SVO代码中初看的时候有点凌乱,这里再梳理下帮助阅读代码。
初始化:
作者用第一帧为基准,检测特征点,然后后面来的帧一直用第一帧的特征点做光流跟踪。个人感觉这是个bug, 应该改成当前帧和前一帧做光流跟踪,而不是一直只用第一帧跟踪,这样改了以后初始化鲁邦了很多,特别是在畸变较大的摄像头上。
算法第一步,稀疏直接法:
稀疏直接法在Config::kltMaxLevel(), Config::kltMinLevel()这几个图像金字塔层之间迭代,比如参数设定的是4,2,那直接法开始时的图像分辨率是40×30, 优化得到一个结果作为初始值传给下个金字塔层进行直接法迭代优化位姿,最后结束迭代的分辨率是160×120. 程序里会统计用于直接法计算的残差的特征点个数 n_meas_/patch_area_, n_meas_表示前一帧所有特征点块(feature patch)像素投影后在cur_frame中的像素个数。特征点数还要用n_meas_/patch_area_.
如果跟踪的像素个数少,那就跟踪失败,下一帧开始重定位。
补充一句: sparseImgAlign 继承nlls_slover.h的算法模块类,直接法的计算流程来自于nlls_sover_impl.hpp. SparseImgAlign中实现每个函数具体的计算形式。
算法第二步, 重投影:
重投影主要是把地图里的point投影到当前帧中,在往下理清思路前,有必要知道地图点和关键帧上的图像特征点是如何联系的。如下图所示,首先地图点P存储的是他们在世界坐标系中三维坐标,因此,他们可以自由的投放到任意帧上去。另外,地图点记录了哪些帧上的特征点能够观测到它,比如,通过 p2i,p2j 能够找到地图点 P2 ,反过来,地图点 P2 也知道 p2i,p2j 能够观测到它。
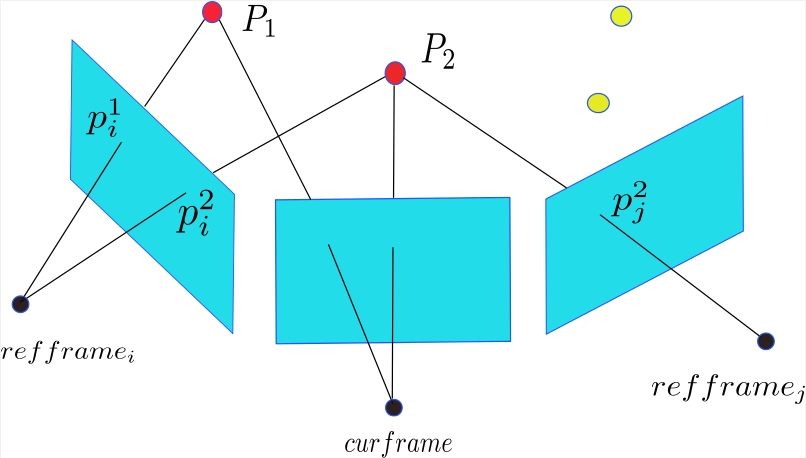
现在,回到重投影步骤,地图里的map point众多,我们只需要把临近关键帧(overlap_kfs)观测到的point点做投影,如 P1,P2 ,当然还有那些没插入kf上的point_candidates_也要往cur_frame上投。投的时候先利用关键帧和cur_frame的距离排序,最近的关键帧上的先投影,找到关键帧后,遍历关键帧上的特征点,通过特征点找到地图点,然后一一投影到当前帧。注意,一个地图point点只需要投一次,所以比如 P2 通过ref_frame i投影了一次,就不用通过ref_frame j再投一次了。投影过程如下图所示:
这样cur_frame的每个cell里就有了多个投影点, 每个cell只挑选1个质量最好的特征点。注意,这里作者为了速度考虑,不是对图像上的所有cell都挑选,随机挑选了maxFts这么多个cell。这就意味着并不是所有的投影地图点都会来用后面的pose,struct 优化。
for(size_t i=0; i<grid_.cells.size(); ++i){// we prefer good quality points over unkown quality (more likely to match)// and unknown quality over candidates (position not optimized)if(reprojectCell(*grid_.cells.at(grid_.cell_order[i]), frame))++n_matches_;if(n_matches_ > (size_t) Config::maxFts()) break;}程序中grid_.cell_order[i]是用随机函数打乱了cell的排序.
