一、理论部分
1、音色与音调的区别
-
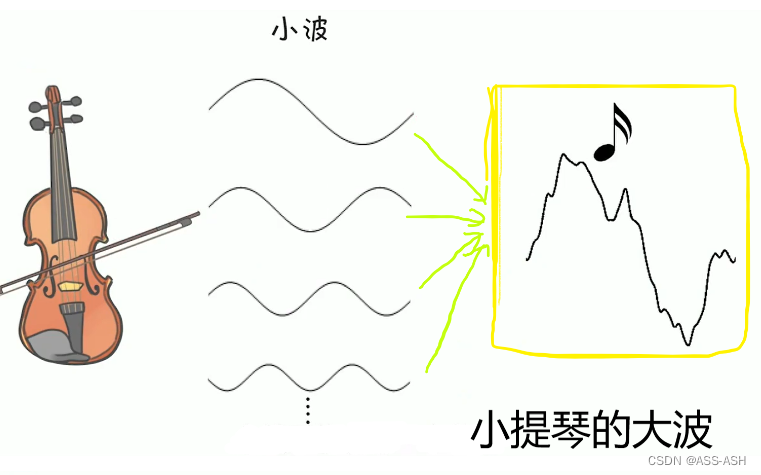
音调反映了声音大波的频率特征,而大波可以分解为不同频率的小波。不同乐器之间因为小波的叠加方式不同,导致大波的形状也不同,所以即使有相同的音调,他们的音色也不相同。
-
如下图反映了小提琴和小号之间大波的形状是不同的,同理,每个人也都有自己独立的音色。

2、梅尔倒谱是什么
- 我们的语音信号本质是振动信号,是一维信号。为了更好方便的分析信号特征,对其作频谱变换,就能得到梅尔倒谱。在 AU(audition) 中,如下图,上方是语音信号,下方就是梅尔倒谱。我们要转换的就是这个梅尔倒谱图(数据)。

3、语音合成TTS与语音转换VC的区别
-
现有的语音合成是 TTS 的技术,即 text to speech 文本到语音,输入一段文本,指定一个说话人就能生成一段语音对话。这个技术已经比较成熟,广泛用于AI自动配音。但是他有一个缺点就是配出来的音,可以听,但是非常机械没有感情,想要调整参数来改变又非常隐式——无法预知怎么改变参数才能得到想要的效果。
-
VC 则完全不同, VC 是一种 speech to speech 的技术。输入是一段 A 音色的语音,输出是一段用 B 音色的语音。在这个转换过程中,改变的只有音色而已,其他如情感、语速、语调、语音内容完全相同,这就是 VC。这个技术还在快速发展中,不仅转换一般的说话,也想转换唱歌时的音色,都在研究中。
-
VC实现方式有很多种,本项目使用 CycleGAN 来实现两个语者的音色互转。

4、GAN简易介绍
-
GAN 即 Generative Adversarial Networks ,生成对抗网络。原始的 GAN 想做的是,给定一个随机输入的向量,通过生成器转换之后,生成某种分布中的一个点。比如,生成手写数字。因为我们不知道该怎么定损失函数,仅有生成器的话。怎么定义一个损失函数,可以让生成器生成的越像数字,损失越小呢?很难显式的定义出来。
-
在图像填补的任务中,使用 L1 损失要比使用 GAN 得到图像更模糊。我们可以认为在 GAN 中,引入的判别器给生成器提供了一种全新的损失函数。在 GAN 训练的过程中,这个损失函数就可以用来区分生成器生成的属不属于目标分布的一个点。但是这个损失函数是不能够像 L1,L2,CrossEntropy 等损失函数一样显式的写出来。
-
既然是损失函数,那么判别器就能够指导生成器进行生成。在本项目中也是一样,判别器经过训练之后就会变得可以区分音色。
-
5、CycleGAN介绍
-
好了,我们现在可以用 GAN 来生成想要的语音了。假设我们有 A 的语音 dataset{A} 和 B 的语音 dataset{B} ,我们随机采样一个 A_0 用 A2B 模型来进行生成,虽然我们生成的 A_G_0 可以在音色上与 B 相同,但是我们却无法保证其内容与 A_0 保持一致。这不是我们想要的,应该仅仅改变音色,而其他所有都不改变才好!
