说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家!
程序的内存分区模型
1) 内存分区
1.1 运行之前
我们要想执行我们编写的c程序,那么第一步需要对这个程序进行编译。
- 预处理:宏定义展开、头文件展开、条件编译,这里并不会检查语法
- 编译:检查语法,将预处理后文件编译生成汇编文件
- 汇编:将汇编文件生成目标文件(二进制文件)
- 链接:将目标文件链接为可执行程序
当我们编译完成生成可执行文件之后,我们通过在linux下size命令可以查看一个可执行二进制文件基本情况:

通过上图可以得知,在没有运行程序前,也就是说程序没有加载到内存前,可执行程序内部已经分好3段信息,分别为代码区(text)、数据区(data)和未初始化数据区(bss)3 个部分(有些人直接把data和bss合起来叫做静态区或全局区)。
-
代码区
存放CPU执行的机器指令。通常代码区是可共享的(即另外的执行程序可以调用它),使其可共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指t令。另外,代码区还规划了局部变量的相关信息。 -
全局初始化数据区/静态数据区(data段)
该区包含了在程序中明确被初始化的全局变量、已经初始化的静态变量(包括全局静态变量和局部静态变量)和常量数据(如字符串常量)。 -
未初始化数据区(又叫 bss 区)
存入的是全局未初始化变量和未初始化静态变量。未初始化数据区的数据在程序开始执行之前被内核初始化为0或者空(NULL)。
总体来讲说,程序源代码被编译之后主要分成两种段:程序指令(代码区)和程序数据(数据区)。代码段属于程序指令,而数据域段和.bss段属于程序数据。
那为什么把程序的指令和程序数据分开呢?
- 程序被
load到内存中之后,可以将数据和代码分别映射到两个内存区域。由于数据区域对进程来说是可读可写的,而指令区域对程序来讲说是只读的,所以分区之后呢,可以将程序指令区域和数据区域分别设置成可读可写或只读。这样可以防止程序的指令有意或者无意被修改; - 当系统中运行着多个同样的程序的时候,这些程序执行的指令都是一样的,所以只需要内存中保存一份程序的指令就可以了,只是每一个程序运行中数据不一样而已,这样可以节省大量的内存。比如说之前的
Windows Internet Explorer 7.0运行起来之后, 它需要占用112844KB的内存,它的私有部分数据有大概15944KB,也就是说有96900KB空间是共享的,如果程序中运行了几百个这样的进程,可以想象共享的方法可以节省大量的内存。
1.2 运行之后
程序在加载到内存前,代码区和全局区(data和bss)的大小就是固定的,程序运行期间不能改变。然后,运行可执行程序,操作系统把物理硬盘程序load(加载)到内存,除了根据可执行程序的信息分出代码区(text)、数据区(data)和未初始化数据区(bss)之外,还额外增加了栈区、堆区。
-
代码区(text segment)
加载的是可执行文件代码段,所有的可执行代码都加载到代码区,这块内存是不可以在运行期间修改的。 -
未初始化数据区(BSS)
加载的是可执行文件BSS段,位置可以分开亦可以紧靠数据段,存储于数据段的数据(全局未初始化,静态未初始化数据)的生存周期为整个程序运行过程。 -
全局初始化数据区/静态数据区(
data segment)
加载的是可执行文件数据段,存储于数据段(全局初始化,静态初始化数据,文字常量(只读))的数据的生存周期为整个程序运行过程。 -
栈区(stack)
栈是一种先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。 -
堆区(heap)
堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。
| 类型 | 作用域 | 生命周期 | 存储位置 |
|---|---|---|---|
auto变量 | 一对{}内 | 当前函数 | 栈区 |
static局部变量 | 一对{}内 | 整个程序运行期 | 初始化在data段,未初始化在BSS段 |
extern变量 | 整个程序 | 整个程序运行期 | 初始化在data段,未初始化在BSS段 |
static全局变量 | 当前文件 | 整个程序运行期 | 初始化在data段,未初始化在BSS段 |
extern函数 | 整个程序 | 整个程序运行期 | 代码区 |
static函数 | 当前文件 | 整个程序运行期 | 代码区 |
register变量 | 一对{}内 | 当前函数 | 运行时存储在CPU寄存器 |
| 字符串常量 | 当前文件 | 整个程序运行期 | data段 |
总结:
栈区
1、先进后出(后进先出)
2、编译器管理数据开辟、释放
3、容量有限,不要将大量数据开辟到栈区
堆区
1、容量远远大于栈区
2、程序员手动开辟数据(malloc),手动释放数据(free)
2) 分区模型
2.1 栈区
由系统进行内存的管理。主要存放函数的参数以及局部变量。在函数完成执行,系统自行释放栈区内存,不需要用户管理。
栈区注意事项: 不要返回局部变量的地址,局部变量在函数体执行完毕过后会被释放,再次操作就是非法操作,结果未知!