random_shuffle(grid_.cell_order.begin(), grid_.cell_order.end());在此之前,我们都不用去追究是谁把 P2 投影到cur_frame的,投影上来了就行。但是,投影地图点的最终目的是在cur_frame中的投影点附近找到一个和地图点对应特征点能够匹配的点。这样就找到了cur_frame中特征点和kfs上特征点的匹配关系,就可以用来进行bundle adjustment。要注意,一个地图点可能连着多个特征点,比如 P2 到底选择ref_frame i中 p2i 还是ref_frame j中的 p2j 作为和cur_frame中匹配的特征点呢?地图中的point点通过变量obs_记录了它和哪些特征是联系起来的,这里它知道自己连着 p2i,p2j ,地图point点会通过一些筛选机制来选择是用 p2i 还是用 p2j ,具体实现在getCloseViewObs函数中。
第三步:优化
利用重投影以后的特征点开始位姿及结构优化。位姿优化的时候,会根据投影误差丢掉一些误差大的特征点,最后留下来进行位姿优化的这些特征点被变量sfba_n_edges_final记录下来,利用它来判断跟踪质量好不好setTrackingQuality(sfba_n_edges_final). 跟踪不好的判断依据是,用于位姿优化的点数sfba_n_edges_final小于一个阈值,或者比上一帧中用于优化的点减少了很多。
重定位:
重定位是根据上一次成功定位的frame的坐标选择一个最近的关键帧,然后新采集的new_frame先使用直接法跟踪找到的最近关键帧closest_kf. 如果跟踪上了,那就开始上面的2,3步重投影、位姿优化。如果合格,那就重定位成功。
那么什么的条件能够使得跟踪失败呢?重定位的条件:
1.直接法跟踪上一帧以后,用于跟踪的像素点数(作者用的特征点数,其实就是像素点数)太少。
comment: 这一步失败一部分是由于位姿变化大,上一帧的点投影不上去。另一部分原因是上一帧上的特征点数目本来就少,再跟丢一点那就更少了。上一帧的特征数目是由重投影以及位姿优化决定的。按理来说,重投影的都是关键帧上的点,这样重投影的时候特征点数目应该足够多呀。可是事实是投影的地图点数确实比较多,但貌似都集中到几个cell里了。
2.重投影以后,利用多关键帧和当前帧的匹配点进行相机位姿优化的过程中,不断丢弃重投影误差大的点。优化完以后,如果inlier数目较少,跟踪失败,开启重定位。如果这次优化过程中的点比上一帧少很多,那也认为跟踪失败,开启重定位。
comment:调试程序的过程中发现,很多时候,虽然用于优化的点比上一帧少,但是优化过程中丢弃的outlier也很小,说明跟踪质量应该是好的,这样不应该开启重定位呀。
SVO里关键帧上的特征点如何来的:
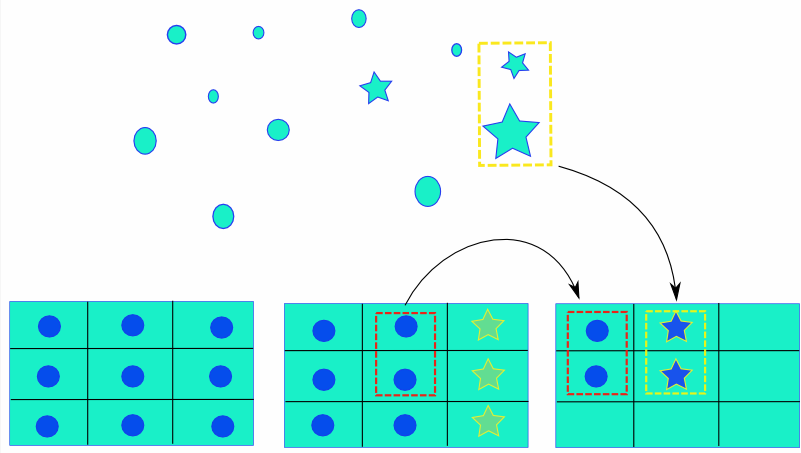
