目录
Dsp融合算法移植
第一章 文档概述
1.1 文档目的
1.2 文档范围
1.3 文档对象
第二章 dsp开发环境配置
2.1 环境安装与激活
第三章 arm端开发工作
3.1微光和热成像图像配准
3.2接口调用
第四章 dsp端开发工作
4.1数据解析
4.2乒乓数据传输
4.3融合算法
4.4优化加速
第五章 总结回顾
5.1开发调试总结
5.2后续优化方向
5.3致谢
一、文档概述
1.1 文档目的
本文档介绍dsp开发过程的具体步骤,目的在于让读者了解dsp开发的流程,快速掌握dsp开发的基本步骤和逻辑。
1.2 文档范围
本文档主要范围包括:
- dsp开发环境搭建
- arm端rpc接口调用
- opencv生成配准矩阵
- gdc模块调用方法
- dsp端空间映射
- 图像处理基本概念(滤波、腐蚀、膨胀)
- dsp端乒乓buf管理
- dsp端tile处理
- dsp端SIMD处理逻辑
对图像处理感兴趣的同学,对融合算法感兴趣的同学,对SIMD优化感兴趣的同学,对技术和工程思维感兴趣的同学......
二、 dsp开发环境配置
2.1 环境安装与激活
参考SVP2.0开发指南,第二章DSP开发指南详细介绍了工具的安装与配置;至于激活的流程,购买license后也会有详细的说明,主要就是把license导入即可。具体文档信息参考文末附件。关于license的问题,如果有问题可以寻求官方支持,他们会给出详细的解答。
3.1微光和热成像图像配准
由于融合的数据存在fov上的差异,所以在数据融合之前需要做图像配准的工作。具体来说,微光的原始分辨率是1024*768,假设FOV为A,热成像数据原始分辨率是640*512,假设FOV为B。由于FOV和分辨率的不同,在图像融合前,需要对图像做配准。
图像配准的基本逻辑包括:1、分辨率不同,相同的物体大小不一样,通过配准矩阵相同物体在图像上像素点也一样;2、FOV不同,通过配准矩阵,对FOV进行矫正。
配准矩阵即使投影变换映射函数,实现平面图像的投影变换。表达式如下:

其中,x,y 为输入图像坐标,x’,y’为输出图像坐标,该矩阵表示的是根据输出坐标计算得到的输入坐标。m0,m1,m3,m4分别表示图像的缩放尺度和旋转量;m2表示图像在水平方向上的位移;m5表示图像在垂直方向上的位移;m6、m7表示图像在水平和垂直方向上的形变量。m8为权重因子,在归一化条件下,m8恒为1。更多细节内容参考文末的GDC调试指南。
如何获取上述的配准矩阵呢?我们可以利用opencv得到相关的配准矩阵。
输入两张图片,右击选择匹配的特征点,最后就会输出配准后图像和融合的效果以及相关的矩阵。需要特别注意:
- 输出的矩阵和上面描述的矩阵是互逆矩阵,所以不能直接使用;
- 使用的时候,矩阵需要乘上一个系数524288。
- gdc输出和输入是同分辨率的,所以配准的时候也要将数据缩放到同分辨率
如何利用矩阵生成配准后的图像呢?这里需要调用gdc的模块接口了,具体接口ss_mpi_gdc_add_pmf_task,其中前后依赖的接口及参数不做详细介绍了。具体可以参考文档MPP媒体处理软件V5.0开发参考。
至此我们得到了待处理的数据,下一步就可以调用arm的接口给dsp喂数据了。