示例1:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
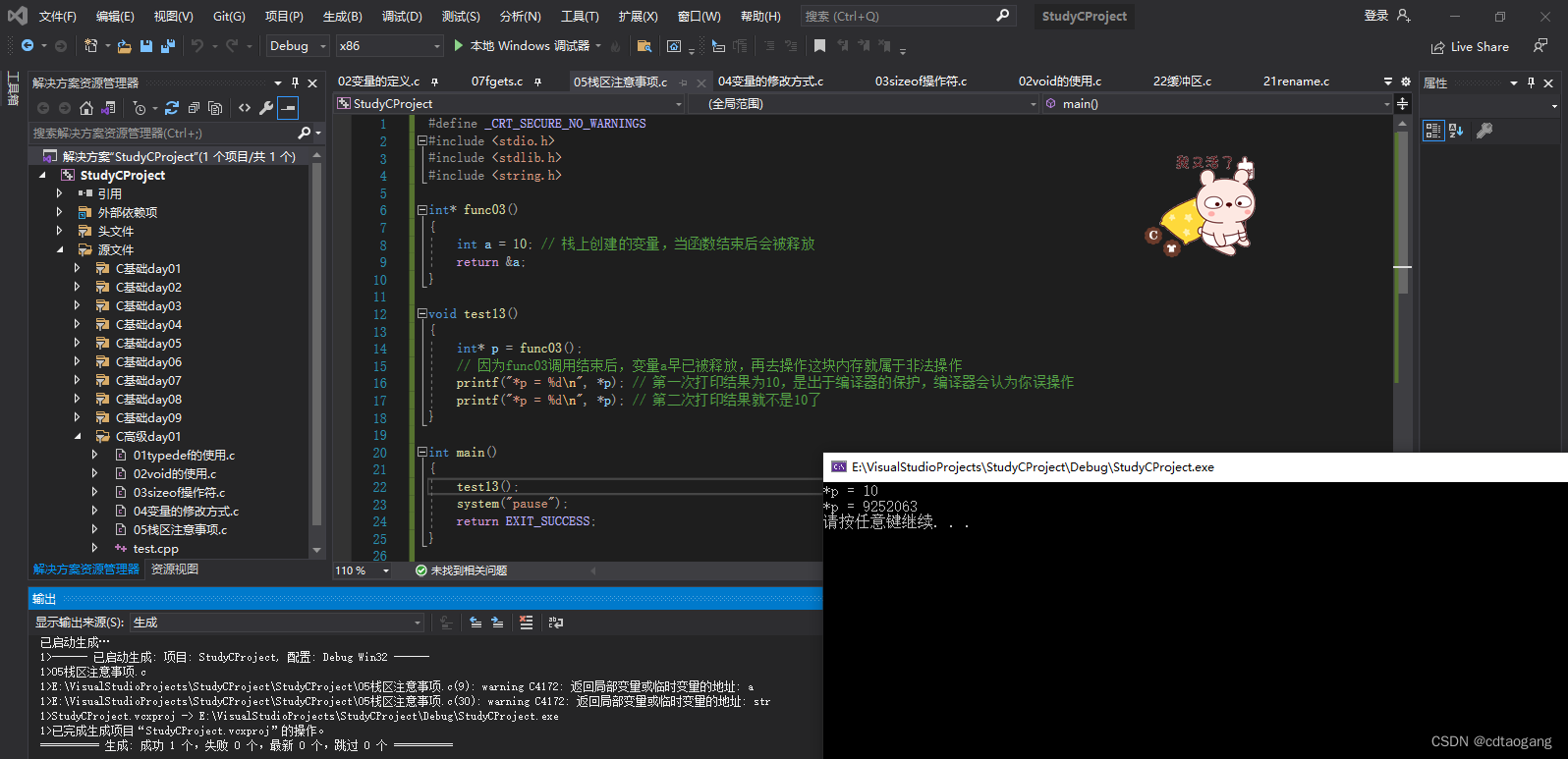
#include <string.h>int* func03()
{int a = 10; // 栈上创建的变量,当函数结束后会被释放return &a;
}void test13()
{int* p = func03();// 因为func03调用结束后,变量a早已被释放,再去操作这块内存就属于非法操作printf("*p = %d\n", *p); // 第一次打印结果为10,是出于编译器的保护,编译器会认为你误操作printf("*p = %d\n", *p); // 第二次打印结果就不是10了
}int main()
{test13();system("pause");return EXIT_SUCCESS;
}
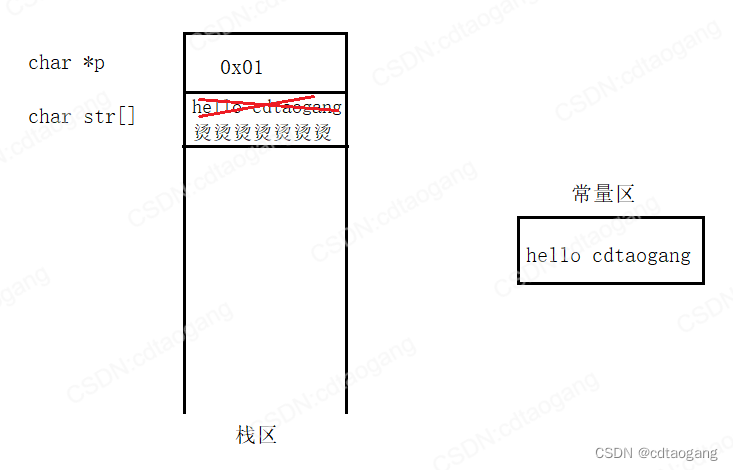
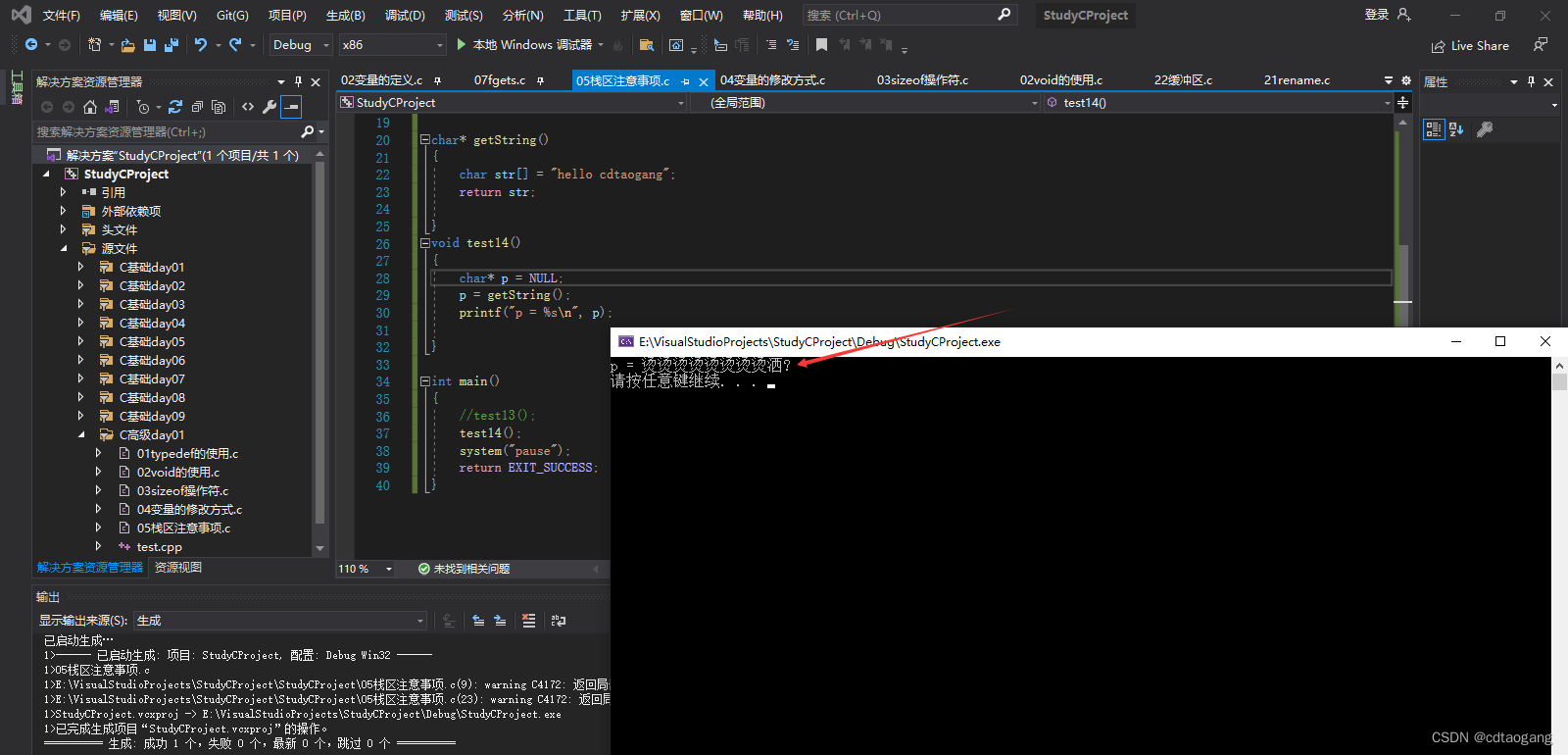
示例2:
char* getString()
{char str[] = "hello cdtaogang";return str;}
void test14()
{char* p = NULL;p = getString();printf("p = %s\n", p);}int main()
