tensorflow1.15.5也算是很久远的包了,但其实我一直用的是1.14.0的版本。但因为更新了GPU,在A100的卡上tf1.14.0版本没法做有些大矩阵运算,会报错:
Internal: Blas xGEMMBatched launch failed : a.shape=[135,84,84], b.shape=[135,84,16], m=84, n=16, k=84, batch_size=135[[node my_attn_7/MatMul (defined at /public_bme/home/liufh/GAT-master/utils/layers.py:24) ]]
参考这两个帖子“利用A100 GPU加速Tensorflow描述” 和“rtx3090搭建tensorflow1.15环境”,它们给出的建议是用官方在A100 上优化的tensorflow,也就是pip install nvidia-pyindex 和pip install nvidia-tensorflow这样的方法安装。
但是也因为软件版本、显卡驱动不匹配等问题,还报了不少错。把问题总结出来,方便排错。
- python版本问题,在python3.7的环境下(在python3.8的环境下可解决,感谢 RTX3090 tensorflow1.x报错:Blas GEMM launch failed),无论是
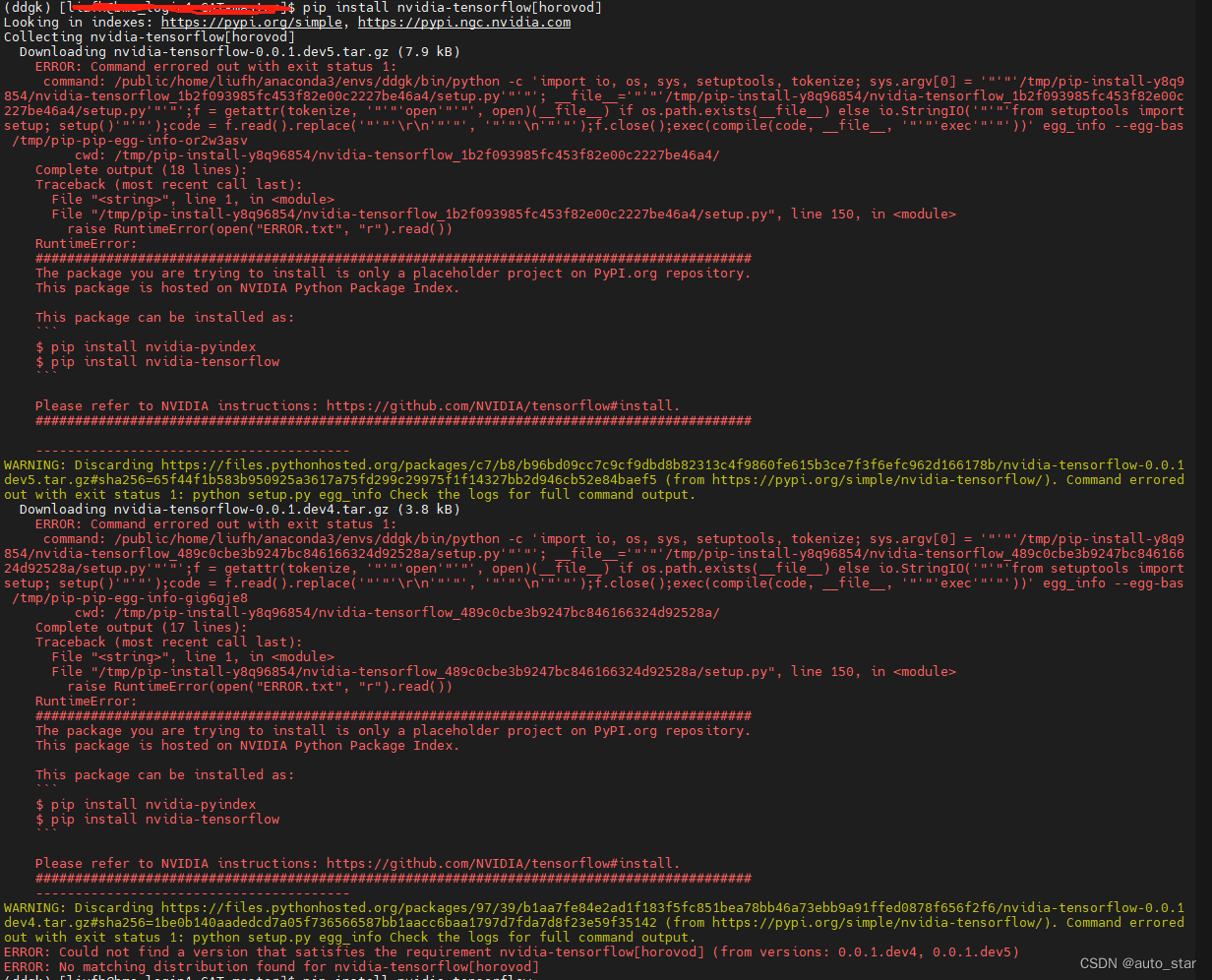
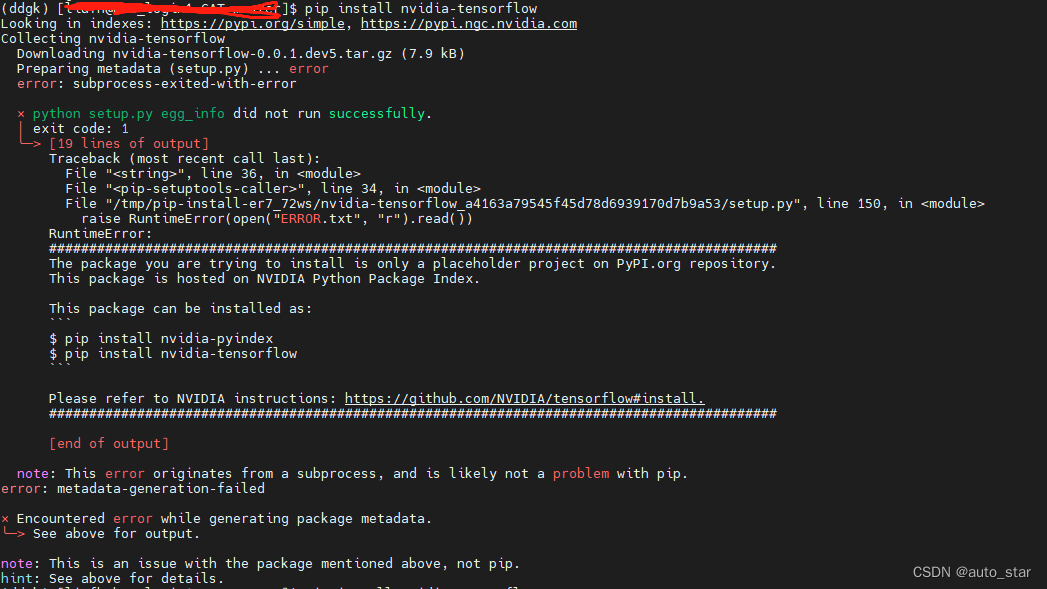
pip install nvidia-tensorflow,还是pip3 install tf-nightly-gpu,或是pip install nvidia-tensorflow[horovod],tensorflow的安装这一步死活无法完成,。会报很多错误,例如
(1)Preparing metadata (setup.py) ... error error: subprocess-exited-with-error
(2)note: This error originates from a subprocess, and is likely not a problem with pip. error: metadata-generation-failed × Encountered error while generating package metadata. - 显卡驱动版本问题,在python3.8的环境下,
