1.Python中的模块
在Python中有一个概念叫做模块(module)。
说的通俗点:模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块
比如我们经常使用工具 random,就是一个模块。使用 import random 导入工具之后,就可以使用 random 的函数。
导入模块有五种方式
-
import 模块名
-
from 模块名 import 功能名
-
from 模块名 import *
-
import 模块名 as 别名
-
from 模块名 import 功能名 as 别名
下面来挨个的看一下。
1.1 import
在Python中用关键字import来引入某个模块,比如要引入系统模块 math,就可以在文件最开始的地方用import math来引入。
语法:
import 模块1,模块2,... # 导入方式模块名.函数名() # 使用模块里的函数-
想一想:
为什么必须加上模块名调用呢?
-
答:
因为可能存在这样一种情况:在多个模块中含有相同名称的函数,此时如果只是通过函数名来调用,解释器无法知道到底要调用哪个函数。所以如果像上述这样引入模块的时候,调用函数必须加上模块名
示例:
import math#这样才能正确输出结果
print math.sqrt(2)#这样会报错
print(sqrt(2))1.2 from...import
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以用下面方法实现:
from 模块名 import 函数名1,函数名2....不仅可以引入函数,还可以引入一些全局变量、类等
-
注意:
通过这种方式引入的时候,调用函数时只能给出函数名,不能给出模块名,但是当两个模块中含有相同名称函数的时候,后面一次引入会覆盖前一次引入。也就是说假如模块A中有函数function( ),在模块B中也有函数function( ),如果引入A中的function在先、B中的function在后,那么当调用function函数的时候,是去执行模块B中的function函数。
例如,要导入模块fib的fibonacci函数,使用如下语句:
from fib import fibonacci注意:
-
不会把整个fib模块导入到当前的命名空间中,它只会将fib里的fibonacci单个函数引入
1.3 from...import *
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *注意:
-
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
1.4 as别名
In [1]: import time as tt # 导入模块时设置别名为 ttIn [2]: time.sleep(1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-2-07a34f5b1e42> in <module>()
----> 1 time.sleep(1)NameError: name 'time' is not definedIn [3]: In [3]: tt.sleep(1) # 使用别名才能调用方法In [4]: In [4]: from time import sleep as sp # 导入方法时设置别名In [5]: sleep(1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-5-82e5c2913b44> in <module>()
----> 1 sleep(1)NameError: name 'sleep' is not definedIn [6]: In [6]: sp(1) # 使用别名才能调用方法In [7]:
2.常见的系统模块和使用
为了方便程序员开发代码,Python提供了很多内置的模块给程序员用来提高编码效率。常见的内置模块有:
-
os模块
-
sys模块
-
math模块
-
random模块
-
datetime模块
-
time模块
-
calendar模块
-
hashlib模块
-
hmac模块
-
copy模块
-
uuid模块
2.1 OS模块
OS全称OperationSystem,即操作系统模块,这个模块可以用来操作系统的功能,并且实现跨平台操作。
import os
os.getcwd() # 获取当前的工作目录,即当前python脚本工作的目录
os.chdir('test') # 改变当前脚本工作目录,相当于shell下的cd命令
os.rename('毕业论文.txt','毕业论文-最终版.txt') # 文件重命名
os.remove('毕业论文.txt') # 删除文件
os.rmdir('demo') # 删除空文件夹
os.removedirs('demo') # 删除空文件夹
os.mkdir('demo') # 创建一个文件夹
os.chdir('C:\\') # 切换工作目录
os.listdir('C:\\') # 列出指定目录里的所有文件和文件夹
os.name # nt->widonws posix->Linux/Unix或者MacOS
os.environ # 获取到环境配置
os.environ.get('PATH') # 获取指定的环境配置os.path.abspath(path) # 获取Path规范会的绝对路径
os.path.exists(path) # 如果Path存在,则返回True
os.path.isdir(path) # 如果path是一个存在的目录,返回True。否则返回False
os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False
os.path.splitext(path) # 用来将指定路径进行分隔,可以获取到文件的后缀名2.2 sys模块
该模块提供对解释器使用或维护的一些变量的访问,以及与解释器强烈交互的函数。
import sys
sys.path # 模块的查找路径
sys.argv # 传递给Python脚本的命令行参数列表