如上图所示,假设有三个关键帧a,b,c。关键帧a上所有的cell里都有特征点,上图中9个圆形特征点,并且他们都已经有了对应的三维坐标,是point了。但是运动过程中,重投影到关键帧b上只有6个了。这时候在关键帧b上没有特征点的单元格里检测新的特征点,3个星星,这三个特征点深度还没有,得依靠后续的帧不断滤波,收敛。等到深度值收敛以后成为candidate point,在下一次新关键帧c到来的时候,将他们挂到最开始检测到他们的关键帧b挂上去。当然也不是所有的candidate point 都能挂到新关键帧上,因为有的candidate point 在新关键帧上观测不到。那这些candidate point 只能永远留在candidate队列里了,除非他们多次投影失败,那就会从队列删除。
关于SVO总是丢失特征,并重定位的一些改进思路:
由于我的摄像头就是普通的网络摄像头,30fps, 非全局曝光,快速运动以后,各种模糊,导致总是丢失特征并重启svo,把svo算法里的一些参数修改后,能有效缓解:
1. 修改重定位触发条件,FrameHandlerBase::setTrackingQuality中第二判断条件认为如果当前帧上的特征点比上一帧少一定数量,就重启。这个条件改成outlier的数量不多于一个阈值。
2. 修改grid大小,增加特征点数,有利于重投影。修改max_fts个数,这个参数感觉很重要,因为它限制了重投影到当前帧上点的数目,程序里限制当投影的cell数目到了max_fts就不再投影。
3. 前面两个改动都不会怎么影响定位精度,并且并没有解决特征丢失的问题,只是修改了特征丢失后开始重定位的一些条件。特征丢失最根本的地方在于feature_alignment,它使用KLT对投影点位置求精。我实际调试的时候发现,当前帧上的特征投影点位置和以前关键帧上的特征点很接近,但是特征位置refine以后反而丢失了。这是因为refine迭代的时候条件太苛刻,作者想要的是高精度吧。对于我们这种对总是丢失忍无可忍的,那就把迭代终止条件放宽松点就好了。
4. 还可以修改config.cpp里的位姿优化时投影的误差阈值poseoptim_thresh
另外,大家若会想修改关键帧的判断阈值,使得关键帧增加速度加快。这么做有利于特征点数量的增加,也有利于重定位时最近关键帧和当前帧的匹配。但是同时要注意,应该加大depth filter中seed的移除阈值。因为depth filter中认为一个seed如果在经历了N个关键帧后,还没收敛到candidate point,那么就把它删掉。这个阈值为depth_filter.h 文件中的max_n_kfs,初始值为3。
编译问题:
vikit package 找不到sophus:
本来已经安装好了svo,跑的挺好,然后我又安装了dvo_slam,或lsd_slam,这两个程序也要使用sophus,所以再重新回去使用svo的时候出问题了。解决办法
1. ~/.cmake/Sophus 文件夹下有两个文件,打开,看到一个路径指向dvo_slam文件夹,一个路径指向svo文件夹。把dvo_slam那个删掉。
2. 找到catkin_ws/build文件夹,全删掉,重新catkin_make 编译。
博文只是作者的一些笔记,所以难免会有错误,不吝指出。






