在数据处理和分析领域,我们经常需要根据用户的行为数据进行筛选和标签添加,以便更好地理解用户行为和偏好。在本篇博客中,我们将介绍两个示例,展示如何根据用户的收视行为数据和订单信息进行数据处理和分析。
前情提要:
数据集分析:
广电用户画像分析之探索各个表中的记录数和字段phone_no的空值数 )
数据预处理:
广电用户画像分析之数据基本分析与预处理)
根据用户收视行为数据中地区和语言偏好筛选数据
完整代码:
package code.userprintimport org.apache.spark.sql.SparkSessionobject MediaPrint {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val spark = SparkSession.builder().appName("media").master("local[*]").enableHiveSupport().getOrCreate()//spark.sparkContext.setLogLevel("WARN")val media = spark.table("Processdata.media_index")import org.apache.spark.sql.functions._// media.selectExpr("max(end_time) as max_month")
// .selectExpr("add_months(max_month,-3) as beforeTime").show() // 2018-04-30media.filter("end_time > '2018-04-30'").groupBy("phone_no","audio_lang").agg(sum("duration")/(1000*60*60)/3 as "avgduration").filter("avgduration > 5").select("phone_no","audio_lang").write.mode("overwrite").saveAsTable("userPrint.languagePrint")media.filter("end_time > '2018-04-30'").groupBy("phone_no","region").agg(sum("duration")/(1000*60*60)/3 as "avgDuration").filter("avgDuration > 5").select("phone_no","region").write.mode("overwrite").saveAsTable("userPrint.regionPrint")}
}该类的目的是根据用户观看媒体的语言和地区信息,统计其在过去三个月内的平均观看时长,并筛选出观看时长大于5小时的用户,将结果存储在两个不同的Hive表中,分别为languagePrint和regionPrint。
思路:
从表Processdata.media_index中读取数据,得到一个DataFrame对象media。
在media中筛选出end_time大于’2018-04-30’的记录。
按照phone_no和audio_lang进行分组,使用agg函数计算duration字段的总和,并将结果除以3(毫秒转换为小时),得到每月平均持续时间avgduration。
筛选出平均持续时间大于5小时的记录,选择phone_no和audio_lang两列。
将结果保存为名为languagePrint的Hive表。
再次在media中筛选出end_time大于’2018-04-30’的记录。
按照phone_no和region进行分组,使用agg函数计算duration字段的总和,并将结果除以3(毫秒转换为小时),得到每月平均持续时间avgDuration。
筛选出平均持续时间大于5小时的记录,选择phone_no和region两列。
将结果保存为名为regionPrint的Hive表。
核心代码:
val media = spark.table(“Processdata.media_index”)
media.filter(“end_time > ‘2018-04-30’”)
.groupBy(“phone_no”,“audio_lang”).agg(sum(“duration”)/(10006060)/3 as “avgduration”)
.filter(“avgduration > 5”).select(“phone_no”,“audio_lang”)
.write.mode(“overwrite”).saveAsTable(“userPrint.languagePrint”)
media.filter(“end_time > ‘2018-04-30’”)
.groupBy(“phone_no”,“region”).agg(sum(“duration”)/(10006060)/3 as “avgDuration”)
.filter(“avgDuration > 5”).select(“phone_no”,“region”)
.write.mode(“overwrite”).saveAsTable(“userPrint.regionPrint”)
根据订单信息筛选产品名称
完整代码:
package code.userprintimport org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Windowobject OfferName {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val spark = SparkSession.builder().appName("MediaAnalyse").master("local[*]").enableHiveSupport().getOrCreate()//spark.sparkContext.setLogLevel("WARN")// 过滤 offername 不为空,且cost<=0val TVorder = spark.read.table("processData.order_index").filter("offername is not null").filter("cost > 0")// 筛选电视业务.filter("sm_name != '珠江宽频'")val BDorder = spark.read.table("processData.order_index").filter("offername is not null").filter("cost > 0")// 筛选宽带业务.filter("sm_name like '珠江宽频'")// 电视主销售品import org.apache.spark.sql.functions._val TVMainOffer = TVorder.filter("mode_time='Y' and offertype=0 and prodstatus='YY'").select(col("phone_no"), col("offername"),// 以用户作为窗口分组的标准,再以 optdate 排序(根据排名),获取排名为 1 ,// 由于根据 optdate 进行降序排序,所以排名为 1 的即为 optdate 最大值row_number().over(Window.partitionBy("phone_no").orderBy(desc("optdate"))) as "rn").filter("rn==1").select(col("phone_no"), col("offername"))// TVMainOffer.show()// 电视附属销售品val TVOffer = TVorder.filter("mode_time='Y' and offertype=0 and prodstatus='YY'").select(col("phone_no"), col("offername"))// TVOffer.show()// 宽带val BDDffer = BDorder.select(col("phone_no"), col("offername"),row_number().over(Window.partitionBy("phone_no").orderBy(desc("optdate"))) as "rn").filter("rn==1").select(col("phone_no"), col("offername"))// BDDffer.show()// 拼接val TVOfferName = TVMainOffer.union(TVOffer).union(BDDffer).distinct()
// val TVOfferName = TVMainOffer.union(TVOffer).union(BDDffer)
// TVOfferName.show()TVOfferName.write.mode("overwrite").saveAsTable("userPrint.TVOfferName")// BDofferName (宽带产品构建)val BDOfferordeResult = BDorder.select(col("phone_no"), col("prodname"),row_number().over(Window.partitionBy("phone_no").orderBy(desc("optdate"))) as "rn").filter("rn==1").select(col("phone_no"), col("prodname"))BDOfferordeResult.write.mode("overwrite").saveAsTable("userPrint.BDOfferName")}
}
该类的目的是创建一个消费者标签(Consumer Label)。它通过读取名为mmconsume_billevents的表中的数据,根据字段"phone_no"和"fee_code"进行去重,然后使用自定义的函数consumerLabel为每个消费者分配一个标签,最后将结果保存到名为consumerLabel的表中。
思路:
读取数据:使用spark.read.table()方法从表processData.order_index中读取数据,并将其分别赋值给TVorder和BDorder两个变量。
过滤数据:对TVorder和BDorder进行过滤操作,筛选出满足条件的数据集。可以使用filter()方法和SQL表达式来实现条件过滤。
电视业务处理:
主销售品:对TVorder进行条件筛选,选择mode_time=‘Y’、offertype=0和prodstatus='YY’的数据,并按phone_no分组,按optdate降序排序,使用窗口函数row_number()获取每组中排名为1的最新数据,将结果命名为TVMainOffer。
附属销售品:对TVorder进行条件筛选,选择mode_time=‘Y’、offertype=0和prodstatus='YY’的数据,并提取phone_no和offername字段,将结果命名为TVOffer。
