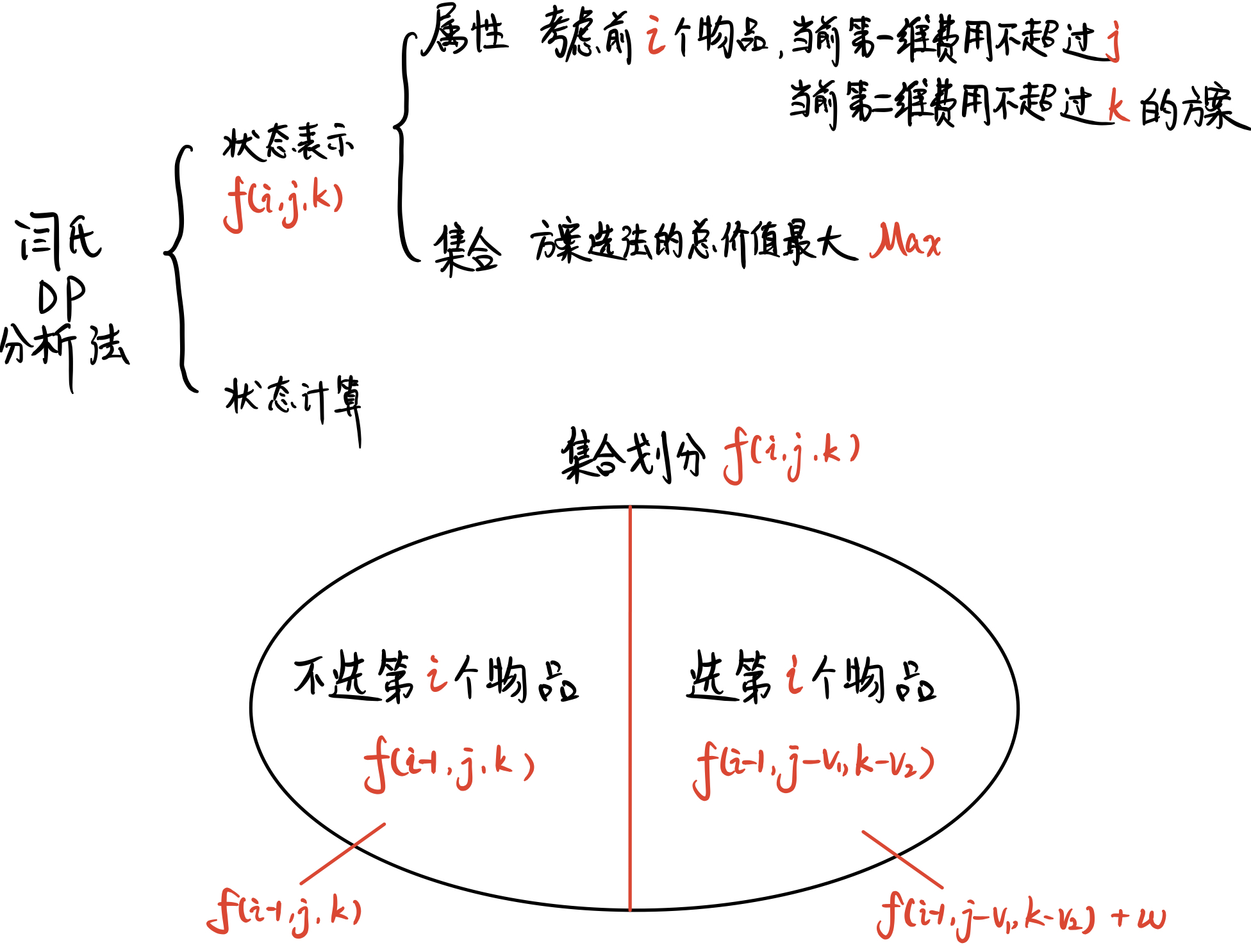
lxml 库是 C 库 libxml2 和 libxslt 的 Python 绑定, 可处理 XML 和 HTML 文档, 支持 XPath 语法
解析 HTML
分两种情况:
- 解析 HTMl 文件
当前目录新建 simple.html 文件
<html lang="en">
<head><title>XPath</title>
</head>
<body><h1>Web</h1><ul class="front"><li id="begin">HTML5</li><li>CSS3</li><li class="base js">JavaScript</li></ul><ul class="backend"><span>Go</span><li id="begin" class="base">Python</li></ul>
</body>
</html>
推荐使用 HTML 解析器(HTMLParser)而不是使用默认的解析器, 这样即便 HTML 文档不完整(例如只有开始标签而没有结束标签)也不会报错
>>> from lxml import etree>>> tree = etree.parse("./simple.html", etree.HTMLParser())
>>> type(tree)
<class 'lxml.etree._ElementTree'>>>> root = tree.getroot()
>>> type(root)
<class 'lxml.etree._Element'>
返回的 tree 是一个 ElementTree 对象, 可调用 getroot() 方法获取 HTML 的根元素对象
根元素以及使用 XPath 查找到的元素都是 Element 对象
- 解析 HTML 字符串
# 第一种方法
root = etree.fromstring("xxx", etree.HTMLParser())# 第二种方法
root = etree.HTML("xxx")
与 HTML 文件不同, 解析 HTML 字符串时, 直接返回根元素对象 root, 无论是 tree 还是 root, 均可调用 XPath 从根元素开始查找
获取元素详情
对于 Element 对象, 可以获取元素的以下内容:
- 标签名称
root.tag - 文本内容
root.text - 元素属性
root.attrib['xxx']或者root.get('xxx') - 直接子元素
root[0]
# 获取标签名称
>>> root.tag
'html'# 获取文本内容
>>> root.text
'\n\n'# 所有属性名称
>>> root.attrib.keys()
['lang']
# 获取元素属性
>>> root.get('lang')
'en'
>>> root.attrib['lang']
'en'# 子元素数量, html 有 head 和 body 两个子元素
>>> len(root)
2# 第一个直接子元素, 即 head 元素
>>> head = root[0]
>>> etree.tostring(head)
b'<head>\n <title>XPath</title>\n</head>\n'
使用 XPath 查找元素
调用 XPath
x.find()返回首个匹配的元素x.path()和x.findall()均返回一个列表, 其中包含所有匹配的元素
其中 x 为 ElementTree 对象或者 Element 对象
XPath 语法
路径
.表示当前元素,..表示上一级元素/仅匹配直接子元素,//递归匹配所有的子元素