-
有一个想法,如果我们将生成的 A_G_0 再输入 B2A 模型,将结果与 A_0 做 L1 损失。通过降低这个损失,就能够使 A_G_0 保存着 A_0 的语音内容信息。这就是 CycleGAN 的基本想法。
-
下图为 CycleGAN 斑马与马转换的结构示意图,我们这里只是音色而已,其他的没什么不同。

6、CycleGAN-VC2对比CycleGAN-VC的改进
一共三处改进:
-
在 CycleLoss 处 L1 损失基础上增加第二个鉴别器损失,来避免因为 L1 损失带来的平滑问题(统计模型自带的问题).

在VC框架(包括 CycleGAN VC )中,1DCNN(图(a))通常用作生成器,而在后滤波框架中,更优选 2DCNN(图(b))。这些选择与每个网络的优缺点有关。 1DCNN 更适合捕捉动态变化,因为它可以捕捉整体关系以及特征维度。相反,2DCNN 更适合在保持原始结构的同时转换特征,因为它将转换区域限制为局部区域。即使使用 1DCNN ,残余块也可以减轻原始结构的损失,但我们发现,下采样和上采样(这是有效捕获宽范围结构所必需的)成为这种退化的严重原因。为了缓解这种情况,我们开发了一种称为 2-1-2D CNN 的网络架构,如图(c)所示。在该网络中,2D 卷积用于下采样和上采样,1D 卷积用于主转换过程(即剩余块)。为了调整通道维度,我们在重塑特征映射之前或之后应用1×1卷积。
-
在VC框架(包括 CycleGAN VC )中,1DCNN(图(a))通常用作生成器,而在后滤波框架中,更优选 2DCNN(图(b))。这些选择与每个网络的优缺点有关。 1DCNN 更适合捕捉动态变化,因为它可以捕捉整体关系以及特征维度。相反,2DCNN 更适合在保持原始结构的同时转换特征,因为它将转换区域限制为局部区域。即使使用 1DCNN ,残余块也可以减轻原始结构的损失,但我们发现,下采样和上采样(这是有效捕获宽范围结构所必需的)成为这种退化的严重原因。为了缓解这种情况,我们开发了一种称为 2-1-2D CNN 的网络架构,如图(c)所示。在该网络中,2D 卷积用于下采样和上采样,1D 卷积用于主转换过程(即剩余块)。为了调整通道维度,我们在重塑特征映射之前或之后应用1×1卷积。
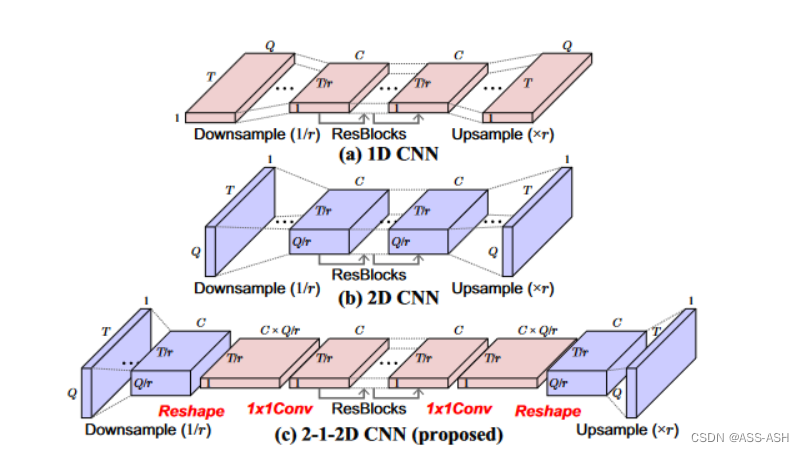
在以前基于 GAN 的语音处理模型中,FullGAN(图(a))已被广泛使用。然而,最近的计算机视觉研究表明,鉴别器的宽范围感受野需要更多的参数,这导致训练困难。受此启发,我们将 FullGAN 替换为 PatchGAN(图(b)),后者在最后一层使用卷积,并根据区域确定真实性。

7、构建自己的数据集注意事项
-
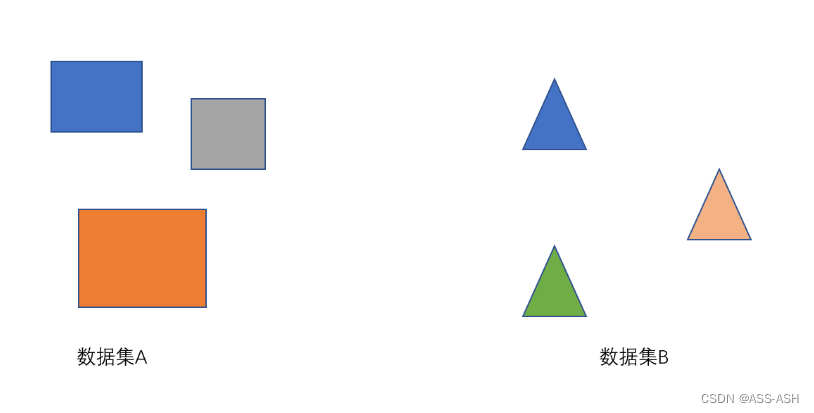
我们的数据集要保证分布之间只存在音色的差别,不能让判别器因为其他因素能将 A, B 的语音区分开来。如下两图,第一张图,两个数据集除了形状不一样,颜色分布应该要一致(即判别器学到区分这两者最好的方式是通过形状),这样我们就可以将 A 的形状转成 B 的形状而保留其颜色信息。因此,我们收集的语音要说的句子内容尽量丰富,单个语者的音色要统一(不要受到人物变声期,伪音等干扰)。而且要去背景音。
-
同理,中文转中文,日语转日语效果会更好,消除语言之间的差异。
-
每句话时长为3--8s,每个语者100句话。
第二张图,则能够改变颜色而保留形状

二、代码部分
1、安装包pyworld(python版本的声码器),导入包。对整体项目超参数文件路径进行配置。
-
"""安装pyworld""" # 语音合成和语音转换包,可以转换wav音频————>语音特征,和语音特征————>wav音频 # 语音特征包含以下三种,我们的神经网络就用来转换其中的【梅尔倒谱特征】 # 1、f0(基本频率,1维):表示语音基础的高度 # 2、Spectral-envelope(频谱)——>Mel-cepstrum(梅尔倒谱,多维):用来训练和转换的主要特征 # 3、Aperiodicity(非周期性)——>codeap(1维编码):显示声带振动或噪音混合的影响 !pip install pyworld"""项目所需要的所有包""" # 音频处理相关 import pyworld import soundfile as sf import librosa import wave_process as wp # 数据科学相关 import glob import numpy as np import os import paddle import paddle.nn as nn import paddle.nn.functional as F from paddle.io import Dataset, DataLoader from visualdl import LogWriter"""配置文件""" CONFIG = {# 数据存储路径'train_dir_A': 'voice_data/xiuyi', # wav格式,108条3-8s的说话语音(去背景音)'train_dir_B': 'voice_data/anshitou','catch_A': 'catch/train_A', # 进行统计特征抽取之后,真正输入网络训练的数据'catch_B': 'catch/train_B','n_frames': 128, # 截取128帧作为一段训练数据# 特征提取'fs': 32000, # 采样率'frame_period': 5.0, # 帧移'coded_dim': 64, # mepc 特征维度# 训练参数'g_lr': 2e-4, # 生成器学习率'd_lr': 2e-5, # 判别器学习率'train_steps': 2e4, # 训练迭代次数'step_drop_identity': 15000, # 15000轮迭代后舍弃identity loss'valid_A': 'valid/xiuyi', # 训练过程中验证数据路径A'valid_B': 'valid/anshitou', # 训练过程中验证数据路径B# loss权重'identity_loss_lambda': 10, # identity loss放大因子'cycle_loss_lambda': 5, # cycle loss放大因子# 模型保存'step_save': 2000, # 2000次迭代,保存一次模型'path_save': 'save', # 模型保存路径 }2、使用音频处理包对wav文件进行特征提取,并生成训练数据(mecps)。
-