sys.exit(code) # 让程序以指定的退出码结束sys.stdin # 标准输入。可以通过它来获取用户的输入
sys.stdout # 标准输出。可以通过修改它来百变默认输出
sys.stderr # 错误输出。可以通过修改它来改变错误删除2.3 math模块
math模块保存了数学计算相关的方法,可以很方便的实现数学运算。
import math
print(math.fabs(-100)) # 取绝对值
print(math.ceil(34.01)) #向上取整
print(math.factorial(5)) # 计算阶乘
print(math.floor(34.98)) # 向下取整
print(math.pi) # π的值,约等于 3.141592653589793
print(math.pow(2, 10)) # 2的10次方
print(math.sin(math.pi / 6)) # 正弦值
print(math.cos(math.pi / 3)) # 余弦值
print(math.tan(math.pi / 2)) # 正切值2.4 random模块
random 模块主要用于生成随机数或者从一个列表里随机获取数据。
print(random.random()) # 生成 [0,1)的随机浮点数
print(random.uniform(20, 30)) # 生成[20,30]的随机浮点数
print(random.randint(10, 30)) # 生成[10,30]的随机整数
print(random.randrange(20, 30)) # 生成[20,30)的随机整数
print(random.choice('abcdefg')) # 从列表里随机取出一个元素
print(random.sample('abcdefghij', 3)) # 从列表里随机取出指定个数的元素练习:
定义一个函数,用来生成由数字和字母组成的随机验证码。该函数需要一个参数,参数用来指定验证码的长度。
2.5 datetime模块
datetime模块主要用来显示日期时间,这里主要涉及 date类,用来显示日期;time类,用来显示时间;dateteime类,用来显示日期时间;timedelta类用来计算时间。
import datetime
print(datetime.date(2020, 1, 1)) # 创建一个日期
print(datetime.time(18, 23, 45)) # 创建一个时间
print(datetime.datetime.now()) # 获取当前的日期时间
print(datetime.datetime.now() + datetime.timedelta(3)) # 计算三天以后的日期时间2.6 time模块
除了使用datetime模块里的time类以外,Python还单独提供了另一个time模块,用来操作时间。time模块不仅可以用来显示时间,还可以控制程序,让程序暂停(使用sleep函数)
print(time.time()) # 获取从1970-01-01 00:00:00 UTC 到现在时间的秒数
print(time.strftime("%Y-%m-%d %H:%M:%S")) # 按照指定格式输出时间
print(time.asctime()) #Mon Apr 15 20:03:23 2019
print(time.ctime()) # Mon Apr 15 20:03:23 2019print('hello')
print(time.sleep(10)) # 让线程暂停10秒钟
print('world')2.7 calendar模块
calendar模块用来显示一个日历,使用的不多,了解即可。
calendar.setfirstweekday(calendar.SUNDAY) # 设置每周起始日期码。周一到周日分别对应 0 ~ 6
calendar.firstweekday()# 返回当前每周起始日期的设置。默认情况下,首次载入calendar模块时返回0,即星期一。
c = calendar.calendar(2019) # 生成2019年的日历,并且以周日为其实日期码
print(c) #打印2019年日历
print(calendar.isleap(2000)) # True.闰年返回True,否则返回False
count = calendar.leapdays(1996,2010) # 获取1996年到2010年一共有多少个闰年
print(calendar.month(2019, 3)) # 打印2019年3月的日历2.8 hashlib模块
hashlib是一个提供字符加密功能的模块,包含MD5和SHA的加密算法,具体支持md5,sha1, sha224, sha256, sha384, sha512等算法。 该模块在用户登录认证方面应用广泛,对文本加密也很常见。
import hashlib# 待加密信息
str = '这是一个测试'# 创建md5对象
hl = hashlib.md5('hello'.encode(encoding='utf8'))
print('MD5加密后为 :' + hl.hexdigest())h1 = hashlib.sha1('123456'.encode())
print(h1.hexdigest())
h2 = hashlib.sha224('123456'.encode())
print(h2.hexdigest())
h3 = hashlib.sha256('123456'.encode())
print(h3.hexdigest())
h4 = hashlib.sha384('123456'.encode())
print(h4.hexdigest())2.9 hmac模块
HMAC算法也是一种一种单项加密算法,并且它是基于上面各种哈希算法/散列算法的,只是它可以在运算过程中使用一个密钥来增增强安全性。hmac模块实现了HAMC算法,提供了相应的函数和方法,且与hashlib提供的api基本一致。
h = hmac.new('h'.encode(),'你好'.encode())
