之前的文章末尾,简单的实现了springboot集成kafka,完成了简单的测试,今天我们来扩展一下相关内容。
首先详解一下配置文件的内容:
spring:kafka:# 指定 kafka 地址,我这里部署在的虚拟机,开发环境是Windows,kafkahost是虚拟机的地址, 若外网地址,注意修改为外网的IP( 集群部署需用逗号分隔)producer:bootstrap-servers: 124.223.205.125:9092# 发生错误后,消息重发的次数。retries: 3#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。batch-size: 16384# 设置生产者内存缓冲区的大小。buffer-memory: 33554432# 指定消息key和消息体的序列化方式key-deserializer: org.apache.kafka.common.serialization.StringSerializervalue-deserializer: org.apache.kafka.common.serialization.StringSerializeracks: allproperties:# 自定义生产者拦截器interceptor.classes: com.volga.kafka.interceptor.ProducerPrefixInterceptorconsumer:enable-auto-commit: false #手动提交bootstrap-servers: ${spring.kafka.producer.bootstrap-servers}# 指定 group_idgroup-id: group_id# Kafka中没有初始偏移或如果当前偏移在服务器上不再存在时,默认区最新 ,有三个选项 【latest, earliest, none】auto-offset-reset: earliest# 指定消息key和消息体的序列化方式key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerproperties:# 自定义消费者拦截器interceptor.classes: com.volga.kafka.interceptor.ConsumerPrefixInterceptor# 默认主题topic: my-topiclistener:# 在侦听器容器中运行的线程数。concurrency: 5#listner负责ack,每调用一次,就立即commitack-mode: manual_immediatemissing-topics-fatal: falsetype: batch
以上的producer和consumer的相关配置也可以在java文件中实现:
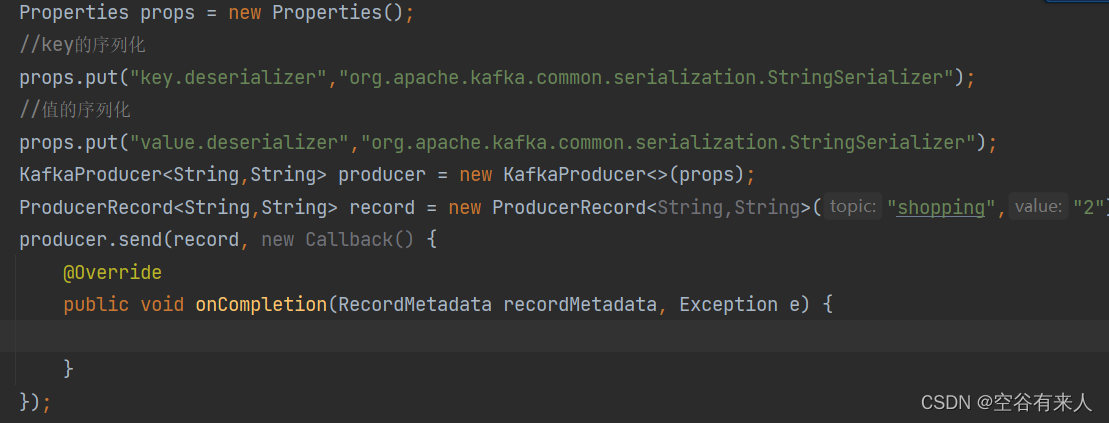
如上图的实现,自己可以手动实现一下。
kafka内部自己实现分区、策略等一系列的逻辑,当然这些也可以自定义,这里有需要的可以自己研究一下,我这里就不需要了。
接下来,我介绍一个场景,是大家在实际的项目中可以用到。有这样一个场景,在项目中,我们搭建了kafka集群,然而在环境中,会有各种不同的消息,有一些消息不是我们需要的,有些消息是我们需要的,这时我们可以通过过滤器来进行控制和过滤。
在生产者端,我添加一个过滤器在消息前统一加上一个前缀。
@Slf4j
public class ProducerPrefixInterceptor implements ProducerInterceptor<String,String> {AtomicInteger success = new AtomicInteger(0);AtomicInteger fail = new AtomicInteger(0);@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) {// 消息统一添加前缀String modifyValue = "prefix-"+producerRecord.value();return new