DSP应用程序开发框图如下:
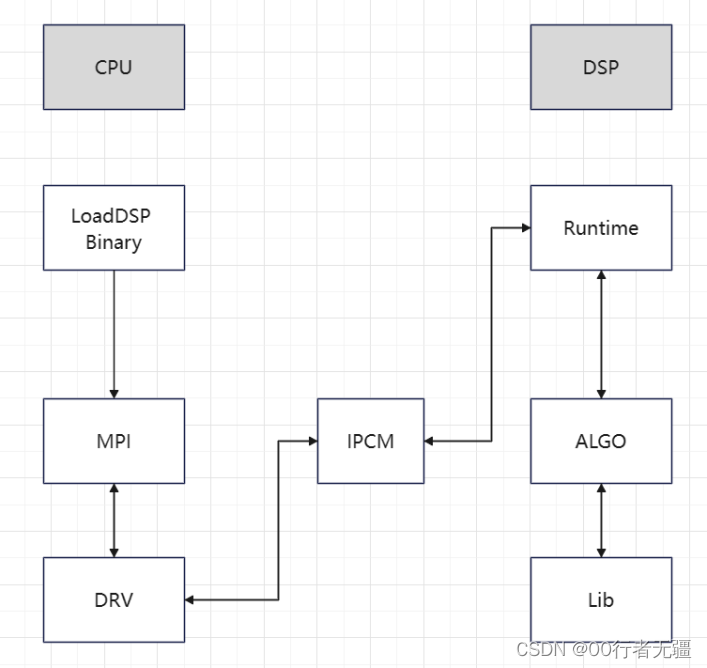
图1 dsp开发框架图
如上图所示,在arm端需要加载dsp bin文件,调用rpc远程接口将数据送到dsp处理。
arm端提供的接口参考文档SVP2.0 API参考 第四章内容,总共提供7个api接口。包括power_on/off,load_bin,enable/disable_core,dsp_rpc/dsp_query。本文重点介绍dsp_rpc接口,其他接口相对简单,文档也有说明。
td_s32 ss_mpi_svp_dsp_rpc(ot_svp_dsp_handle *handle, const ot_svp_dsp_msg *msg, ot_svp_dsp_id dsp_id, ot_svp_dsp_pri pri);
handle 为输出参数,可用于状态查询;
msg为传递的消息体,dsp主要就是解析这部分内容获取待处理的数据;
dsp_id DSP id号,有两个dsp核可以使用;
pri 表示任务的优先级;
arm 端需要把待处理的数据放到body里面,传递到dsp。Body是一片物理地址,依次将需要传递的内容拷贝到这里面,比如我们需要放两个帧结构的数据和融合算法需要的映射矩阵,就一次把这些内容拷贝过去,然后调用rpc接口将数据发送到dsp端。需要注意的是,数据body不能太大。DRAM端总共的内存也就两片,共计100KB + 118KB。
4.1数据解析
在arm端调用远程rpc接口后,程序的控制权就流到了dsp模块。dsp端首先要做的就是解析arm传递过来的数据。这里就是msg的地址,把这个地址当作内存流来处理,按照arm端数据填写的方式,顺序解析就可以了。有一点特别重要,arm和dsp的地址空间是不同的,不能直接解析,需要做地址的转化。具体方法就是将传入的body物理地址加上一个固定的offset就偏移到DRAM的物理地址空间,然后再使用dma将数据拷贝下来,dsp再根据当时填充的结构去解析就可以了。
这里有一点需要特别注意的,arm端的指针是8字节的,而dsp端的指针是4字节的。再计算结构体大小的时候,要特别注意,否则会导致解析错误。
DRAM空间受限,需要把数据分割开做处理。将数据划分为多个大小相同的tile单元做处理。数据拷贝的时候是采用乒乓buffer的方式,即数据copy到bufferB,同时在处理A; 然后再将数据copy到BufferA,同时处理bufferB。即相同的时刻,同时在copy和处理数据,从而提高并行度。大体的数据处理流如下:
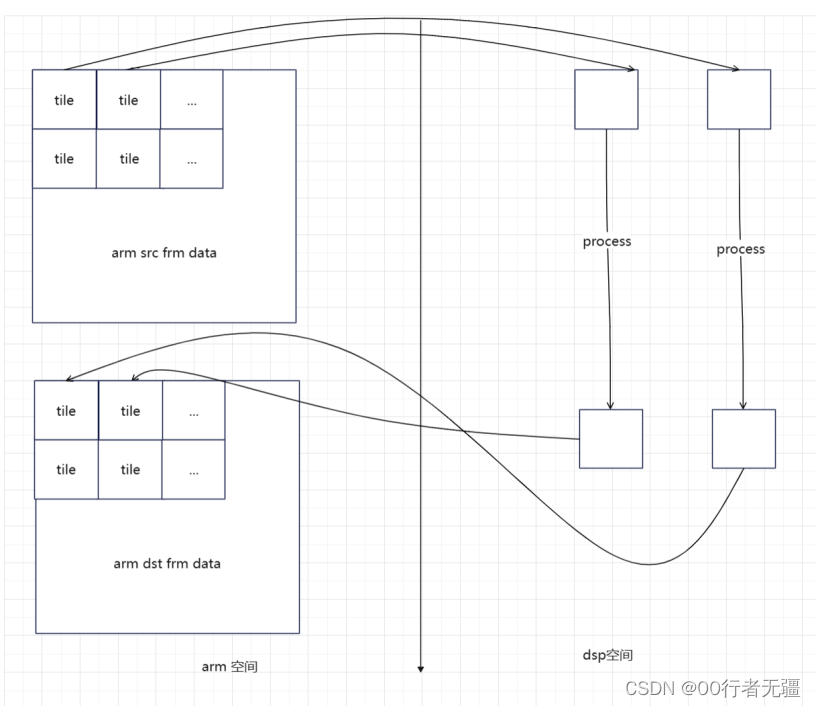
图2 arm/dsp空间数据传输处理示意
需要注意的是dsp端的tile有两种结构xv_tile和xi_tile,结构差别不大,数据传输的时候使用的是xv_tile;数据处理的时候使用的是xi_tile。tile最重要的是需要补边,不同的处理需要补边的大小不同,依据需求而定。
数据传输的过程中遇到一些困难,为了不破坏原来的tile结构体,不好将一个tile绑定多个数据源。因此底层的数据结构没有修改,而是在接口层做了处理,一次可以传输多个数据源。这部分代码处理较冗余,目前没有修改。