"""提取说话人A的特征""" dir_train_A = CONFIG['train_dir_A'] wavs = glob.glob(dir_train_A + '/*wav') f0_mean, f0_std, mecp_mean, mecp_std, mecps = wp.processing_wavs(wavs, CONFIG)os.makedirs(CONFIG['catch_A'], exist_ok=True) np.save(os.path.join(CONFIG['catch_A'], 'static_f0.npy'), np.array([f0_mean, f0_std], dtype=object)) np.save(os.path.join(CONFIG['catch_A'], 'static_mecp.npy'), np.array([mecp_mean, mecp_std], dtype=object)) np.save(os.path.join(CONFIG['catch_A'], 'data.npy'), np.array(mecps, dtype=object)) # 用来训练"""提取说话人B的特征""" dir_train_B = CONFIG['train_dir_B'] wavs = glob.glob(dir_train_B + '/*wav') f0_mean, f0_std, mecp_mean, mecp_std, mecps = wp.processing_wavs(wavs, CONFIG)os.makedirs(CONFIG['catch_B'], exist_ok=True) np.save(os.path.join(CONFIG['catch_B'], 'static_f0.npy'), np.array([f0_mean, f0_std], dtype=object)) np.save(os.path.join(CONFIG['catch_B'], 'static_mecp.npy'), np.array([mecp_mean, mecp_std], dtype=object)) np.save(os.path.join(CONFIG['catch_B'], 'data.npy'), np.array(mecps, dtype=object)) # 用来训练3、定义CycleGAN-VC2网络训练的数据集
-
我们每次从语者A和语者B中随机取一条语音进行配对,作为训练神经网络的输入。
-
我们从每段语音中只随机截取【CONFIG['n_frame']】帧作为训练数据
-
"""每次从A说话人与B说话人之间随机抽一条语音进行配对,训练CycleGAN-VC2网络""" class VC_Dataset(Dataset):def __init__(self, param):self.path_A = param['catch_A']self.path_B = param['catch_B']self.n_frames = param['n_frames']# 加载数据self.train_A = np.load(os.path.join(self.path_A, 'data.npy'), allow_pickle=True).tolist()self.train_B = np.load(os.path.join(self.path_B, 'data.npy'), allow_pickle=True).tolist()self.n_samples = min(len(self.train_A), len(self.train_B))# 生成随机数据对self.gen_random_pair_index()def gen_random_pair_index(self):train_data_A_idx = np.arange(len(self.train_A))train_data_B_idx = np.arange(len(self.train_B))np.random.shuffle(train_data_A_idx)np.random.shuffle(train_data_B_idx)train_data_A_idx_subset = train_data_A_idx[:self.n_samples].tolist()train_data_B_idx_subset = train_data_B_idx[:self.n_samples].tolist()self.index_pairs = [(i,j) for i,j in zip(train_data_A_idx_subset,train_data_B_idx_subset)]del train_data_A_idx, train_data_B_idx, train_data_A_idx_subset, train_data_B_idx_subsetdef __len__(self):return len(self.index_pairs)def __getitem__(self, idx):# 读取 A 和 B 的数据data_A = self.train_A[self.index_pairs[idx][0]]data_B = self.train_B[self.index_pairs[idx][1]]# 从 A 和 B 中 随机截取 n_frames 帧start_A = np.random.randint(len(data_A) - self.n_frames + 1)sub_data_A = data_A[start_A:start_A + self.n_frames]start_B = np.random.randint(len(data_B) - self.n_frames + 1)sub_data_B = data_B[start_B:start_B + self.n_frames]del data_A, data_B, start_A, start_Breturn paddle.to_tensor(sub_data_A.T, dtype='float32'), paddle.to_tensor(sub_data_B.T, dtype='float32')"""验证数据集定义是否正确""" if __name__ == "__main__":m_Dataset = VC_Dataset(CONFIG)m_DataLoader = DataLoader(m_Dataset, batch_size=1, shuffle=True, num_workers=0)m_Dataset.gen_random_pair_index()for n_epoch in range(2):for i_batch, sample_batch in enumerate(m_DataLoader):train_A = sample_batch[0]train_B = sample_batch[1]print('======================')print('数据A形状', train_A.shape)print('数据B形状', train_B.shape)breakm_Dataset.gen_random_pair_index()print('======================')4、定义生成网络与区域判别网络模型
