RDD(Resilient Distributed Datasets)可扩展的弹性分布式数据集,RDD是spark最基本的数据抽象,RDD表示一个只读、分区且不变的数据集合,是一种分布式的内存抽象,与分布式共享内存(Distributed Shared Memory,DSM)都是分布式的内存抽象,但两者是不同的。RDD支持两种类型的操作: transformations(转换)和 actions(动作)。transformations操作会在一个已存在的 RDD上创建一个新的 RDD,但实际的计算并没有执行,仅仅记录操作过程,所有的计算都发生在actions环节。actions操作触发时,会执行 RDD记录的所有运行transformations操作,并计算结果,结果可返回到 driver 程序,也可保存的相关存储系统中。
RDD基本操作
创建Rdd
parallelize列表创建
data=[1,2,6,4,7,3]
rdd=sc.parallelize(data)
rdd.collect()
textFile文本文件创建
distFile=sc.textFile("/home/ubuntu/Desktop/book.txt")
type(distFile)
1,apple
2,banana
3,banana
4,pear
5,orange
6,banana
7,orange
8,apple
9,apple
10,apple
11,pear
12,pear
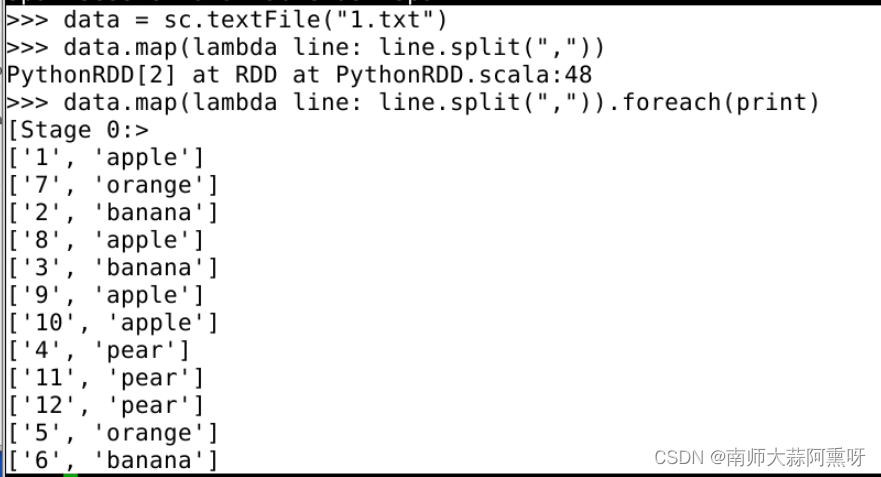
文本的创建后读取是一个怎么样的结果呢,首先如果读取的写法如上读入后,文本并没有划分为(k,v)值的,可以通过如下办法划分
distFile.map(lambda line: line.split(",")).foreach(print)
简单计算
count操作统计为列表输出
sc.parallelize([2,3,4]).count()
countByKey根据值排序
rdd=sc.parallelize([("a",1),("b",1),("a",1)])
sorted(rdd.countByKey().items())
countByValue返回唯一值的个数
sorted(sc.parallelize([1,2,1, 2, 2], 2).countByValue().items())
distinct去除重复值
sorted(sc.parallelize([1,1,2,3]).distinct().collect())
reduceByKey根据key把value加起来
from operator import add
rdd=sc.parallelize([("a", 1), ("b", 1), ("a",1)])
sorted(rdd.reduceByKey(add).collect())
复杂计算
filter筛选过滤操作,通常与lambda运用,下
rdd=sc.parallelize([1,2, 3, 4,5])
rdd.filter(lambda x:x%2== 0).collect()