宽带业务处理:
宽带销售品:对BDorder进行条件筛选,选择sm_name like '珠江宽频’的数据,并按phone_no分组,按optdate降序排序,使用窗口函数row_number()获取每组中排名为1的最新数据,将结果命名为BDDffer。
合并数据:将TVMainOffer、TVOffer和BDDffer三个数据集进行合并,可以使用union()方法实现,并去重,将结果命名为TVOfferName。
保存结果:将TVOfferName数据集保存为名为TVOfferName的Hive表,使用write.mode(“overwrite”).saveAsTable(“userPrint.TVOfferName”)实现。
宽带销售品保存:对于宽带业务,根据条件筛选出最新的销售品名称数据集,将结果命名为BDOfferordeResult,然后将其保存为名为BDOfferName的Hive表,使用write.mode(“overwrite”).saveAsTable(“userPrint.BDOfferName”)实现。
核心代码:
从表processData.order_index中读取数据,并进行过滤操作,筛选出满足条件的数据集。
val TVorder = spark.read.table(“processData.order_index”)
.filter(“offername is not null”)
.filter(“cost > 0”)
.filter(“sm_name != ‘珠江宽频’”)
val BDorder = spark.read.table(“processData.order_index”)
.filter(“offername is not null”)
.filter(“cost > 0”)
.filter(“sm_name like ‘珠江宽频’”)
针对电视业务,根据一定的条件筛选出主销售品和附属销售品,并获取最新的销售品名称,构建TVMainOffer和TVOffer数据集。
val TVMainOffer = TVorder.filter(“mode_time=‘Y’ and offertype=0 and prodstatus=‘YY’”)
.select(col(“phone_no”), col(“offername”), row_number().over(Window.partitionBy(“phone_no”).orderBy(desc(“optdate”))) as “rn”)
.filter(“rn==1”)
.select(col(“phone_no”), col(“offername”))
val TVOffer = TVorder.filter(“mode_time=‘Y’ and offertype=0 and prodstatus=‘YY’”)
.select(col(“phone_no”), col(“offername”))
针对宽带业务,根据一定的条件筛选出销售品,并获取最新的销售品名称,构建BDDffer数据集。
val BDDffer = BDorder.select(col(“phone_no”), col(“offername”), row_number().over(Window.partitionBy(“phone_no”).orderBy(desc(“optdate”))) as “rn”)
.filter(“rn==1”)
.select(col(“phone_no”), col(“offername”))
将TVMainOffer、TVOffer和BDDffer三个数据集进行合并,并去重,得到最终的销售品名称数据集TVOfferName。将TVOfferName数据集保存为名为TVOfferName的Hive表。针对宽带业务,根据一定的条件筛选出销售品,并获取最新的销售品名称,构建BDOfferordeResult数据集。
val TVOfferName = TVMainOffer.union(TVOffer).union(BDDffer).distinct()
TVOfferName.write.mode(“overwrite”).saveAsTable(“userPrint.TVOfferName”)
val BDOfferordeResult = BDorder.select(col(“phone_no”), col(“prodname”), row_number().over(Window.partitionBy(“phone_no”).orderBy(desc(“optdate”))) as “rn”)
.filter(“rn==1”)
.select(col(“phone_no”), col(“prodname”))
根据业务名称和入网程度添加标签
完整代码
package code.userprintimport org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