{test14();system("pause");return EXIT_SUCCESS;
}
2.2 堆区
由编程人员手动申请,手动释放,若不手动释放,程序结束后由系统回收,生命周期是整个程序运行期间。使用malloc或者new进行堆的申请。
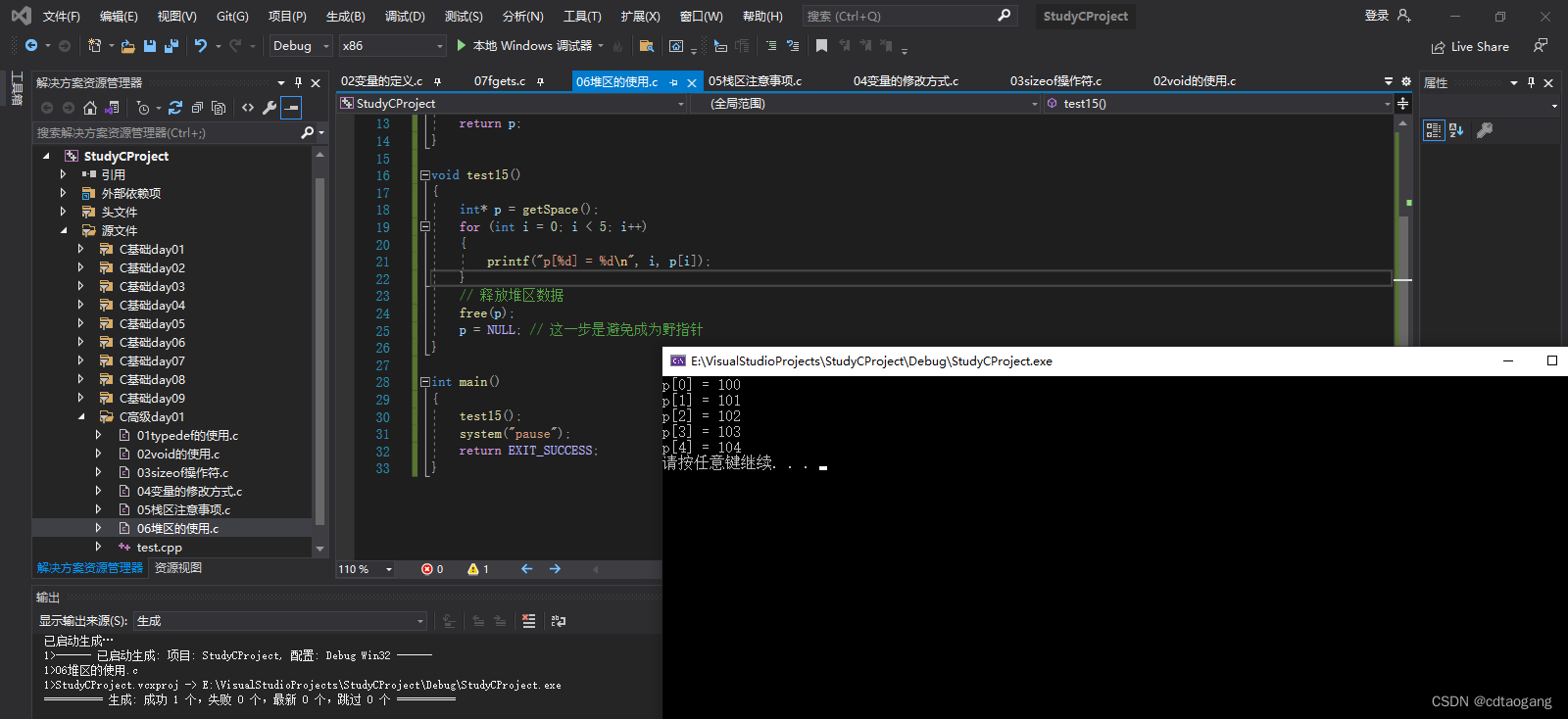
堆区的使用:
示例:
int* getSpace()
{int* p = malloc(sizeof(int) * 5);for (int i = 0; i < 5; i++){p[i] = 100 + i;}return p;
}void test15()
{int* p = getSpace();for (int i = 0; i < 5; i++){printf("p[%d] = %d\n", i, p[i]);}// 释放堆区数据free(p);p = NULL; // 这一步是避免成为野指针
}int main()
{test15();system("pause");return EXIT_SUCCESS;
}
堆区注意事项: 在主调函数中一个空指针分配内存,在被调函数中,利用同级的指针是分配(修饰)失败的。
示例:
void allocateSpace(char* pp)
{char* temp = malloc(100);memset(temp, 0, 100);strcpy(temp, "hello cdtaogang");pp = temp;
}void test16()