flatMap,生成多元素输出,例如字典格式k,v
rdd=sc.parallelize([2,3, 4])
sorted(rdd.flatMap(lambda x:range(1,x)).collect())
自定义函数foreach
def f(k):print(k*2)return k*2
sc.parallelize([1,2, 3,4,5]).foreach(f)
自定义函数输出
.foreach(print)
groupBy根据自定义条件进行分组
以下结果简单解释以下,会按照是否能整除2分组,分成0,1,后面接着的是他的组员,其中sorted是对y组员进行排序的
rdd=sc.parallelize([1,1, 2, 3,5,8])
result= rdd.groupBy(lambda x:x% 2).collect()
sorted([(x,sorted(y)) for (x,y) in result])
map每个元素的单独定义
rdd=sc.parallelize(["b","a","c"])
sorted(rdd.map(lambda x: (x,1)).collect())
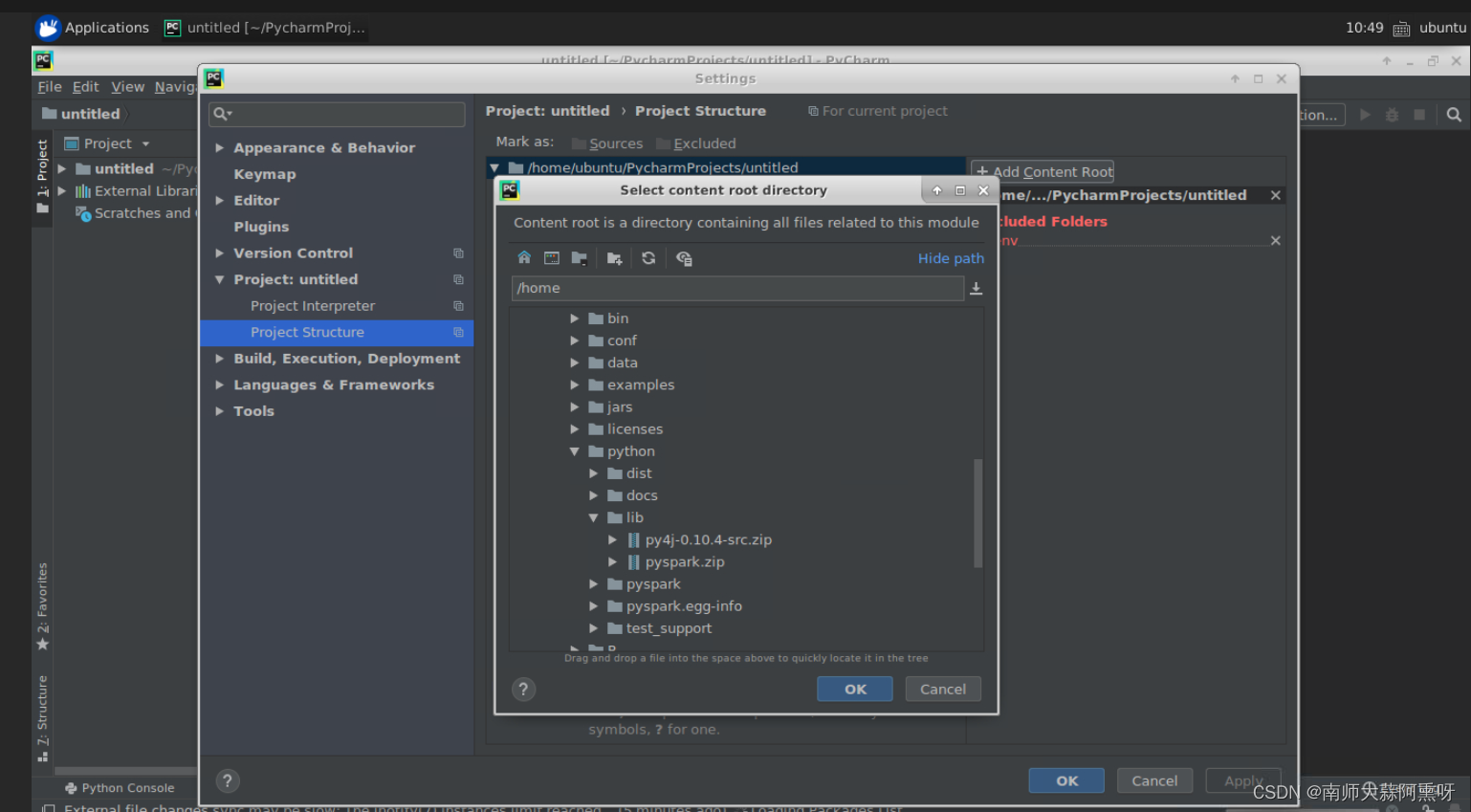
虚拟机环境配置(pycharm)
打开file–>setting–>projectstructure点击右边的add
目录在/opt/spark版本号/python/lib
里面有两个包一个个加入,一般这样就行了,不太需要去搞环境变量
spark dataframe
dataframe读取
df = spark.read.csv('1.csv',head=True,inferSchema=True)
df.show()
数据处理
filter groupBy sort
df.filter(df.conmae=='123').show()df.groupBy('coname').count().show()df.sort('coname').show()
转换为pandas dataframe
.toPandas()
其他的操作和pandas比较类似这里就不继续讲解了
RDD转换为dataframe,toDF
df = logs_rdd.toDF(["day","time", "path", "'method" ,"status"])
sql
registerTempTable 创建临时表,其中book_df是spark的Dataframe
book_df.registerTempTable("tb_book")
执行sql
spark.sql("select * from tb_book").show(15)
二、RDD计算
创建本地文件: “products.txt”.
id,name price,category
1,Apple,1.2,Fruit
2,Banana,0.5,Fruit
3,Carrot,8.6,Vegetable
4,Orange,1.3,Fruit
5,Cabbage ,1.0,Vegetable
1、基于pyspark库, 创建应用,加载数据为RDD.