result = h.hexdigest()
print(result) # 获取加密后的结果2.10 copy模块
copy模块里有copy和deepcopy两个函数,分别用来对数据进行深复制和浅复制。
import copynums = [1, 5, 3, 8, [100, 200, 300, 400], 6, 7]
nums1 = copy.copy(nums) # 对nums列表进行浅复制
nums2 = copy.deepcopy(nums) # 对nums列表进行深复制2.11 uuid模块
UUID是128位的全局唯一标识符,通常由32字节的字母串表示,它可以保证时间和空间的唯一性,也称为GUID。通过MAC地址、时间戳、命名空间、随机数、伪随机数来保证生产的ID的唯一性。随机生成字符串,可以当成token使用,当成用户账号使用,当成订单号使用。
| 方法 | 作用 |
|---|---|
| uuid.uuid1() | 基于MAC地址,时间戳,随机数来生成唯一的uuid,可以保证全球范围内的唯一性。 |
| uuid.uuid2() | 算法与uuid1相同,不同的是把时间戳的前4位置换为POSIX的UID。不过需要注意的是python中没有基于DCE的算法,所以python的uuid模块中没有uuid2这个方法。 |
| uuid.uuid3(namespace,name) | 通过计算一个命名空间和名字的md5散列值来给出一个uuid,所以可以保证命名空间中的不同名字具有不同的uuid,但是相同的名字就是相同的uuid了。namespace并不是一个自己手动指定的字符串或其他量,而是在uuid模块中本身给出的一些值。比如uuid.NAMESPACE_DNS,uuid.NAMESPACE_OID,uuid.NAMESPACE_OID这些值。这些值本身也是UUID对象,根据一定的规则计算得出。 |
| uuid.uuid4() | 通过伪随机数得到uuid,是有一定概率重复的 |
| uuid.uuid5(namespace,name) | 和uuid3基本相同,只不过采用的散列算法是sha1 |
一般而言,在对uuid的需求不是很复杂的时候,uuid1或者uuid4方法就已经够用了,使用方法如下:
import uuidprint(uuid.uuid1()) # 根据时间戳和机器码生成uuid,可以保证全球唯一
print(uuid.uuid4()) # 随机生成uuid,可能会有重复# 使用命名空间和字符串生成uuid.
# 注意一下两点:
# 1. 命名空间不是随意输入的字符串,它也是一个uuid类型的数据
# 2. 相同的命名空间和想到的字符串,生成的uuid是一样的
print(uuid.uuid3(uuid.NAMESPACE_DNS, 'hello'))
print(uuid.uuid5(uuid.NAMESPACE_OID, 'hello'))3.pip命令的使用
在安装Python时,同时还会安装pip软件,它是Python的包管理工具,可以用来查找、下载、安装和卸载Python的第三方资源包。
可以直接在终端中输入pip命令,如果出错,可能会有两个原因:
-
pip安装成功以后没有正确配置
-
安装Python时,没有自动安装pip(很少见)
4.管理第三方软件
对第三方包的管理主要包含查找、安装和卸载三个部分的操作。
4.1 安装
使用 pip install <包名>命令可以安装指定的第三方资源包。
pip install ipython # 安装ipython包使用 install 命令下载第三方资源包时,默认是从 pythonhosted下载,由于各种原因,在国内下载速度相对来说比较慢,在某些时候甚至会出现连接超时的情况,我们可以使用国内镜像来提高下载速度。
4.2 临时修改
如果只是想临时修改某个第三方资源包的下载地址,在第三方包名后面添加 -i 参数,再指定下载路径即可,格式为pip install <包名> -i <国内镜像路径>
pip install ipython -i https://pypi.douban.com/simple4.3 永久修改
除了临时修改pip的下载源以外,我们还能永久改变pip的默认下载路径。
在当前用户目录下创建一个pip的文件夹,然后再在文件夹里创建pip.ini文件并输入一下内容:
[global]
index-url=https://pypi.douban.com/simple
[install]
trusted-host=pypi.douban.com常见国内镜像
-
阿里云 https://mirrors.aliyun.com/pypi/simple/
-
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
-
豆瓣(douban) https://pypi.douban.com/simple/
-
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
-
中国科学技术大学 https://pypi.mirrors.ustc.edu.cn/simple/
4.4 卸载
使用 pip install <包名>命令可以用来卸载指定的第三方资源包。
pip uninstall ipython # 卸载ipython包4.5 查找
使用pip list 或者 pip freeze命令可以来管理第三方资源包。这两个命令的功能一致,都是用来显示当前环境里已经安装的包,区别在于pip list会列出所有的包,包括一些无法uninstall的包;而pip freeze只会列出我们安装的第三方包。
5.自定义模块
除了使用系统提供的内置模块以外,我们还能自己写一个模块供自己的程序使用。一个py文件就是一个模块,所以,自定义模块很简单,基本上相当于创建一个py文件。但是,需要注意的是,如果一个py文件要作为一个模块被别的代码使用,这个py文件的名字一定要遵守标识符的命名规则。
5.1 模块的查找路径
创建一个模块非常简单,安装标识符的命名规则创建一个py文件就是一个模块。但是问题是,我们需要把创建好的这个py文件放在哪个位置,在代码中使用 import语句才能找到这个模块呢?