- 注意:生成器 A2B 和生成器 B2A 共用一个模型架构,但是彼此之间模型的参数是独立的。同理,鉴别器 D_A 和鉴别器 D_B 也是一样。
-
"""生成器网络与判别器网络搭建""" # GLU,门控线性单元Gated linear units,对输入信号进行注意力选择 class GLU(nn.Layer):def __init__(self):super(GLU, self).__init__()def forward(self, x, gated_x):return x * F.sigmoid(gated_x)# 残差连接层 class ResidualLayer(nn.Layer):def __init__(self, in_channels, mid_channels, kernel_size, stride, padding):super(ResidualLayer, self).__init__()self.conv1d_layer = nn.Sequential(nn.Conv1D(in_channels=in_channels, out_channels=mid_channels, kernel_size=kernel_size, stride=1, padding=padding),nn.InstanceNorm1D(num_features=mid_channels, ))self.conv_layer_gates = nn.Sequential(nn.Conv1D(in_channels=in_channels, out_channels=mid_channels, kernel_size=kernel_size, stride=1, padding=padding),nn.InstanceNorm1D(num_features=mid_channels, ))self.conv1d_out_layer = nn.Sequential(nn.Conv1D(in_channels=mid_channels, out_channels=in_channels, kernel_size=kernel_size, stride=1, padding=padding),nn.InstanceNorm1D(num_features=in_channels, ))self.glu_layer = GLU()def forward(self, x):h1_norm = self.conv1d_layer(x)h1_gates_norm = self.conv_layer_gates(x)# GLUh1_glu = self.glu_layer(h1_norm, h1_gates_norm) # in_channel-> mid_channelh2_norm = self.conv1d_out_layer(h1_glu) # mid_channel->in_channelreturn x + h2_norm# 生成器,下采样模块 class downSample_Generator(nn.Layer):def __init__(self, in_channels, out_channels, kernel_size, stride, padding):super(downSample_Generator, self).__init__()self.convLayer = nn.Sequential(nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),nn.InstanceNorm2D(num_features=out_channels, ))self.convLayer_gates = nn.Sequential(nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),nn.InstanceNorm2D(num_features=out_channels, ))self.glu_layer = GLU()def forward(self, x):# GLUreturn self.glu_layer(self.convLayer(x), self.convLayer_gates(x))# 生成器,上采样模块 class upSample_Generator(nn.Layer):def __init__(self, in_channels, out_channels, kernel_size, stride, padding):super(upSample_Generator, self).__init__()self.convLayer = nn.Sequential(nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),nn.PixelShuffle(upscale_factor=2),nn.InstanceNorm2D(num_features=out_channels // 4, ))self.convLayer_gate = nn.Sequential(nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),nn.PixelShuffle(upscale_factor=2),nn.InstanceNorm2D(num_features=out_channels // 4, ))self.glu_layer = GLU()def forward(self, x):return self.glu_layer(self.convLayer(x), self.convLayer_gate(x))# 生成器,或者称为转换器 class Generator(nn.Layer):def __init__(self):super(Generator, self).