<body><h1>Web</h1><ul class="front"><li id="begin">HTML5</li><li>CSS3</li><li class="base js">JavaScript</li></ul><ul class="backend"><span>Go</span><li id="begin" class="base">Python</li></ul>
</body>
- 获取 h1 元素
>>> from lxml import etree
>>> tree = etree.parse("./simple.html", etree.HTMLParser())# . 表示 html 元素, 可省略为 tree.xpath('body/h1')
>>> tree.xpath('./body/h1')
[<Element h1 at 0x7f098a28f740>]# 使用 findall() 方法, 与 xpath 一样返回匹配元素的列表
>>> tree.findall('body/h1')
[<Element h1 at 0x7f098a28f740>]# 使用 find() 方法, 返回第一个匹配到的元素
>>> tree.find('body/h1')
<Element h1 at 0x7f098a28f740>
- 使用
ElementTree对象调用 XPath, 从根元素开始解析路径 - 使用
Element对象调用 XPath 时, 从当前元素开始解析
Element 对象在调用 etree.parse() 时就生成了, 使用 XPath 查找同一个元素, 返回相同地址的 Element 对象
- 获取所有 ul 元素下的 li 直接子元素
# 使用 Element 对象调用 XPath
>>> root = tree.getroot()
>>> root.xpath("//ul/li")
[<Element li at 0x7f098a28f8c0>, <Element li at 0x7f098a28f900>, <Element li at 0x7f098a28f940>, <Element li at 0x7f098a28f980>]
根据地址的增量, 一个 Element 对象占用 64 字节的空间
谓语
置于方括号 [] 中, 用于修饰待查找的对象
- 属性相关
- 有无属性:
[@id]表示具有 id 属性的元素 - 属性匹配:
[@id='xxx']表示 id 属性为 xxx 的元素 - 属性包含:
[contains(@class, 'xxx')]表示 class 属性包含 xxx 的元素
- 有无属性:
- 下标:
[index]表示第几个子元素, 下标从 1 开始, 最后一个使用[last()]
- 匹配直接子元素, 包括 [tag] 和 [tag=‘text’]
[li]表示包含标签名为 li 直接子元素的元素[span='Go']表示包含标签名为 span 且文本内容为 Go 的直接子元素的元素
<body><h1>Web</h1><ul class="front"><li id="begin">HTML5</li><li>CSS3</li><li class="base js">JavaScript</li></ul><ul class="backend"><span>Go</span><li class="base">Python</li></ul>
</body>
- 存在 id 属性的 li 元素
>>> root.xpath('//li[@id]')
[<Element li at 0x7f098a28f940>]
- 元素 class 属性等于 base 的 li 元素
>>> root.xpath('//li[@class="base"]')