object UserMesgPrint {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val spark = SparkSession.builder().appName("Process").master("local[*]").enableHiveSupport().getOrCreate()//spark.sparkContext.setLogLevel("WARN")val userMsg = spark.table("processData.mediamatch_usermsg")// 业务品牌userMsg.filter("sm_code != 'a0' and sm_code != 'b1'").select("phone_no","sm_name").write.mode("overwrite").saveAsTable("userprint.ProductOffer")val TV = spark.read.table("processData.mediamatch_usermsg")// 筛选电视业务.filter("sm_name != '珠江宽频'")val BD = spark.read.table("processData.mediamatch_usermsg")// 筛选电视业务.filter("sm_name like '珠江宽频'").filter("sm_code == 'b0'").filter("force like '宽带生效'")// 用户电视入网val TVOpenTime = TV.select(col("phone_no"),col("open_time"),row_number().over(Window.partitionBy("phone_no").orderBy(desc("open_time") )) as "rn").filter("rn==1").select(col("phone_no"),col("open_time"))TVOpenTime.show()val TVtime = TVOpenTime.withColumn("T",months_between(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss"),col("open_time")))TVtime.show()// 用户电视入网标签构建val TVLabelUdf = udf((x:Double)=>TVLabel(x))TVtime.withColumn("TVLabel",TVLabelUdf(col("T"))).write.mode("overwrite").saveAsTable("userPrint.TVUseLabel")// 用户宽带入网val BDOpenTime = BD.select(col("phone_no"),col("open_time"),row_number().over(Window.partitionBy("phone_no").orderBy(desc("open_time") )) as "rn").filter("rn==1").select(col("phone_no"),col("open_time"))BDOpenTime.show()val BDtime = BDOpenTime.withColumn("T",months_between(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss"),col("open_time")))BDtime.show()// 用户宽带入网标签构建val BDLabelUdf = udf((x:Double)=>BDLabel(x))BDtime.withColumn("BDLabel",BDLabelUdf(col("T"))).write.mode("overwrite").saveAsTable("userPrint.BDUseLabel")}def TVLabel(T:Double): String = {if (T > 6) {"老用户"} else if (T < 3) {"新用户"} else {"中等用户"}}def BDLabel(T:Double): String ={if (T>4){"老用户"}else if(T<=2){"新用户"}else{"中等用户"}}
}
该类的目的是根据用户的电视业务和宽带业务数据,进行数据处理和分析,以实现以下核心目标:
(1)业务品牌处理:将用户的业务品牌数据进行筛选和处理,提取出符合条件的业务品牌信息,并保存到指定的表中。
(2)电视业务处理:
提取用户的电视业务数据。
计算每个用户的电视入网时间,并与当前时间进行比较,得出入网时长。
根据入网时长,对用户进行分类标记,划分为新用户、老用户和中等用户,并将结果保存到指定的表中。
(3)宽带业务处理:
提取用户的宽带业务数据。
计算每个用户的宽带入网时间,并与当前时间进行比较,得出入网时长。
根据入网时长,对用户进行分类标记,划分为新用户、老用户和中等用户,并将结果保存到指定的表中。
思路:
读取数据:使用spark.table()方法从表processData.mediamatch_usermsg中读取数据,并将其赋值给userMsg变量。
业务品牌处理:对userMsg进行条件筛选,去除sm_code为’a0’和’b1’的数据,然后选择phone_no和sm_name字段,将结果保存为名为ProductOffer的Hive表。
电视业务处理:
(1)数据筛选:对userMsg进行条件筛选,选择sm_name不等于’珠江宽频’的数据,并将结果赋值给TV变量。
(2)用户电视入网时间:使用窗口函数row_number()和desc(“open_time”)对TV进行分组排序,获取每个用户的最新入网时间,并将结果命名为TVOpenTime。
(3)计算入网时长:使用函数months_between()计算当前时间和入网时间之间的月份差,并将结果命名为T。
(4)用户电视入网标签构建:定义TVLabel函数,根据入网时长T的值判断用户的入网标签,返回相应的标签字符串。
(5)将入网时间和入网标签合并,并将结果保存为名为TVUseLabel的Hive表。