pip install nvidia-tensorflow就可以简单得完成tensorflow的安装,然而这样是默认安装的最新版tensorflow,也就是nvidia_tensorflow-1.15.5+nv23.03-7472065-cp38-cp38-linux_x86_64.whl这个版本,然而这个版本会依赖cuda 12,这样需要高版本的显卡驱动。我自己的是NVRM version: NVIDIA UNIX x86_64 Kernel Module 470.82.01版本,只能支持cuda 11.0. 感谢CUDA driver version is insufficient for CUDA runtime version 的解决方案,提供思路,程序无法执行,网络没法训练,会报错“cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version”。解决办法很简单,就是下载低版本的轮子,手动安装,URL:https://developer.download.nvidia.cn/compute/redist/nvidia-tensorflow/。我通过安装
nvidia_tensorflow-1.15.5+nv22.01-3720650-cp38-cp38-linux_x86_64.whl
之后就成功了。在安装过程中,部分包的版本需要手动调,***protobuf ***,numpy和scipy需要特别注意。否则会报错 TypeError: Descriptors cannot not be created directly.
- 轮子版本问题,最开始我直接安装的是最低版本的tensorflow1.15,
nvidia_tensorflow-1.15.5+nv21.02-cp38-cp38-linux_x86_64.whl
,可以成功安装,但是找不到tensorflow,无法训练网络,报错 ImportError: /lib64/libm.so.6: version GLIBC_2.27 not found (required by /public/home/liufh/anaconda3/envs/tf115/lib/python3.8/site-packages/tensorflow_core/python/_pywrap_tensorflow_internal.so)
总结一下,如果安装不能成功,我踩到的坑包括了python 版本,显卡驱动版本,以及安装的轮子版本这三方面的问题,解决了这三方面问题之后,就成功训练了啊。部分错误截图如下
1.