{char* p = NULL;allocateSpace(p);printf("p = %s\n", p);
}int main()
{test16();system("pause");return EXIT_SUCCESS;
}
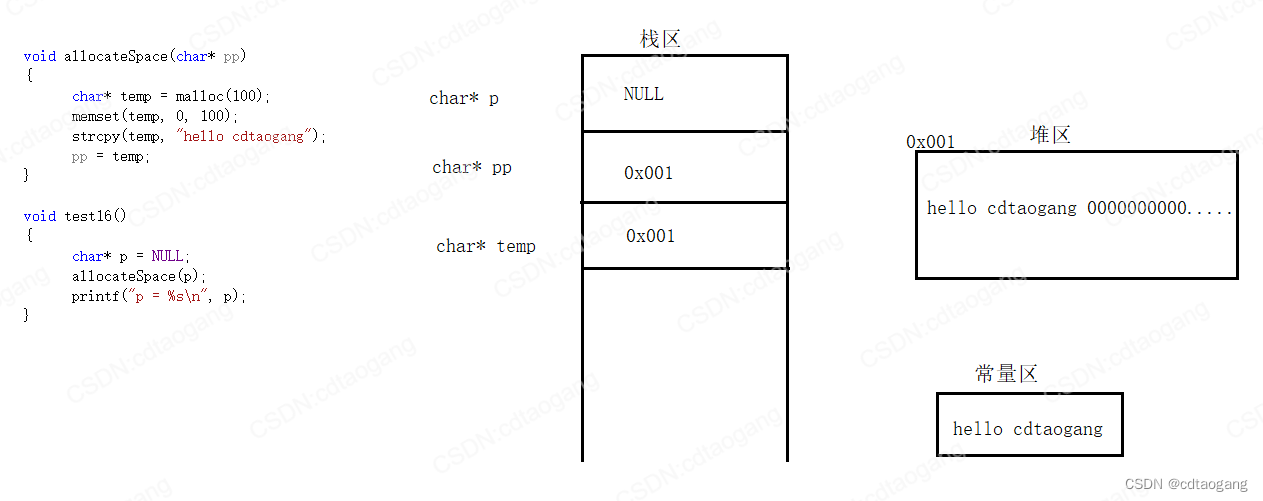
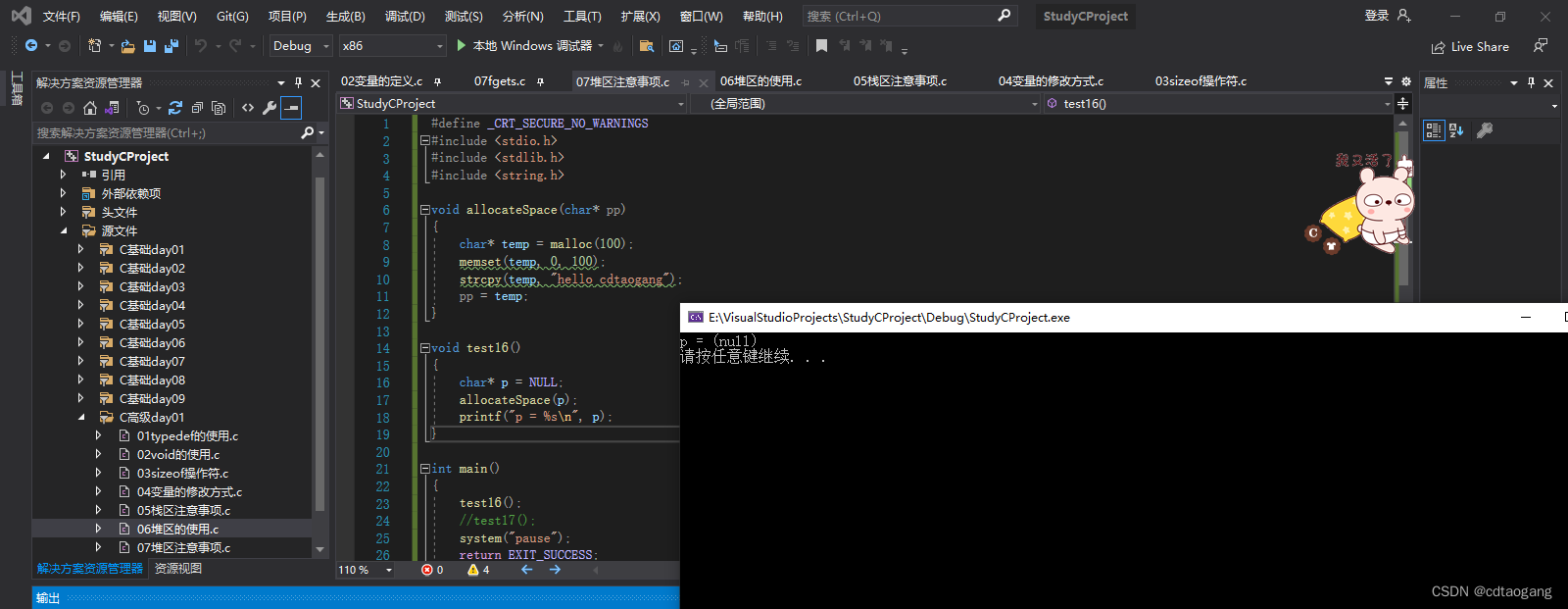
解决方法: 利用高级指针修饰低级指针
示例:
void allocateSpace2(char** pp)
{char* temp = malloc(100);memset(temp, 0, 100);strcpy(temp, "hello cdtaogang");*pp = temp;
}void test17()
{char* p = NULL;allocateSpace2(&p);printf("p = %s\n", p);
}
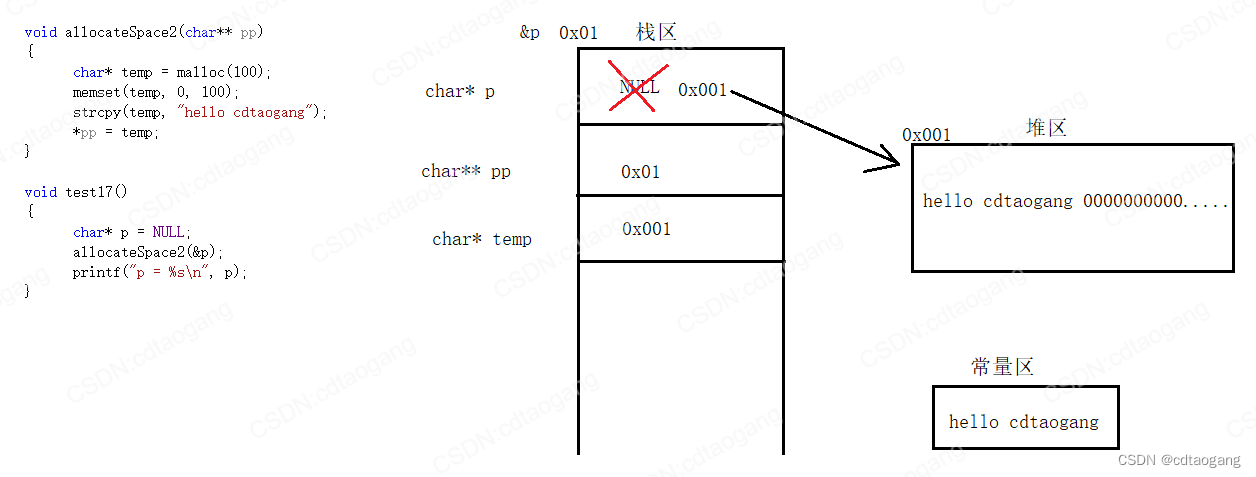
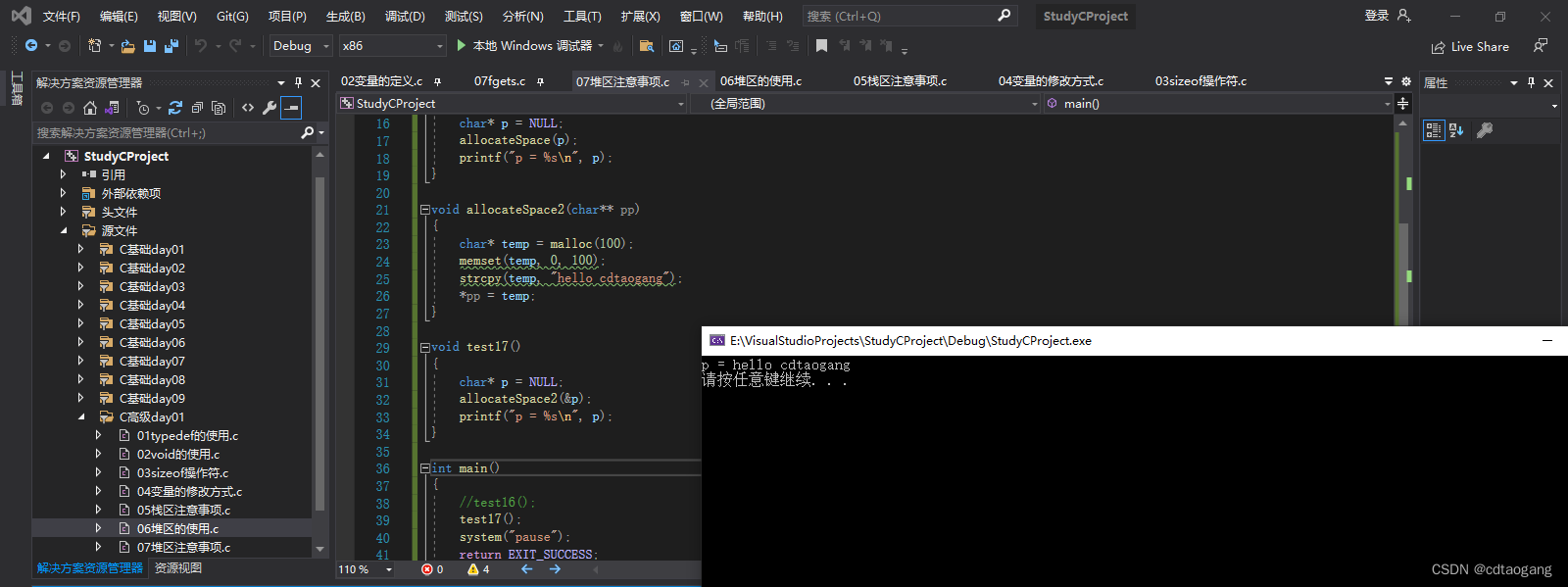
2.3 全局/静态区
全局静态区内的变量在编译阶段已经分配好内存空间并初始化。这块内存在程序运行期间一直存在,它主要存储全局变量、静态变量和常量。
注意:
(1)这里不区分初始化和未初始化的数据区,是因为静态存储区内的变量若不显示初始化,则编译器会自动以默认的方式进行初始化,即静态存储区内不存在未初始化的变量。