宽带业务处理:
(1)数据筛选:对userMsg进行条件筛选,选择sm_name为’珠江宽频’、sm_code为’b0’、force为’宽带生效’的数据,并将结果赋值给BD变量。
(2)用户宽带入网时间:使用窗口函数row_number()和desc(“open_time”)对BD进行分组排序,获取每个用户的最新入网时间,并将结果命名为BDOpenTime。
(3)计算入网时长:使用函数months_between()计算当前时间和入网时间之间的月份差,并将结果命名为T。
(4)用户宽带入网标签构建:定义BDLabel函数,根据入网时长T的值判断用户的入网标签,返回相应的标签字符串。
(5)将入网时间和入网标签合并,并将结果保存为名为BDUseLabel的Hive表。
核心代码:
从电视业务数据筛选和入网时间计算:
val TV = spark.read.table(“processData.mediamatch_usermsg”)
.filter(“sm_name != ‘珠江宽频’”)
val TVOpenTime = TV.select(col(“phone_no”), col(“open_time”),
row_number().over(Window.partitionBy(“phone_no”).orderBy(desc(“open_time”))) as “rn”)
.filter(“rn==1”)
.select(col(“phone_no”), col(“open_time”))
val TVtime = TVOpenTime.withColumn(“T”, months_between(from_unixtime(unix_timestamp(), “yyyy-MM-dd HH:mm:ss”), col(“open_time”)))
这段代码首先从输入数据中选择电视业务数据,并筛选出符合条件的数据。然后,通过窗口函数和排序操作,计算每个用户的最早入网时间,并提取出用户手机号和入网时间。最后,利用当前时间和入网时间计算出用户的入网时长。
电视业务用户标签构建和结果保存:
val TVLabelUdf = udf((x: Double) => TVLabel(x))
TVtime.withColumn(“TVLabel”, TVLabelUdf(col(“T”))).write.mode(“overwrite”).saveAsTable(“userPrint.TVUseLabel”)
这段代码定义了一个用户自定义函数 TVLabelUdf,用于根据入网时长对用户进行分类标记。然后,将入网时间和分类标记列添加到数据集中,并将结果保存到指定的表中。
宽带业务数据筛选和入网时间计算:
val BD = spark.read.table(“processData.mediamatch_usermsg”)
.filter(“sm_name like ‘珠江宽频’”)
.filter(“sm_code == ‘b0’”)
.filter(“force like ‘宽带生效’”)
val BDOpenTime = BD.select(col(“phone_no”), col(“open_time”),
row_number().over(Window.partitionBy(“phone_no”).orderBy(desc(“open_time”))) as “rn”)
.filter(“rn==1”)
.select(col(“phone_no”), col(“open_time”))
val BDtime = BDOpenTime.withColumn(“T”, months_between(from_unixtime(unix_timestamp(), “yyyy-MM-dd HH:mm:ss”), col(“open_time”)))
这段代码和第一段代码类似,只是针对宽带业务数据进行了筛选,并计算了每个用户的最早入网时间和入网时长。
宽带业务用户标签构建和结果保存:
val BDLabelUdf = udf((x: Double) => BDLabel(x))
BDtime.withColumn(“BDLabel”, BDLabelUdf(col(“T”))).write.mode(“overwrite”).saveAsTable(“userPrint.BDUseLabel”)
这段代码也类似于第二段代码,定义了一个用户自定义函数 BDLabelUdf,用于根据入网时长对宽带用户进行分类标记。然后,将入网时间和分类标记列添加到数据集中,并将结果保存到指定的表中。
以上是核心代码的简要介绍,分别展示了电视业务数据的处理和标记以及宽带业务数据的处理和标记。每段代码都有相应的文字介绍说明其功能和操作。
遇到的一些问题:
长时间运行不出结果:
运行OfferName程序时出现长时间不输出也不结束的阻塞情况.具体情况如下图所示:
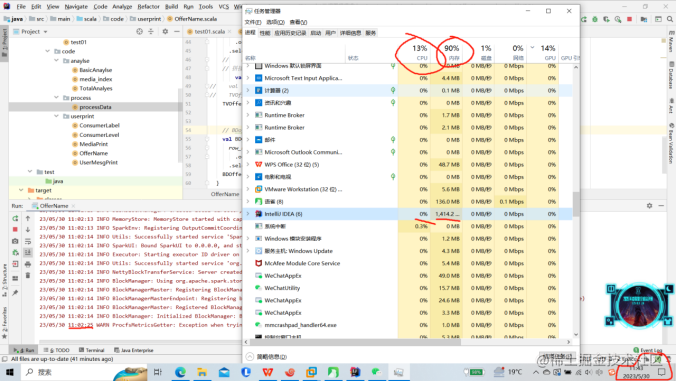
可能是Windows下内存不足,而在虚拟机里运行时因为虚拟机使用的是虚拟内存,相对Windows的内存空间更大,因此解决方式就是放在虚拟机中运行.
而手动中断后再次运行,会报错报错说此hive表已存在,但在命令行里去show tables;是找不到这个表的.虽然这表没有建立,但表的映射文件已经建立,此时是需要删除映射即可:
hdfs dfs -rm -r hdfs://node01:9000/hive/warehouse/userprint.db/tvoffername
回归原本的问题,解决方式为将程序打包放在虚拟机里运行.
