器设置为最近15分钟,搜索查询设置为match-all(*)
第二次访问的时候,选择左边的管理,在点击索引模式;


#(3)用Elasticsearch连接到Kibana
在你开始用Kibana之前,你需要告诉Kibana你想探索哪个Elasticsearch索引。第一次访问Kibana是,系统会提示你定义一个索引模式以匹配一个或多个索引的名字。
(提示:默认情况下,Kibana连接允许在localhost上的Elasticsearch实例。为了连接到一个不同的Elasticsearch实例,修改kabana.yml中Elasticsearch的URL,然后重启Kibana。)(这个在之前已经做过了)
为了配置你想要用Kibana访问的Elasticsearch索引:
1、访问Kibana UI。例如,localhost:56011 或者 http://YOURDOMAIN.com:5601
2、指定一个索引模式来匹配一个或多个你的Elasticsearch索引。当你指定了你的索引模式以后,任何匹配到的索引都将被展示出来。
(画外音:*匹配0个或多个字符; 指定索引默认是为了匹配索引,确切的说是匹配索引名字)
3、点击“Next Step”以选择你想要用来执行基于时间比较的包含timestamp字段的索引。如果你的索引没有基于时间的数据,那么选择“I don’t want to use the Time Filter”选项。
4、点击“Create index pattern”按钮来添加索引模式。第一个索引模式自动配置为默认的索引默认,以后当你有多个索引模式的时候,你就可以选择将哪一个设为默认。(提示:Management > Index Patterns)
开始创建索引模式,
本次kibanna的实验是在监控apache的服务,所以在索引模式的第一栏输入:apache-*,然后点击下一步

#(4)选择时间筛选字段名称:@timestamp,点击创建索引模式


#(5)点击左边可视化,开始创建可视化

#(6)选择“指标“可视化

#(7)点击apache-*


#(8)添加指标,注意右上角选择为today,因为默认的是15分钟内的;
#上物理机和server1和server3对server2的访问测试总共2803次,显示成功

#(9) 单击上述菜单栏中的 保存按钮,然后输入该实验的名称,比如,本实验为命名为apache的总访问量,将该实验保存在可视化中,

#(10)添加仪表板, 单击上述菜单栏中的添加 按钮,以将可视化添加到仪表板。


#(11)点击apache的总访问量,即可添加成功


#(12)单击上述菜单栏中的保存 按钮,编辑仪表板的名称,该实验为web站点状态

#(13)保存完之后,单击上述菜单栏中的全屏 按钮,可以看起来更加方便


#(14)物理机继续向server2中进行压力测试
[root@foundation8 Desktop]# ab -c 1 -n 200 http://172.25.8.2/index.html

#(15)回到kibana的浏览器,点击kibana的最右侧有个Refresh按钮,进行刷新,发现apache的访问量变成了3002,实验成功

#(17)server1和server3都向server2继续进行压力测试
[root@server1 ~]# ab -c 1 -n 100 http://172.25.8.2/index.html
[root@server3 kibana]# ab -c 1 -n 100 http://172.25.8.2/index.html



#(17)点击菜单栏的 Visualize,再点击“+“,创建新的可视化界面,点击垂直条形图,再点击apache-*




#(18)左下角有个存储桶,设置x轴的存储桶,并且暂停服务,才会显示垂直条形图,否则会一直显示全部的;


#(19)点击菜单栏的保存按钮,编辑可视化名称:apache的排行榜

#(20)编辑仪表板,点击菜单栏的 添加 按钮,点击apache的排行榜,



(21)点击菜单栏的保存按钮,确认保存,成功添加到web站点状态


#注意apache日志的权限


#(22)继续向sever2中进行压力测试
[root@foundation8 Desktop]# ab -c 1 -n 200 http://172.25.8.2/index.html

#(23)查看es浏览器,发现apache的服务数据发生了变化

#(24)刷新kibana的服务,压力测试成功

kibanac报错知识点
#如果出现Kibana server is not ready yet这种报错的原因,有以下几种情况:

第一点:KB、ES版本不一致(网上大部分都是这么说的)
解决方法:把KB和ES版本调整为统一版本
第二点:kibana.yml中配置有问题(通过查看日志vim /var/log/message,发现了Error: No Living connections的问题)
解决方法:将配置文件kibana.yml中的elasticsearch.url改为正确的链接,默认为: http://elasticsearch:9200
改为http://自己的IP地址:9200
第三点:浏览器没有缓过来,清除缓存,继续刷新;
解决方法:刷新几次浏览器。
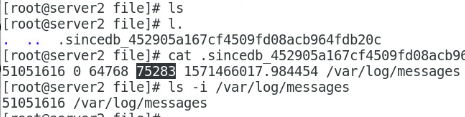
内存有很多的冗余,为什么不能建立文件?
因为inode号被封;inode号是指针,指向底层的磁盘数据;释放了inode号即可;
/usr、/home、/bin、/dev、/var、/etc中主要存放什么文件
/usr 最庞大的目录,要用到的应用程序和文件几乎都在这个目录。其中包含:
/usr/X11R6 存放X window的目录
/usr/bin 众多的应用程序
/usr/sbin 超级用户的一些管理程序
/usr/doc linux文档
/usr/include linux下开发和编译应用程序所需要的头文件
/usr/lib 常用的动态链接库和软件包的配置文件
/usr/man 帮助文档
/usr/src 源代码,linux内核的源代码就放在/usr/src/linux里
/usr/local/bin 本地增加的命令
/usr/local/lib 本地增加的库
/home 用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示
/bin 二进制可执行命令
/dev 设备特殊文件
/var 某些大文件的溢出区,比方说各种服务的日志文件
/etc 系统管理和配置文件
/etc/rc.d 启动的配置文件和脚本