(2)全局静态存储区内的常量分为常变量和字符串常量,一经初始化,不可修改。静态存储内的常变量是全局变量,与局部常变量不同,区别在于局部常变量存放于栈,实际可间接通过指针或者引用进行修改,而全局常变量存放于静态常量区则不可以间接修改。
(3)字符串常量存储在全局/静态存储区的常量区。
- 静态变量
示例代码:只初始化一次,在编译阶段就分配内存,属于内部链接属性,只能在当前文件中使用
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 静态变量
static int a = 10; // 特点:只初始化一次,在编译阶段就分配内存,属于内部链接属性,只能在当前文件中使用void test18() // 局部静态变量,作用域只能在当前test18中
{ // a 和 b的生命周期是一样的static int b = 20;
}int main()
{ g_a = 2000; // error g_a默认为内部链接属性,在文件外是无法访问g_a的system("pause");return EXIT_SUCCESS;
}
- 全局变量
示例代码:在C语言下 全局变量前都隐藏加了关键字 extern,属于外部链接属性
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 静态变量
static int a = 10; // 特点:只初始化一次,在编译阶段就分配内存,属于内部链接属性,只能在当前文件中使用void test18() // 局部静态变量,作用域只能在当前test18中
{ // a 和 b的生命周期是一样的static int b = 20;
}// 全局变量
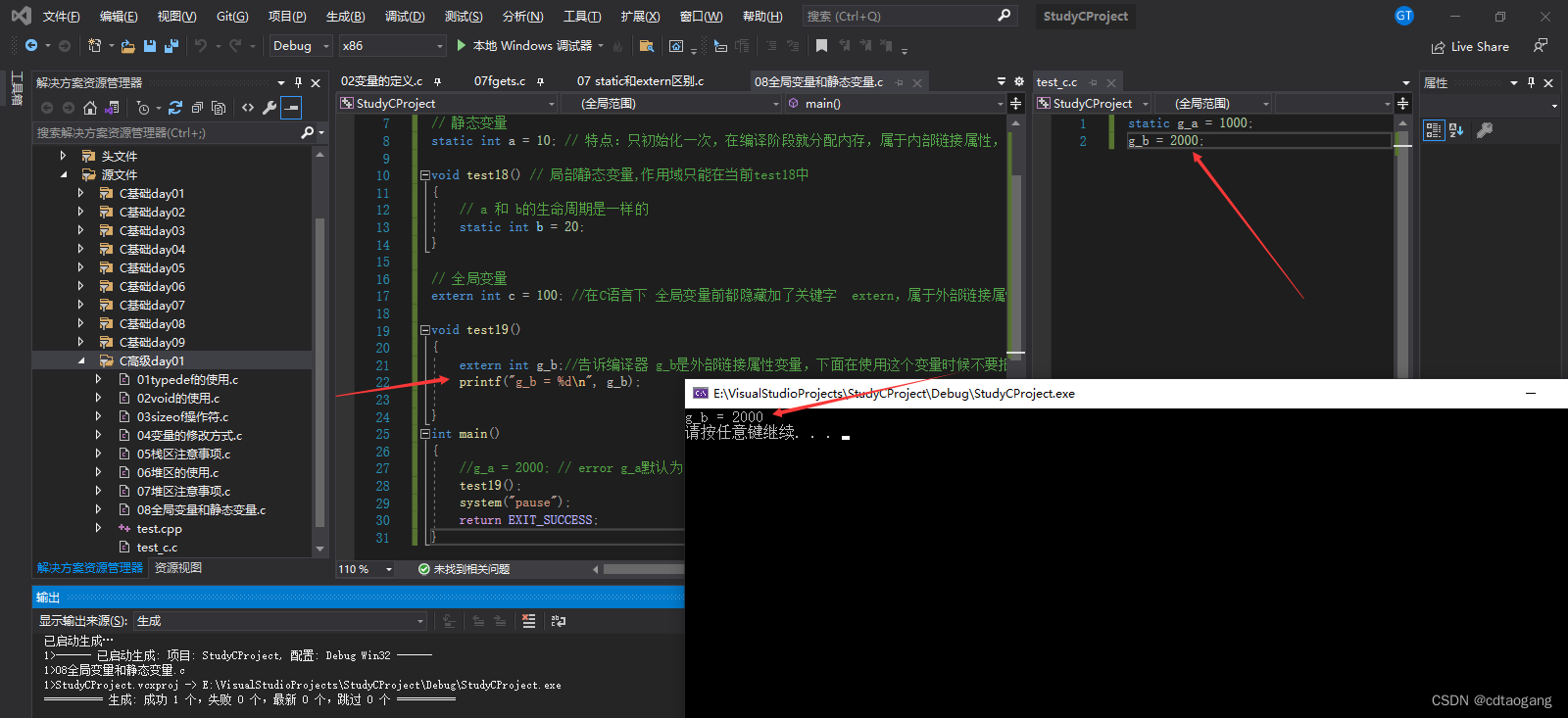
extern int c = 100; //在C语言下 全局变量前都隐藏加了关键字 extern,属于外部链接属性void test19()
{extern int g_b;//告诉编译器 g_b是外部链接属性变量,下面在使用这个变量时候不要报错printf("g_b = %d\n", g_b);}
int main()
{ //g_a = 2000; // error g_a默认为内部链接属性,在文件外是无法访问g_a的test19();system("pause");return EXIT_SUCCESS;
}
- 常量
示例代码:const修饰的全局变量,即使语法通过,但是运行时候受到常量区的保护,运行失败
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
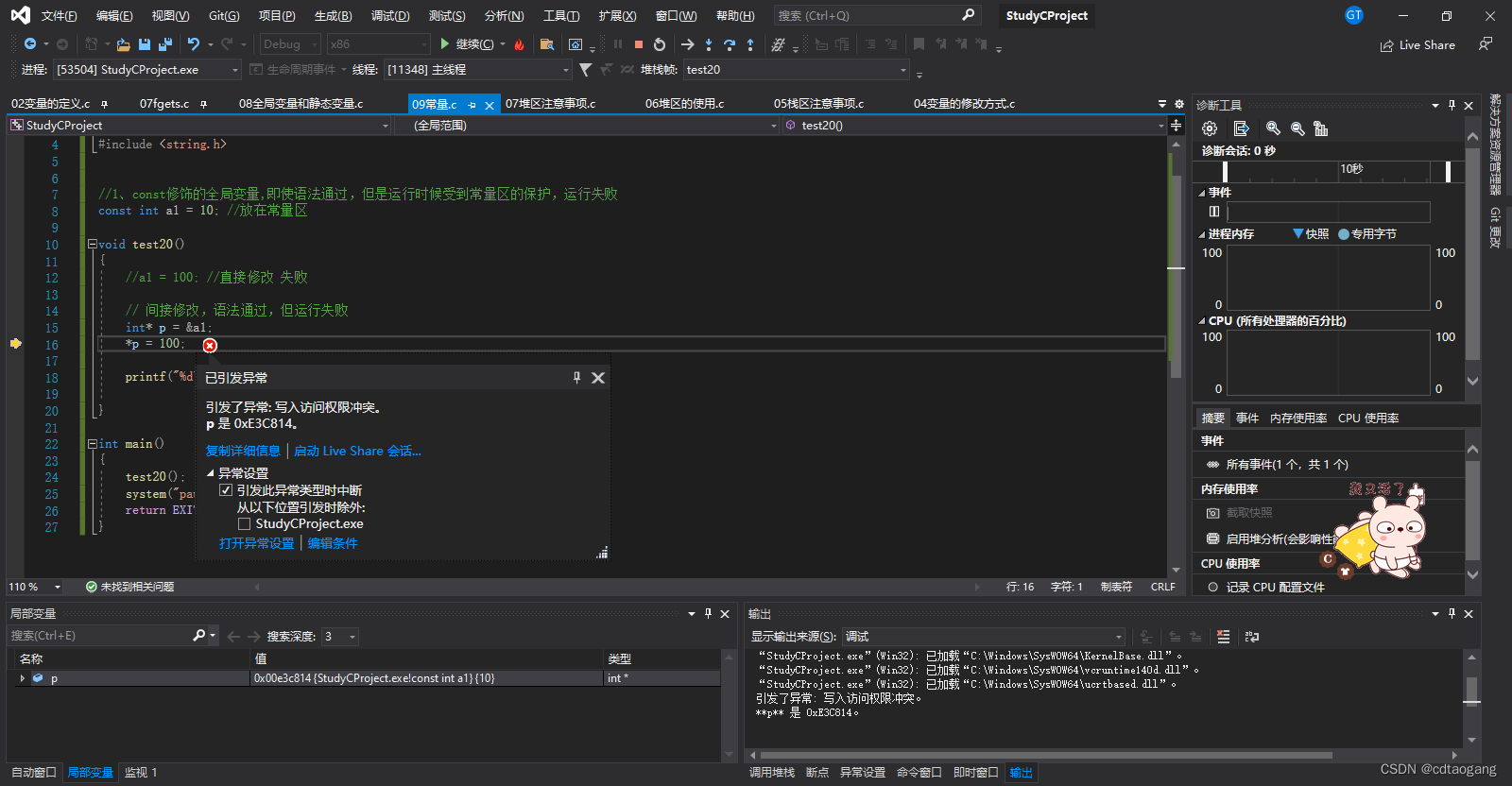
#include <string.h>//1、const修饰的全局变量,即使语法通过,但是运行时候受到常量区的保护,运行失败
const int a1 = 10; //放在常量区void test20()
{//a1 = 100; //直接修改 失败// 间接修改,语法通过,但运行失败int* p = &a1;*p = 100;printf("%d\n", a1);