打包流程如下图所示:
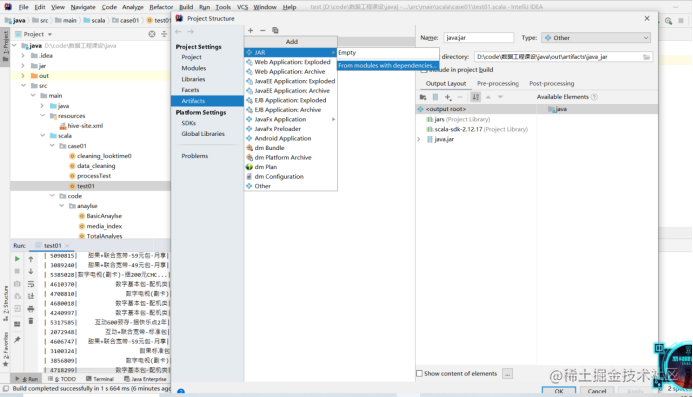
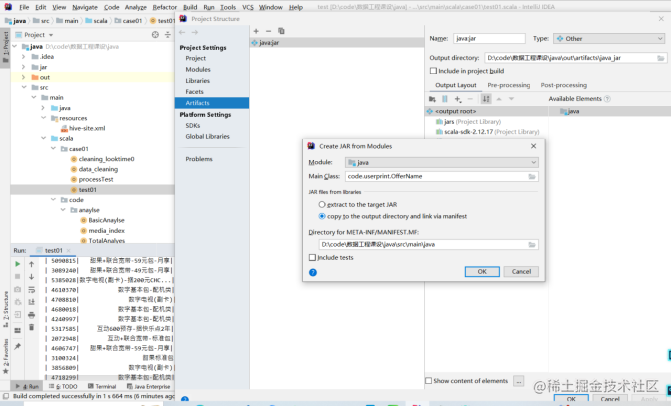
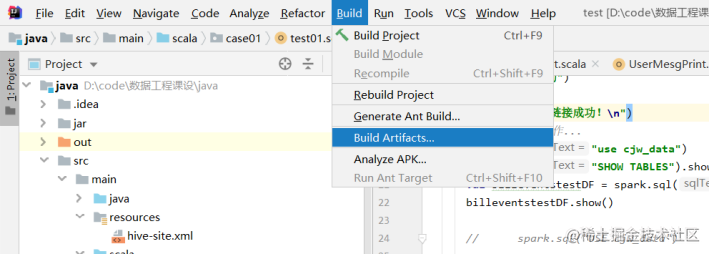
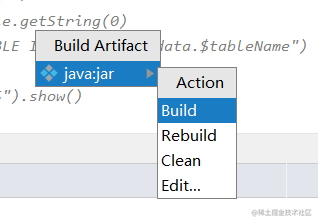
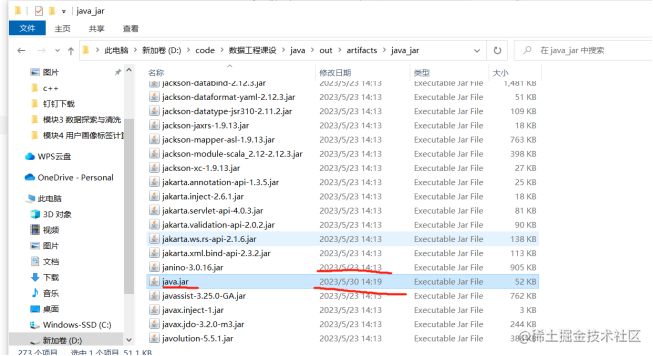
改名并上传到/opt然后运行.运行指令为:
spark-submit --master spark://master:7077 --class code.userprint.OfferName /opt/scala.jar
检查是否运行成功,查看表里是否生成了数据,成功结果如下图所示: