最近,一则灯塔国禁止英伟达向中国出售高端GPU的新闻引发了众多关注。大家虽然对芯片禁售早有心理预期,但现实比预料中发展的更快。对于GPU,可能大多人还只关注在图形图像与人工智能领域。而随着GPGPU的不断演进,在实时OLAP领域,GPU在与分布式数据库的对抗中,另辟蹊径,性能亮眼。因其强大的并行计算能力带来了极强的吞吐优势,GPU非常适用于结算批处理,实时风控等场景。

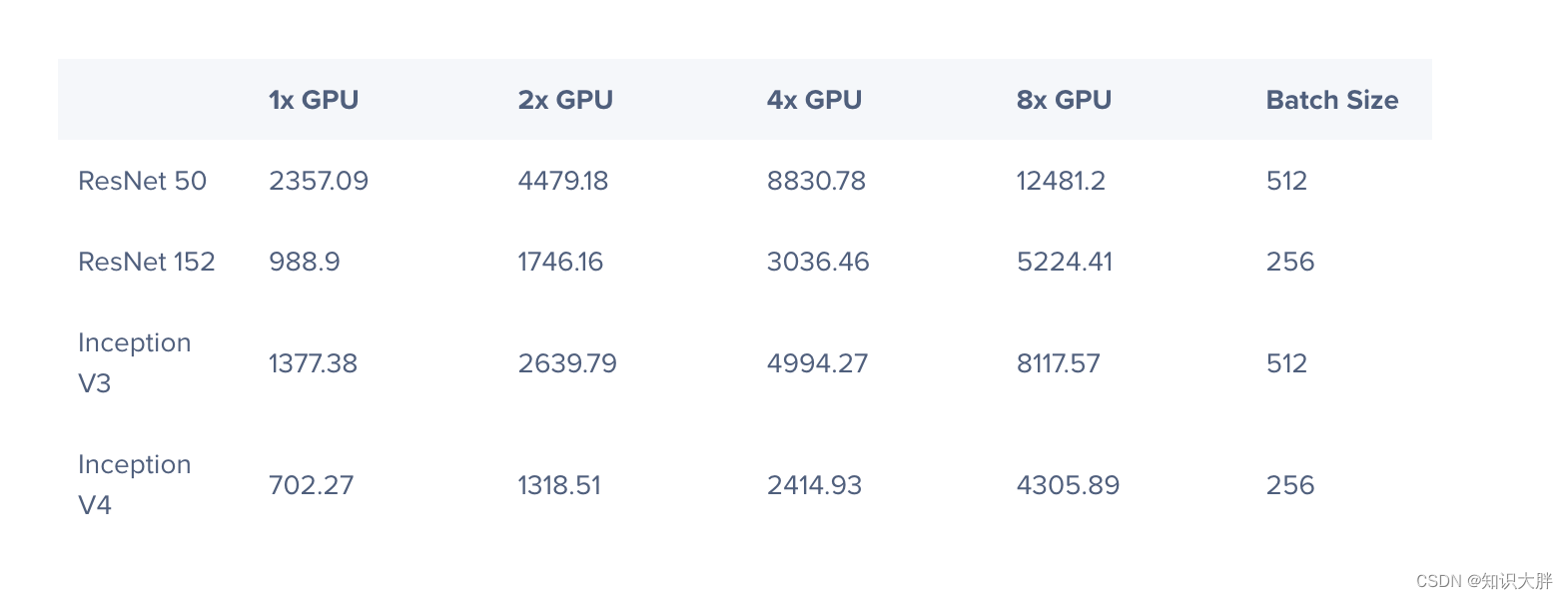
以结算过程中较为复杂的平今仓计算为例,我用一块A100进行了测试尝试。该测试模拟了对一定数量成交以分组计算每个客户平今仓数量。此处的平今仓[1],指的是以先进先出或后进先出的算法将成交区分为平今日持仓或平昨日持仓。从实测结果看,GPU的性能较CPU提升在1个数量级左右,数据量越大,优势越为明显。其测试结果如下,代码附于文末:
| 成交笔数 | 客户数 | GPU时间 | CPU时间 |
|---|---|---|---|
| 100万 | 1万 | 0.4秒 | 1.3秒 |
| 1000万 | 10万 | 1.3秒 | 15秒 |
| 1亿 | 100万 | 7.6秒 | 笔记本没跑出来 |
GPU并行批处理的优势
在编写原型的过程中,有如下感受:
研发效率高
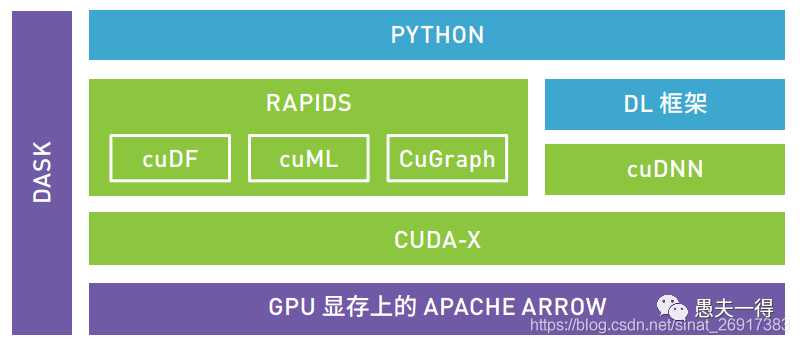
我用的是英伟达自家开源的rapids cudf[2]库。该库采用python的类pandas的接口,对数据处理接口抽象好。只要有些数据分析,或是sql经验的数据分析人员,经过简单培训,就能快速上手。因为rapids对深挖GPU价值发挥而言具有重大战略意义,因此听说黄教主亲自主抓,招募了多位大牛投入这个项目中。同时,还有另一个blazerSQL[3]项目可以提供sql层和stream层接口。这些套路,与spark和flink基本是一致的。
性能炸裂
GPGPU适合实时OLAP,可充分利用GPU多核算力,打破CPU摩尔定律瓶颈。从GPU核底层算法来看,数据量越大,其并发效率越高。这恰恰是OLAP场景下CPU方式的短板。而且,GPU目前仍以摩尔定律速度发展,因此基于GPU的技术方案可以一直吃硬件红利。其高性能对OLAP的场景主要体现在 join和group by等可并行计算的场景。从计算引擎底层算法而言,GPU采用的并不是传统数据库的火山模型,而是用对SIMD更加友好的批量模型[4]。比如,在并行排序上,bitonic top-k算法[5]以分治的思想将多核的威力分多个时钟周期整合起来,与传统的快排算法等存在较大不同。因此,GPU在小数据量的延迟上敌不过CPU,但在大数据量情况下,以其计算核人多势众的优势,能在吞吐和总延迟上扳过CPU。