}int main()
{test20();system("pause");return EXIT_SUCCESS;
}
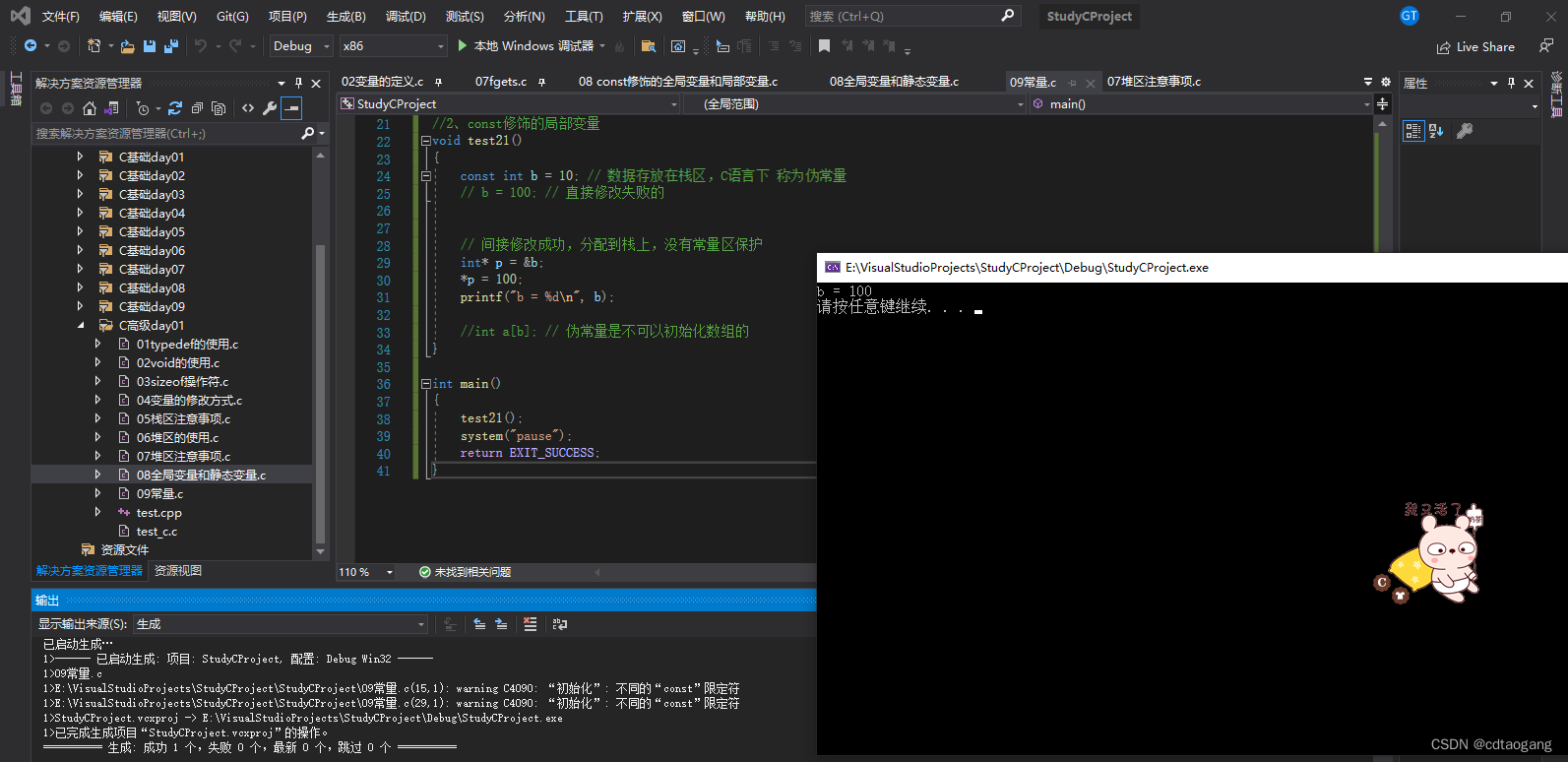
示例代码:const修饰的局部变量,数据存放在栈区,C语言下称为伪常量,不受常量区保护
//2、const修饰的局部变量
void test21()
{const int b = 10; // 数据存放在栈区,C语言下称为伪常量// b = 100; // 直接修改失败的// 间接修改成功,分配到栈上,没有常量区保护int* p = &b;*p = 100;printf("b = %d\n", b);//int a[b]; // 伪常量是不可以初始化数组的
}int main()
{test21();system("pause");return EXIT_SUCCESS;
}
示例代码:字符串常量是可以共享的,不允许修改字符串常量
//3、字符串常量
void test22()
{char* p1 = "hello cdtaogang";char* p2 = "hello cdtaogang";char* p3 = "hello cdtaogang";// 字符串常量是可以共享的printf("%d\n", p1);printf("%d\n", p2);printf("%d\n", p3);printf("%d\n", &"hello cdtaogang");p1[0] = 'b'; // 不允许修改字符串常量printf("%c\n", p1[0]);