2、过滤去除表头,保留剩下的记录。
3、计算每个水果category的平均价格。
4、显示结果。
三、SparkSQL-DataFrame (每小问5分,共20分)
数据:创建本地文件: “exam.txt”.
id,name,age,city,score
1,3ohn,25,New York,80
2,Alice,22,Los Angeles,90
3,Bob,24,Chicago,85
4,David,28,San Francisco,95
5,Eva,21,New York,92
- 使用pyspark读取文件, 并创建一个DataFrame.
- 统计每个城市的学员数量和平均分数。
- 筛选出平均分数大于85分的城市。
- 输出结果
# 导入必要的模块
from pyspark.sql import SparkSession# 创建 SparkSession
spark = SparkSession.builder.getOrCreate()# 1. 创建应用,加载数据为RDD
rdd = spark.sparkContext.textFile("products.txt")# 2. 过滤去除表头,保留剩下的记录
header = rdd.first()
filtered_rdd = rdd.filter(lambda row: row != header)# 3. 计算每个水果category的平均价格
fruit_rdd = filtered_rdd.filter(lambda row: row.split(",")[3].strip() == "Fruit")
fruit_prices_rdd = fruit_rdd.map(lambda row: float(row.split(",")[2]))
average_price = fruit_prices_rdd.mean()# 4. 显示结果
print("平均水果价格:", average_price)# 导入必要的模块
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, count# 创建 SparkSession
spark = SparkSession.builder.getOrCreate()# 1. 使用pyspark读取文件, 并创建一个DataFrame
df = spark.read.csv("exam.txt", header=True, inferSchema=True)# 2. 统计每个城市的学员数量和平均分数
city_stats = df.groupBy("city").agg(count("*").alias("student_count"), avg("score").alias("average_score"))# 3. 筛选出平均分数大于85分的城市
filtered_cities = city_stats.filter(city_stats.average_score > 85)# 4. 输出结果
filtered_cities.show()上各个字段,依次说明为:
1.IP地址:请求来源的IP地址
2.-: 标记符,表示客户端用户标识的缺失
3.-:标记符,表示客户端用户标识的缺失
4. [日期时间]:请求的时间和日期
5.“请求方法URL协议/版本":请求的方法、URL和协议版本
6.状态码:服务器响应的HTTP状态码
7.响应数据大小:服务器响应的流量大小,以字节为单位
要求:
1.创建一个本地文件夹,并监听该文件夹。
2使用窗口函数,设置窗口时长为10秒,滑动间隔为4秒。
3.对每个窗口内的数据进行统计:请求方法是GET的访问中,产生流量最多的IP是(使用sq|),
4.输出结果。
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
from pyspark.sql.functions import desc# 创建 SparkSession 和 StreamingContext
spark = SparkSession.builder.appName("StreamingLogAnalysis").getOrCreate()
sc = spark.sparkContext
streaming_context = StreamingContext(sc, 10) # 设置窗口时长为10秒# 创建一个本地文件夹,并监听该文件夹
log_folder = "/path/to/log/folder" # 替换为实际的日志文件夹路径
logs = streaming_context.textFileStream(log_folder)# 使用窗口函数,设置窗口时长为10秒,滑动间隔为4秒
windowed_logs = logs.window(10, 4)# 对每个窗口内的数据进行统计
def process_logs(window_rdd):if not window_rdd.isEmpty():# 解析日志数据parsed_logs = window_rdd.map(lambda log: log.split(" "))# 筛选请求方法为GET的访问get_requests = parsed_logs.filter(lambda log: log[5] == "GET")# 统计每个IP地址的流量大小ip_traffic = get_requests.map(lambda log: (log[0], int(log[6])))ip_traffic_stats = ip_traffic.reduceByKey(lambda a, b: a + b)# 找出产生流量最多的IP地址most_traffic_ip = ip_traffic_stats.max(lambda x: x[1])# 输出结果print("在该窗口中,产生流量最多的IP是:", most_traffic_ip[0])# 应用窗口函数和数据处理逻辑
windowed_logs.foreachRDD(process_logs)# 启动 StreamingContext
streaming_context.start()
streaming_context.awaitTermination()