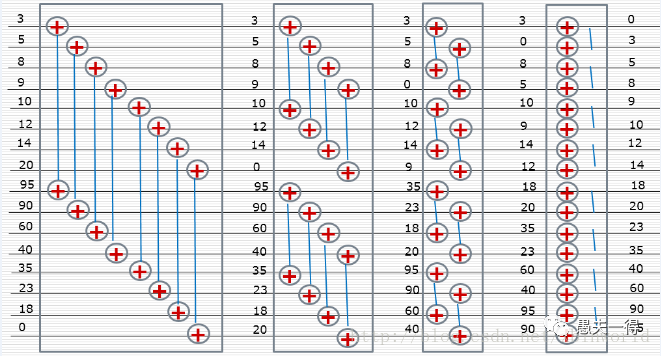
运维便利
这是因性能强大衍生而来。用基于CPU的数据分析方案,若要提高吞吐,则只能往MPP分布式数据库方向去堆机器解决,虽然这对开发而言是透明的,但对运维绝对是一个负担。其实,维护任意flink、spark、hadoop的集群,若没有4-5人团队投入,深入研究底层技术细节,是很难能hold住线上应急排障等问题的。若底层用容器甚至是K8S环境,那投入则更大。所以,对于中小型证券期货公司的计算量与运维能力,基于GPU的单机解决方案绝对是最为经济划算的,预估1~2人的投入即可。
GPU方案存在的问题
分析数据的容量
原因是GPU的显存是有限的,因此对于分析超出GPU显存大小(目前顶配英伟达A100显存为40G)的数据,无法一次性装载。解决方案是用dask等分布式方案,这一定程度会提升架构复杂性。对于金融类企业,对于日内数据量而言,这些显存基本也是够用了。但对于分析海量数据,则需要考虑多块显卡。因此,实时OLAP的场景可能是GPU最适合的典型切入场景。
不符合自主可控要求
此次禁售事件所预示着GPU全面禁封的可能性。当然,若想屏蔽这个风险,也可以采用在中间加一层spark3.0的方式。spark自3.0开始底层原生支持rapids,对上层应用开发是透明的。据了解,flink目前仍不支持GPU,不知道是否是逐笔的机制无法像spark微批机制那样做批量处理。
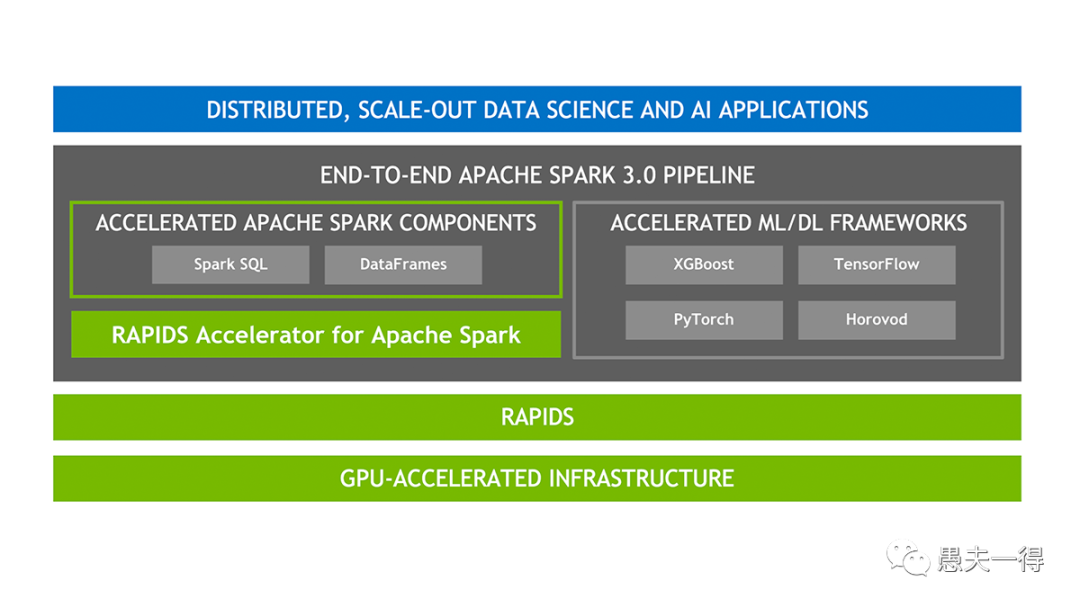 cpu或操作系统的国产替代,不但有arm和x86的选择,而且工具链至少是可用的。可这GPU,国内虽然也有少数几家,但与英伟达的差距类比于CPU而言更大。而且整体生态链的支撑问题更大。cuda才是英伟达能迅速霸占市场的大杀器,是GPU编程框架的事实标准。虽然也有opencl与之抗衡,但两者支持者差距甚大,以至于现在国内GPU厂商为了妥协都不得不采用cuda的标准。若要另起炉灶自研一套,就岂非几年时间能赶得上了,这可类比芯片行业掐脖子的EDA软件。当然,目前这形势,这场硬仗是不得不去打的,其紧迫性和必要性被提升了。
cpu或操作系统的国产替代,不但有arm和x86的选择,而且工具链至少是可用的。可这GPU,国内虽然也有少数几家,但与英伟达的差距类比于CPU而言更大。而且整体生态链的支撑问题更大。cuda才是英伟达能迅速霸占市场的大杀器,是GPU编程框架的事实标准。虽然也有opencl与之抗衡,但两者支持者差距甚大,以至于现在国内GPU厂商为了妥协都不得不采用cuda的标准。若要另起炉灶自研一套,就岂非几年时间能赶得上了,这可类比芯片行业掐脖子的EDA软件。当然,目前这形势,这场硬仗是不得不去打的,其紧迫性和必要性被提升了。