__init__()"""对于非残差块的模块,传入参数依次为:(in_channels, out_channels, kernel_size, stride, padding)对于残差块,传入参数依次为:(in_channels, mid_channels, kernel_size, stride, padding)"""# 第一层 2D 卷积self.conv1 = nn.Conv2D(1, 128, (5, 15), (1, 1), (2, 7))self.conv1_gates = nn.Conv2D(1, 128, (5, 15), 1, (2, 7))self.conv1_glu = GLU()# 2D 下采样 Layerself.downSample1 = downSample_Generator(128, 256, 5, 2, 2)self.downSample2 = downSample_Generator(256, 256, 5, 2, 2)# 2D -> 1D 转换self.conv2dto1dLayer = nn.Sequential(nn.Conv1D(256 * CONFIG['coded_dim'] // 4, 256, 1, 1, 0),nn.InstanceNorm1D(num_features=256,))# 残差连接Blocks18层self.res_blocks = nn.LayerList([ResidualLayer(256, 512, 3, 1, 1) for _ in range(13)])# 1D -> 2D Convself.conv1dto2dLayer = nn.Sequential(nn.Conv1D(256, 256 * CONFIG['coded_dim'] // 4, 1, 1, 0),nn.InstanceNorm1D(num_features=256 * CONFIG['coded_dim'] // 4,))# 上采样 Layerself.upSample1 = upSample_Generator(256, 1024, 5, 1, 2)self.upSample2 = upSample_Generator(256, 512, 5, 1, 2)self.lastConvLayer = nn.Conv2D(128, 1, (5, 15), (1, 1), (2, 7))def forward(self, input): # [B, D, T], batch_size, 梅尔倒谱维度,帧长度B, D, T = input.shapeinput = input.unsqueeze(1) # [B, 1, D, T]conv1 = self.conv1_glu(self.conv1(input), self.conv1_gates(input)) # [B, 128, D, T]# 下采样downsample1 = self.downSample1(conv1) # [B, 256, D/2, T/2]downsample2 = self.downSample2(downsample1) # [B, 256, D/4, T/4]# 2D -> 1Dreshape2dto1d = downsample2.reshape([downsample2.shape[0], 256 * D // 4, 1, -1]) # [B, 256*D/4, 1, T/4]reshape2dto1d = reshape2dto1d.squeeze(2) # [B, 256*D/4, T/4]conv2dto1d_layer = self.conv2dto1dLayer(reshape2dto1d) # [B, 256, T/4]# 残差连接for layer in self.res_blocks:conv2dto1d_layer = layer(conv2dto1d_layer)# 1D -> 2Dconv1dto2d_layer = self.conv1dto2dLayer(conv2dto1d_layer) # [B, 256*D/4, T/4]reshape1dto2d = conv1dto2d_layer.unsqueeze(2) # [B, 256*D/4, 1, T/4]reshape1dto2d = reshape1dto2d.reshape([reshape1dto2d.shape[0], 256, D // 4, -1]) # [B, 256, 256*D/4, T/4]# 上采样upsample_layer_1 = self.upSample1(reshape1dto2d) # [B, 1024, D/4, T/4]upsample_layer_2 = self.upSample2(upsample_layer_1) # [B, 512, D/2, T/2]output = self.lastConvLayer(upsample_layer_2) # [B, 1, D, T]output = output.squeeze(1) # [B, D, T]return output# 鉴别器,下采样部分 class downSample_Discriminator(nn.Layer):def __init__(self, in_channels, out_channels, kernel_size, stride, padding):super(downSample_Discriminator, self).__init__()self.convLayer = nn.Sequential(nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),nn.InstanceNorm2D(num_features=out_channels, ))self.convLayer_gate = nn.Sequential(nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),nn.InstanceNorm2D(num_features=out_channels, ))self.glu_layer = GLU()def forward(self, x):return self.glu_layer(self.convLayer(x), self.convLayer_gate(x))# 鉴别器 PatchGAN,区域判别网络,更容易训练 class Discriminator(nn.Layer):def __init__(self):super(Discriminator, self).