[<Element li at 0x7f098a28f7c0>]
JavaScript 所在 li 元素的 class 属性具有两个值, 视为不匹配
- 元素 class 属性包含 base 的 li 元素
>>> root.xpath('//li[contains(@class, "base")]')
[<Element li at 0x7f098a28f8c0>, <Element li at 0x7f098a28f7c0>]
- class 属性为 front 的 ul 元素的第二个 li 元素
# find() 和 findall() 方法中不能以 // 开头, 需要使用相对路径 .//
>>> li_list = root.findall('.//ul[@class="front"]/li[2]')
>>> li_list
[<Element li at 0x7f098a28fc00>]
>>> li_list[0].text
'CSS3'
- 包含 span 且文本内容为 Go 的直接子元素的 ul 元素
>>> ul = root.find('.//ul[span="Go"]')
>>> ul
<Element ul at 0x7f098a28f9c0>
>>> ul.get('class')
'backend'
获取文本
- 文本内容
text() - 属性内容
@attrib
<body><h1>Web</h1><ul class="front"><li id="begin">HTML5</li><li>CSS3</li><li class="base js">JavaScript</li></ul><ul class="backend"><span>Go</span><li class="base">Python</li></ul>
</body>
- 获取所有 ul 元素下 li 元素的文本内容
>>> tree.xpath("//ul/li/text()")
['HTML5', 'CSS3', 'JavaScript', 'Python']
- 获取所有 ul 元素的 class 属性值
>>> tree.xpath("//ul/@class")
['front', 'backend']
注意 find() 和 findall() 不支持文本节点的获取
通配符
*匹配所有子元素@*匹配所有属性
<body><h1>Web</h1><ul class="front"><li id="begin">HTML5</li><li>CSS3</li><li class="base js">JavaScript</li></ul><ul class="backend"><span>Go</span><li class="base">Python</li></ul>
</body>
- 获取所有 ul 元素下的直接子元素
>>> tree.findall("//ul/*")
[<Element li at 0x7f238d4c99c0>, <Element li at 0x7f238d4c9a00>, <Element li at 0x7f238d4c9a40>, <Element span at 0x7f238d4c9980>, <Element li at 0x7f238d4c9a80>]
结果中不仅包含 li 元素, 还有 span 元素
- 获取所有 ul 元素下直接子元素的文本内容
>>> tree.xpath("//ul/*/text()")
['HTML5', 'CSS3', 'JavaScript', 'Go', 'Python']
- 获取所有 li 元素的属性值
>>> tree.xpath("//li/@*")
['begin', 'base js', 'base']