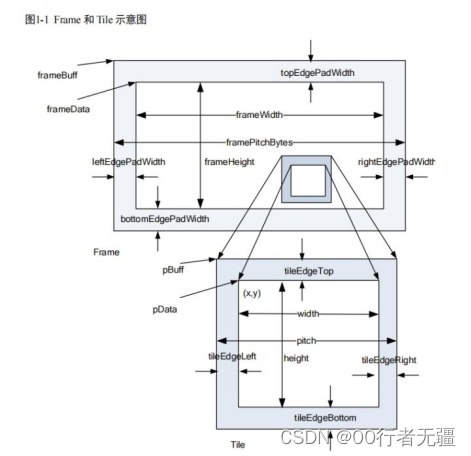
图3 xv_tile示意图

图4 xi_tile示意图
具体算法从略。
这里想分享一个移植的时候遇到的问题,有很多模式,到底先移植哪一个模式的问题。当时想先移植mode 2,觉得这个模式如果走通,其他的模式应该都没有问题了。后来遇到很多困难,才回头确定先把最简单的mode 3做出来,然后再一步步逐步增加难度,不要上来就挑战地狱模式。
刚开始移植完成的时候,测试了下运行的时间,最慢的mode 2处理一帧数据要20+秒,当时心想完了,这要跑到实时,一帧数据数据处理时间是40ms,这中间有500+倍的差距,这能做到吗?和军哥沟通后,看了代码,首先编译的时候没有开启优化选项,把这个打开后,处理时间缩短了10倍,降到了2~3秒。这个时候感觉离目标不远了,还是有希望做到的,毕竟现在dsp最大的性能优化点SIMD利器还没有用起来。
刚开始做的时候也走了一些弯路,想直接调用xtensa提供的IVP操作接口,这个操作接口很不好用,文档也没有,完全不知道IVP操作接口入参的含义。后来找FAE帮忙才找到了一条可行的道路,FAE说libxi库是xtensa帮助客户封装好的各种图像处理接口,不用用户再从新造轮子。于是决定直接调用libxi库,第一、可以省去造轮子的时间(能不能造出来也是问题);第二、这些库提供了足够丰富的图像处理接口,常见的操作都有比如:各种滤波器,中值、均值、高斯,也支持窗口大小调整;canny边缘检测、tile数据的加减乘除,带权的加减几乎都有。
使用libxi提供的API接口对图像做相关的处理后,优化效果非常明显,最耗时的mode 2直接优化到25ms左右。然而这些接口的使用也不是一帆风顺的,由于使用的问题也带来一些问题,比如高斯滤波后,tile单元的最下方会有横线,canny检测后也会有些竖线,横线之类的问题。至于这部分问题的解决还是先确定了问题出在调用方,而不是xtensa的问题,然后排查入参,最终解决了上述问题。
五、总结回顾
5.1开发调试总结
回顾开发的整个过程,遇到了一些问题,记录如下
- arm和dsp数据传输的问题,dsp和arm端数据解析不一致。把内存dump出来发现数据是一样,后来才发现原来是指针字节数不一样导致的,arm端是64位系统,指针占8个字节;dsp端32位系统,指针占4字节。没有注意到这个问题解析出错。
- Tile数据处理方式主要包括兵乓buffer的使用,tile数据扩边,还有一个至关重要的内容就是一个tile绑定一个物理地址,这个是tile结构决定的。后面处理的时候没有打破这个数据结构,而是修改了接口,以前的接口只转递一个tile,现在改为传递多个tile,复用乒乓结构,拷贝数据的时候是独立拷贝的。这里需要特别注意数据copy的宽高、跨距、源地址、目的地址。如果不留意就会出错,uv的高度是y的一半,源和目的都会有所不哦她那个。另外,这里代码有很多冗余,后期可以做继续的调整。
- 数据搬运过程遇到过一些问题,dsp的调试比较困难,因为它是把整帧数据分开处理,不好看中间处理的结果。调试的时候,采用的方法是将中间结果直接传出的方式,来看效果。这个在调试过程种起到很大作用。