__init__()"""对于非残差块的模块,传入参数依次为:(in_channels, out_channels, kernel_size, stride, padding)对于残差块,传入参数依次为:(in_channels, mid_channels, kernel_size, stride, padding)"""self.convLayer1 = nn.Conv2D(1, 128, (3, 3), (1, 1), (1, 1))self.convLayer1_gate = nn.Conv2D(1, 128, (3, 3), (1, 1), (1, 1))self.glu_convLayer1 = GLU()# 下采样self.downSample1 = downSample_Discriminator(128, 256, (3, 3), (2, 2), (1, 1))self.downSample2 = downSample_Discriminator(256, 512, (3, 3), (2, 2), (1, 1))self.downSample3 = downSample_Discriminator(512, 1024, (3, 3), (2, 2), (1, 1))self.downSample4 = downSample_Discriminator(1024, 1024, (1, 5), (1, 1), (0, 2))# 输出self.outputConvLayer = nn.Conv2D(1024, 1, (1, 3), (1, 1), (0, 1))def forward(self, input): # [B, D, T]input = input.unsqueeze(1) # [B, 1, D, T]# 注意力卷积conv_layer_1_in = self.convLayer1(input)conv_layer_1_gate = self.convLayer1_gate(input)conv_layer_1 = self.glu_convLayer1(conv_layer_1_in, conv_layer_1_gate) # [B, 128, D, T]# 下采样downsample1 = self.downSample1(conv_layer_1) # [B, 256, D/2, T/2]downsample2 = self.downSample2(downsample1) # [B, 512, D/4, T/4]downsample3 = self.downSample3(downsample2) # [B, 1024, 8, T/8]downsample4 = self.downSample4(downsample3) # [B, 1024, 8, T/8]# 输出output = self.outputConvLayer(downsample4) # [B, 1, 8, T/8]output = F.sigmoid(output)return output"""验证网络是否运行不报错""" if __name__ == "__main__":in_data = paddle.randn([1, 64, 128])m_G = Generator()out_data = m_G(in_data)assert in_data.shape == out_data.shapeprint('生成器输出数据形状:', out_data.shape)m_D = Discriminator()out_D = m_D(out_data)print('鉴别器输出数据形状:', out_D.shape)5、模型训练与验证
-
定义函数【wav_conversion】,不仅用于训练过程中对模型效果进行验证。也可以在训练完成后,调用该函数来转换自己想要转换的语音。
-
训练时关注 cycleLoss 和 identityLoss ,因为这两个越小表示效果越好。生成器损失和鉴别器损失处于反复波动的状态,不容易进行监视。
-
"""模型训练及训练过程监测"""# 语音转换! def wav_conversion(ori_wav_path, iters, model_path, CONFIG, mode='A2B', save_path=None):"""ori_wav_path: 原语音路径iters: 迭代次数model_path:模型参数路径CONFIG:配置文件save_path: 训练好模型直接调接口时可以用这个,自定义命名"""# 加载统计特征static_A = wp.load_static(CONFIG['catch_A'])static_B = wp.load_static(CONFIG['catch_B'])# 读取wav音频wav, _ = librosa.load(ori_wav_path, sr=CONFIG['fs'], mono=True)wav = wp.wav_normlize(wav)# 加载模型m_model = paddle.load(model_path)generator = Generator()if mode == 'A2B':generator.set_state_dict(m_model['model_genA2B_state_dict'])conv_wav = wp.VC_model(wav, generator, CONFIG, static_A, static_B)save_file = CONFIG['valid_A'] + '/' + str(iters)os.makedirs(save_file, exist_ok=True)target_save_path = save_file + '/' + ori_wav_path.split('/')[-1][:-4] + 'A2B' + '.wav' if not save_path else save_pathelif mode == 'B2A':generator.set_state_dict(m_model['model_genB2A_state_dict'])conv_wav = wp.VC_model(wav, generator, CONFIG, static_B, static_A)save_file = CONFIG['valid_B'] + '/' + str(iters)os.makedirs(save_file, exist_ok=True)target_save_path = save_file + '/' + ori_wav_path.split('/')[-1][:-4] + 'B2A' + '.wav' if not save_path else save_pathsf.write(target_save_path, conv_wav, CONFIG['fs'])# 写入visualDL writer1 = LogWriter(logdir="./log/generator_loss") writer2 = LogWriter(logdir="./log/identiyLoss_cycleLoss") writer3 = LogWriter(logdir="./log/d_loss")"""模型训练""" if __name__ == "__main__":try:# 模型实例化m_G_A2B = Generator()m_G_B2A = Generator()m_D_A = Discriminator()m_D_B = Discriminator()# 定义优化器g_lr = CONFIG['g_lr']d_lr = CONFIG['d_lr']g_params = list(m_G_A2B.parameters()) + list(m_G_B2A.parameters())d_params = list(m_D_A.parameters()) + list(m_D_B.parameters())G_optimizer = paddle.optimizer.Adam(learning_rate=g_lr, beta1=0.5, beta2=0.999, parameters=g_params, weight_decay=0.001)D_optimizer = paddle.optimizer.Adam(learning_rate=g_lr, beta1=0.5, beta2=0.999, parameters=d_params, weight_decay=0.001)# 定义数据集m_dataset = VC_Dataset(CONFIG)m_dataloader = DataLoader(m_dataset, batch_size=1, shuffle=True, num_workers=0)# 开始进行训练train_epoch = int(CONFIG['train_steps'] / len(m_dataset)) + 1print('数据集长度为', len(m_dataset))n_step = 0g_loss_store = []d_loss_store = []for epoch in range(train_epoch):# 打乱顺序m_dataset.gen_random_pair_index()for i, batch_samples in enumerate(m_dataloader):n_step = n_step + 1real_A = batch_samples[0]real_B = batch_samples[1]# 根据迭代轮次 修正 lambdaif n_step > CONFIG['step_drop_identity']:identity_loss_lambda = 0else:identity_loss_lambda = CONFIG['identity_loss_lambda']cycle_loss_lambda = CONFIG['cycle_loss_lambda']# 计算损失函数 G_lossfake_B = m_G_A2B(real_A)cycle_A = m_G_B2A(fake_B)fake_A = m_G_B2A(real_B)cycle_B = m_G_A2B(fake_A)identity_A = m_G_B2A(real_A)identity_B = m_G_A2B(real_B)d_fake_A = m_D_A(fake_A)d_fake_B = m_D_B(fake_B)# for the second step adverserial lossd_fake_cycle_A = m_D_A(cycle_A)d_fake_cycle_B = m_D_B(cycle_B)# Generator Cycle losscycleLoss = paddle.mean(paddle.abs(real_A - cycle_A)) \+ paddle.mean(paddle.abs(real_B - cycle_B))# Generator Identity LossidentiyLoss = paddle.mean(paddle.abs(real_A - identity_A)) \+ paddle.mean(paddle.abs(real_B - identity_B))# Generator Lossgenerator_loss_A2B = paddle.mean((1 - d_fake_B) ** 2)generator_loss_B2A = paddle.mean((1 - d_fake_A) ** 2)generator_loss_2nd = 0.5 * (paddle.mean((1 - d_fake_cycle_A) ** 2) + paddle.mean((1 - d_fake_cycle_B) ** 2))# Total Generator Lossg_loss = generator_loss_A2B + generator_loss_B2A + \cycle_loss_lambda * cycleLoss + \identity_loss_lambda * identiyLoss + \generator_loss_2ndif n_step % 50 == 0:g_loss_store.append(g_loss)# 梯度下降,更新G部分的参数G_optimizer.clear_grad()D_optimizer.clear_grad()g_loss.backward()G_optimizer.step()# 更新 D 部分的参数d_real_A = m_D_A(real_A)d_real_B = m_D_B(real_B)generated_A = m_G_B2A(real_B)d_fake_A = m_D_A(generated_A)# for the second step adverserial losscycled_B = m_G_A2B(generated_A)d_cycled_B = m_D_B(cycled_B)generated_B = m_G_A2B(real_A)d_fake_B = m_D_B(generated_B)# for the second step adverserial losscycled_A = m_G_B2A(generated_B)d_cycled_A = m_D_A(cycled_A)# Loss Functionsd_loss_A_real = paddle.mean((1 - d_real_A) ** 2)d_loss_A_fake = paddle.mean((0 - d_fake_A) ** 2)d_loss_A = (d_loss_A_real + d_loss_A_fake) / 2.0d_loss_B_real = paddle.mean((1 - d_real_B) ** 2)d_loss_B_fake = paddle.mean((0 - d_fake_B) ** 2)d_loss_B = (d_loss_B_real + d_loss_B_fake) / 2.0# the second step adverserial lossd_loss_A_cycled = paddle.mean((0 - d_cycled_A) ** 2)d_loss_B_cycled = paddle.mean((0 - d_cycled_B) ** 2)d_loss_A_2nd = (d_loss_A_real + d_loss_A_cycled) / 2.0d_loss_B_2nd = (d_loss_B_real + d_loss_B_cycled) / 2.0# Final Loss for discriminator with the second step adverserial lossd_loss = (d_loss_A + d_loss_B) / 2.0 + (d_loss_A_2nd + d_loss_B_2nd) / 2.0if n_step % 50 == 0:d_loss_store.append(d_loss)# 梯度下降 更新D部分的参数G_optimizer.clear_grad()D_optimizer.clear_grad()d_loss.backward()D_optimizer.step()del real_A, real_B, fake_A, fake_B, cycle_A, cycle_B, identity_A, identity_Bdel d_fake_A, d_fake_B, d_cycled_A, d_cycled_B, d_fake_cycle_A, d_fake_cycle_B# 模型保存if n_step % CONFIG['step_save'] == 0:print('保存模型{}'.format(n_step))path_save = os.path.join(CONFIG['path_save'], 'epoch' + str(n_step))os.makedirs(path_save, exist_ok=True)paddle.save({'generator_loss_store': g_loss_store,'discriminator_loss_store': d_loss_store,'model_genA2B_state_dict': m_G_A2B.state_dict(),'model_genB2A_state_dict': m_G_B2A.state_dict(),'model_discriminatorA': m_D_A.state_dict(),'model_discriminatorB': m_D_B.state_dict(),'generator_optimizer': G_optimizer.state_dict(),'discriminator_optimizer': D_optimizer.state_dict()}, os.path.join(path_save, 'model.pick'))# 监测模型训练的进程file_paths = os.listdir(CONFIG['valid_B'])for file_name in file_paths:if file_name.endswith('.wav'):path = CONFIG['valid_B'] + '/' + file_namewav_conversion(path, iters=n_step, model_path=os.path.join(path_save, 'model.pick'), CONFIG=CONFIG, mode='B2A')file_paths = os.listdir(CONFIG['valid_A'])for file_name in file_paths:if file_name.endswith('.wav'):path = CONFIG['valid_A'] + '/' + file_namewav_conversion(path, iters=n_step, model_path=os.path.join(path_save, 'model.pick'), CONFIG=CONFIG, mode='A2B')if n_step % 50 == 0:# log 打印print("step %04d g_loss_A2B= %f, g_loss_B2A=%f, id_Loss=%f, cycleLoss=%f, d_loss_A=%f, d_loss_B=%f"% (n_step, generator_loss_A2B, generator_loss_B2A, identiyLoss, cycleLoss, d_loss_A, d_loss_B))# 写入visualDLwriter1.add_scalar(tag="generator_loss_A2B", step=n_step, value=generator_loss_A2B)writer1.add_scalar(tag="generator_loss_B2A", step=n_step, value=generator_loss_B2A)writer2.add_scalar(tag="identiyLoss", step=n_step, value=identiyLoss)writer2.add_scalar(tag="cycleLoss", step=n_step, value=cycleLoss)writer3.add_scalar(tag="d_loss_A", step=n_step, value=d_loss_A)writer3.add_scalar(tag="d_loss_B", step=n_step, value=d_loss_B)except KeyboardInterrupt:print('打造属于你自己的变声器!')6、转换你的语音!
调用下面这个函数,参数说明如下:
ori_wav_path:————要转换的语音路径
iter:————————设置为0即可
model_path:————加载的模型路径,加载最后一个模型就ok
CONFIG:——————配置文件,不需要动
mode:———————ori_wav_path如果是A的语音就选A2B,反之就选B2A
save_path:—————转换后语音的保存路径,右击就能进行一个下载
print('转换中...')wav_conversion(ori_wav_path, iters=0, model_path, CONFIG=CONFIG, mode='A2B', save_path=None)print('转换完成!')