总结
• 对于亿级左右的实时OLAP,基于rapids的GPU解决方案值得尝试。 在研发效率、吞吐性能、易运维等多方面都具有对比于诸如分布式数据库、spark、flink等其他技术方案的先进性。
• 大数据的蓬勃发展,为金融企业数据处理应用场景提供了新的选择。 传统的企业级数据类应用开发,大多基于sql。而目前可以依据对处理数据特征的不同,细分出了很多场景与可选工具与平台。诸如结算批处理、实时风控等中等规模批量数据处理场景,用pandas或是cudf进行开发已经成为一种选择。
引用链接
[1] 平今仓: https://zhuanlan.zhihu.com/p/530049543
[2] rapids cudf: https://rapids.ai/
[3] blazerSQL: https://rapids.ai/blazingsql.html
[4] 批量模型: http://www.jos.org.cn/html/2021/3/6175.htm
[5] bitonic top-k算法: https://blog.csdn.net/xbinworld/article/details/76408595
cuDF版本:
import cudf as cd
import numpy as np
import time as tmn = 1000000 # 成交数量
c = 10000 # 客户数量
i = 1000 # 合约数量trade = cd.DataFrame({"client" : np.random.randint(1234567, 1234567+c, n),"instrument": np.random.randint(100, 100+i, n), "offset" : np.random.randint(0, 2, n),"vol" : np.random.randint(1, 5, n),})begin = tm.time()
trade['cumopen'] = trade.loc[ trade['offset']==0, ['client','instrument','vol'] ].groupby(['client','instrument']).cumsum()
trade['cumclose'] = trade.loc[ trade['offset']==1, ['client','instrument','vol'] ].groupby(['client','instrument']).cumsum()
trade.fillna(method='ffill', inplace=True)
