一,SE:Squeeze-and-Excitation的缩写,特征压缩与激发的意思。
可以把SENet看成是channel-wise的attention,可以嵌入到含有skip-connections的模块中,ResNet,VGG,Inception等等。
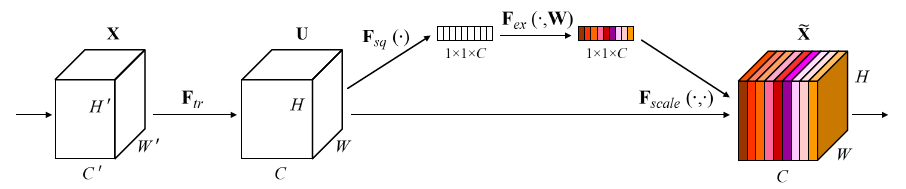
二,SE实现的过程
1.Squeeze: 如下图的红框。把每个input feature map的spatial dimension 从H * W squeeze到1。一般是通过global average pooling完成的,Squeeze操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
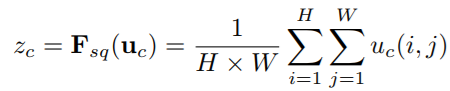
2.Excitation: 如下图的绿框。通过一个bottleneck结构来捕捉channel的inter-dependency,从而学到channel的scale factor(或者说是attention factor) 。
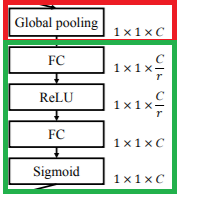
3.Reweight的操作
将Excitation的输出的权重看做是特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。即实现attention机制。
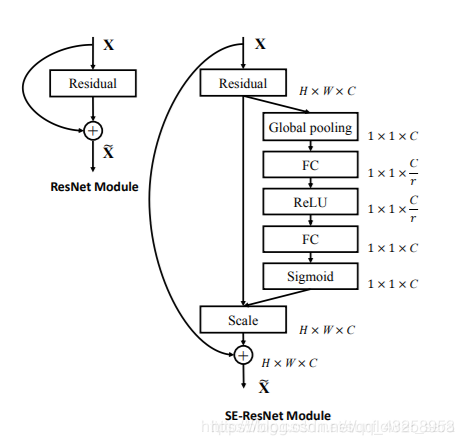
三,在resnet中加入SE。
下图是SE-ResNet, 可以看到SE module被apply到了residual branch上。我们首先将特征维度降低到输入的1/r,然后经过ReLu激活后再通过一个Fully Connected 层升回到原来的维度。这样做比直接用一个Fully Connected层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个Sigmoid的门获得01之间归一化的权重,最后通过一个Scale的操作来将归一化后的权重加权到每个通道的特征上。在Addition前对分支上Residual的特征进行了特征重标定。如果对Addition后主支上的特征进行重标定,由于在主干上存在01的scale操作,在网络较深BP优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。