ProducerRecord<>(producerRecord.topic(), producerRecord.partition(), producerRecord.timestamp(), producerRecord.key(), modifyValue, producerRecord.headers());}@Overridepublic void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {if (Objects.nonNull(recordMetadata)){success.incrementAndGet();}else {fail.incrementAndGet();}}@Overridepublic void close() {log.info("success:%d\nfail:%d\n",success.get(),fail.get());success.set(0);fail.set(0);}@Overridepublic void configure(Map<String, ?> map) {}
}然后在消费者消费时,我遇到prefix前缀的消息时,就统一过滤掉,这不是我所需要的消息。
@Slf4j
public class ConsumerPrefixInterceptor implements ConsumerInterceptor<String,String> {/*** 过滤掉test开头的数据* @param consumerRecords* @return*/@Overridepublic ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> consumerRecords) {List<ConsumerRecord<String, String>> filterRecords = new ArrayList<>();Map<TopicPartition, List<ConsumerRecord<String, String>>> newRecords= new HashMap<>();Set<TopicPartition> partitions = consumerRecords.partitions();for(TopicPartition tp : partitions){List<ConsumerRecord<String, String>> records = consumerRecords.records(tp);for(ConsumerRecord<String, String> record: records){if(!record.value().startsWith("prefix")) {filterRecords.add(record);}}if(filterRecords.size() > 0){newRecords.put(tp, filterRecords);}}return new ConsumerRecords<>(newRecords);}@Overridepublic void onCommit(Map<TopicPartition, OffsetAndMetadata> map) {map.forEach((k,v) -> log.info("tp:%s--offset:%s\n",k,v));}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> map) {}
}相关的配置在上述的配置文件中也已经列出了,也可以在代码中加以配置。
props.put("properties.interceptor.classes","com.volga.kafka.interceptor.ProducerPrefixInterceptor");这样就能实现过滤不需要的消息了。
翻看源码中,生产端主要是KafkaProducer<k,v>这个类中KafkaProducer方法:
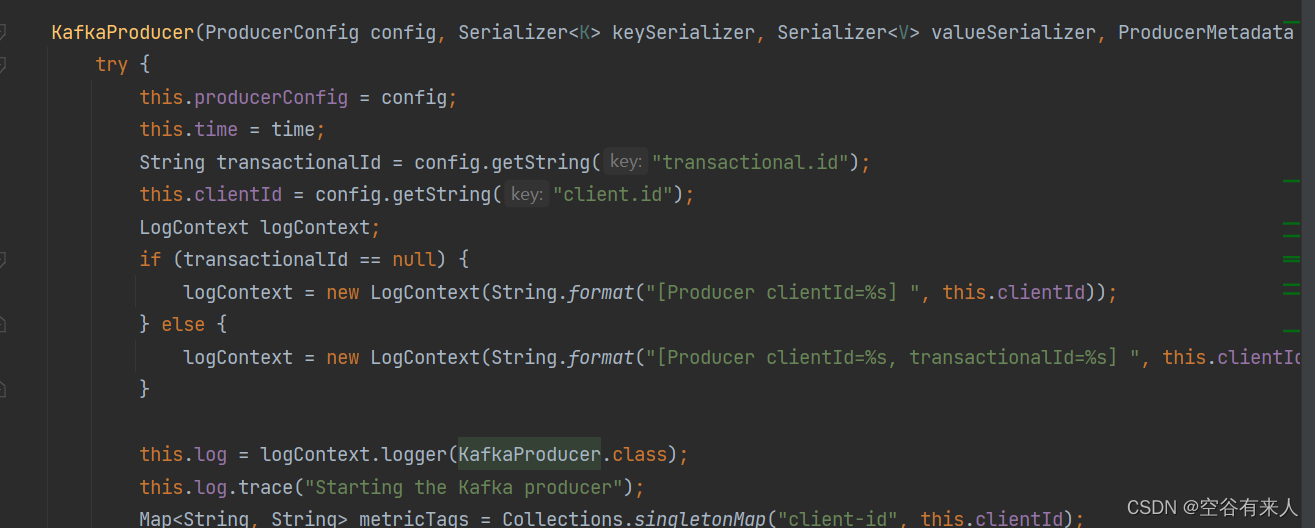
消费端这边是对应的:KafkaConsumer<k,v>,这个类中KafkaConsumer方法:

源码里kafka实现的配置逻辑大家可以仔细研究一下。
我是空谷有来人,谢谢支持!