trade.fillna(0, inplace=True)trade['cumnet'] = trade['cumopen']-trade['cumclose']
trade['offtoday'] = (trade['cumclose'] + trade.groupby(['client','instrument'])['cumnet'].cummin().applymap( lambda x: x if x<=0 else 0 )).applymap( lambda x: x if x>=0 else 0 )
end = tm.time()print( trade.groupby(['client','instrument']).max() )
print( "run time : ", end-begin )
pandas版本:
import pandas as pd
import numpy as np
import time as tmn = 1000000 # 成交数量
c = 10000 # 客户数量
i = 1000 # 合约数量trade = pd.DataFrame({"client" : np.random.randint(12345678, 12345678+c, n),"instrument": np.random.randint(100, 100+i, n), "offset" : np.random.randint(0, 2, n),"vol" : np.random.randint(1, 5, n),})def caloffset( df ):df['cumopen'] = df.loc[ trade['offset']==0, ['vol'] ]df['cumclose'] = df.loc[ trade['offset']==1, ['vol'] ]df.fillna(0, inplace=True)df['cumopen'] = df['cumopen'].cumsum()df['cumclose'] = df['cumclose'].cumsum()return (df['cumclose'] + (df['cumopen']-df['cumclose']).cummin().transform( lambda x: x if x<=0 else 0 )).transform( lambda x: x if x>=0 else 0 ).max()begin = tm.time()
print ( trade.groupby(['client','instrument']).apply( caloffset ) )
end = tm.time()print( "run time : ", end-begin, "s" )