- 调用libxi库的时候,遇到最大的一个问题就是滤波之后再做canny检测,结果就不对了,tile的边缘会被检测为边缘。这个问题也是思索很久,因为做过滤波的数据放到一个新的buf里面,而这个buf是没有补边的,所以就被检测出边缘了。关于这个问题的解决,可以再多谈谈当时定位问题的思路。Libxi库是xtensa给的,逻辑上应该是对的,没有问题,但是我不能确定。check了自己的代码,检查了调用流程,因为就是一个api接口,只要入参给的对,那问题应该也不大。但是最终的结果就是不对。当时无法确定问题到底出在哪里,是调用的问题还是库本身的问题呢?直到我调用其他的api接口,发现几乎所有api都不能给出符合预期的结果,于是断定,是调用api的时候,数据没有组织好导致的。从信息论的角度看,要解决一个问题,就需要信息来消除不确定性。这里得到的信息是几乎所有的api都有问题,于是得到数据组织有问题。相反,如果遇到问题,盲目胡乱测试一通,时间浪费了,对问题解决也无益。我想这大概也是很多项目延期的原因,看似忙的一塌糊涂,却做了很多无用功。
- 配准矩阵的摸索,opencv先做出一个配准矩阵和效果,然后尝试给hisi gdc模块使用,最终得到了和opencv相同的结果,这里也踩了一些坑,这里最大的问题是并不清楚配准矩阵的workflow。有如下的问题需要解决:1、opencv得到的配准矩阵和hisi的硬件兼容吗?2、计算配准矩阵的时候输入原始数据的分辨率是否要相同?3、怎么用opencv得到配准矩阵?4、配准矩阵怎么使用,如何嵌入到gdc模块等。这些问题都没有答案,靠着和军哥、永生、红娟,一起摸着石头过河,最终得以解决。
- 移植dsp库的时候,遇到过一个canny检测问题,那个时候使用的是自己的canny算法,得到的结果是tile小块里面,有的是有正常轮廓的,有的轮廓是异常。
如下图所示:

当时也是check了很久,发现代码没有问题,仔细了解了整个算法的逻辑。才知道原来canny检测的时候用到了一个统计信息做阈值。分块tile处理的时候,每一个块的阈值都不同,导致了不符合预期的效果。
其他问题不再一一赘述,后续发现有价值的问题,可以再继续往上加。总之,遇到问题解决问题是一个工程师需要不断修炼的能力。
现在检测的效果上还是有些噪点,后续可以考虑使用其他窗口的滤波器测试。另外现在canny检测的阈值是写死的,后期可以考虑对每帧数据做统计,计算出阈值,将阈值应用到下一帧上去。
现在代码种还有部分处理是没有用SIMD指令的,因为libxi没有相关的接口,这部分需要自己造轮子的。
在开发调试过程中,很多同事、fae给予很大的帮助,这里不能一一表示感谢,而是笼统的向他们表示敬意

![[SOLO ]SOLO: Segmenting Objects by Locations代码解读笔记(ECCV. 2020)](https://img-blog.csdnimg.cn/20201130155401981.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzgyMzg1NA==,size_16,color_FFFFFF,t_70#pic_center)