Python内置sys模块的path属性,列出了程序运行时查找模块的目录,只需要把我们创建好的模块放到这些任意的一个目录里即可。
import sys
print(sys.path)
['C:\\Users\\chris\\Desktop\\Test','C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37\\python37.zip','C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37\\DLLs','C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37\\lib','C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37','C:\\Users\\chris\\AppData\\Roaming\\Python\\Python37\\site-packages','C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages'
]5.2 __all__的使用
使用from <模块名> import *导入一个模块里所有的内容时,本质上是去查找这个模块的__all__属性,将__all__属性里声明的所有内容导入。如果这个模块里没有设置__all__属性,此时才会导入这个模块里的所有内容。
5.2.1 模块里的私有成员
模块里以一个下划线_开始的变量和函数,是模块里的私有成员,当模块被导入时,以_开头的变量默认不会被导入。但是它不具有强制性,如果一个代码强行使用以_开头的变量,有时也可以。但是强烈不建议这样使用,因为有可能会出问题。
test1.py:模块里没有__all__属性
a = 'hello'
def fn():print('我是test1模块里的fn函数')test2.py:模块里有__all__属性
x = '你好'
y = 'good'
def foo():print('我是test2模块里的foo函数')
__all__ = ('x','foo')test3.py:模块里有以_开头的属性
m = '早上好'
_n = '下午好'
def _bar():print('我是test3里的bar函数')demo.py
from test1 import *
from test2 import *
from test3 import *print(a)
fn()print(x)
# print(y) 会报错,test2的__all__里没有变量 y
foo()print(m)
# print(_n) 会报错,导入test3时, _n 不会被导入import test3
print(test3._n) # 也可以强行使用,但是强烈不建议5.3__name__的使用
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:
test1.py
def add(a,b):return a+b# 这段代码应该只有直接运行这个文件进行测试时才要执行
# 如果别的代码导入本模块,这段代码不应该被执行
ret = add(12,22)
print('测试的结果是',ret)demo.py
import test1.py # 只要导入了tets1.py,就会立刻执行 test1.py 代码,打印测试内容为了解决这个问题,python在执行一个文件时有个变量__name__.在Python中,当直接运行一个py文件时,这个py文件里的__name__值是__main__,据此可以判断一个一个py文件是被直接执行还是以模块的形式被导入。
def add(a,b):return a+bif __name__ == '__main__': # 只有直接执行这个py文件时,__name__的值才是 __main__# 以下代码只有直接运行这个文件才会执行,如果是文件被别的代码导入,下面的代码不会执行ret = add(12,22)print('测试的结果是',ret)注意事项:
在自定义模块时,需要注意一点,自定义模块名不要和系统的模块名重名,否则会出现问题!
6.包的使用
一个模块就是一个 py 文件,在 Python 里为了对模块分类管理,就需要划分不同的文件夹。多个有联系的模块可以将其放到同一个文件夹下,为了称呼方便,一般把 Python 里的一个代码文件夹称为一个包。
导入包的方式
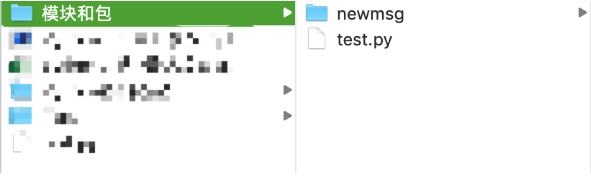
现有以下包newmsg,包里由两个模块,分别是sendmsg.py、recvmsg.py文件。在包的上级文件夹里,有一个test.py文件,目标是在test.py文件里引入newmsg的两个模块。
目录结构如下图所示:
sendmsg.py文件里的内容如下:
def send_msg():print('------sendmsg方法被调用了-------')recvmsg.py文件里的内容如下:
def recv_msg():print('-----recvmsg方法被调用了--------')可以使用以下几种方式来导入模块,使用模块里的方法。
1)直接使用包名.模块模块名导入指定的模块。
import newmsg.sendmsg
newmsg.sendmsg.send_msg()2)使用from xxx import xxx 方式导入指定模块。
from newmsg import sendmsg,recvmsg
sendmsg.send_msg()
recvmsg.recv_msg()