}int main()
{test22();system("pause");return EXIT_SUCCESS;
}
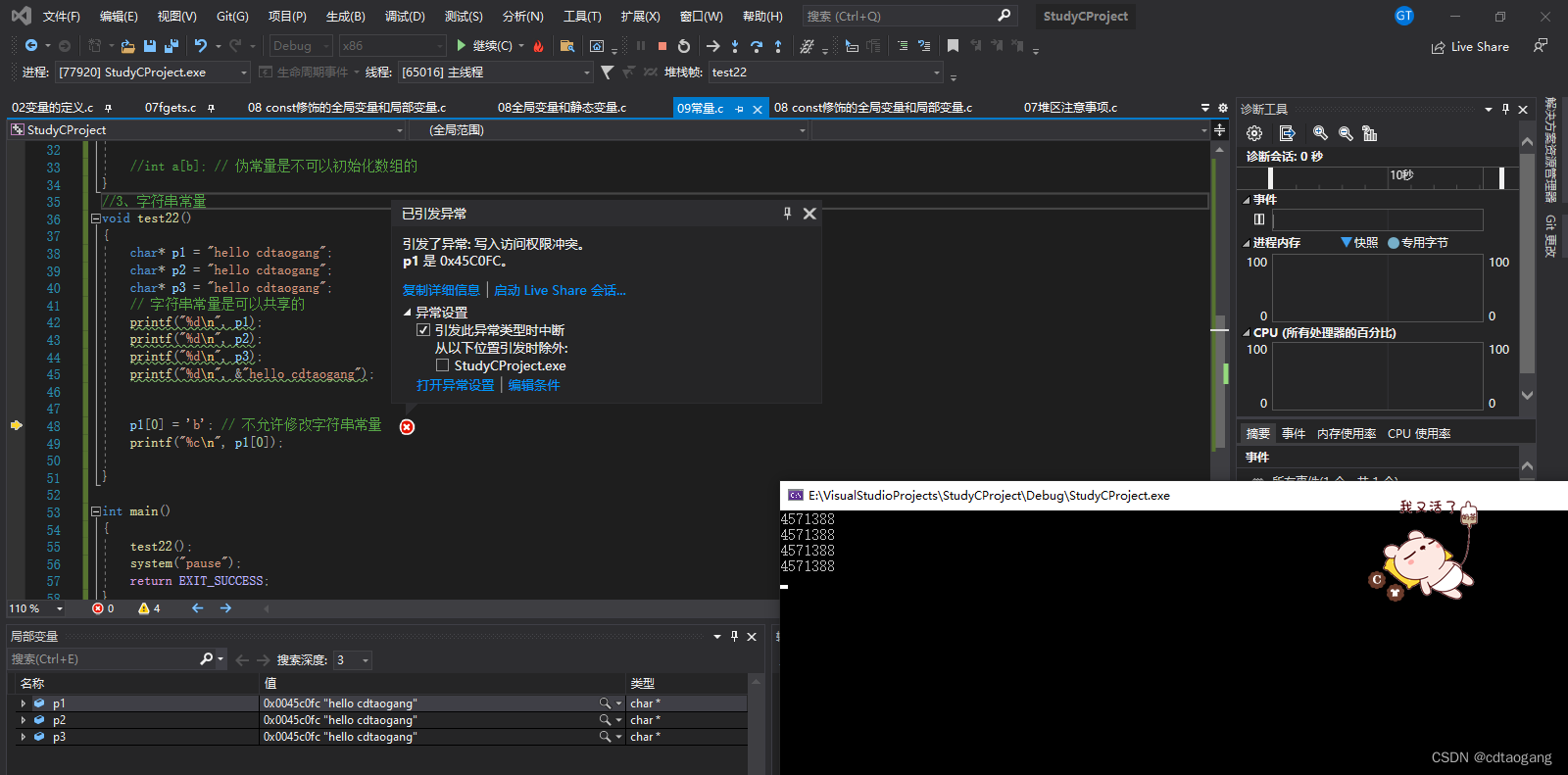
字符串常量是否可修改?字符串常量优化:
ANSI C中规定:修改字符串常量,结果是未定义的。 ANSI C并没有规定编译器的实现者对字符串的处理,例如:
1.有些编译器可修改字符串常量,有些编译器则不可修改字符串常量。
2.有些编译器把多个相同的字符串常量看成一个(这种优化可能出现在字符串常量中,节省空间),有些则不进行此优化。如果进行优化,则可能导致修改一个字符串常量导致另外的字符串常量也发生变化,结果不可知。
所以尽量不要去修改字符串常量!
字符串常量地址是否相同?
TC2.0,同文件字符串常量地址不同。
VS2013及以上,字符串常量地址同文件和不同文件都相同。
Dev C++、QT同文件相同,不同文件不同。
2.4 总结
在理解C/C++内存分区时,常会碰到如下术语:数据区,堆,栈,静态区,常量区,全局区,字符串常量区,文字常量区,代码区等等,初学者被搞得云里雾里。在这里,尝试捋清楚以上分区的关系。
数据区包括: 堆,栈,全局/静态存储区。
全局/静态存储区包括: 常量区,全局区、静态区。
常量区包括: 字符串常量区、常变量区。
代码区: 存放程序编译后的二进制代码,不可寻址区。
可以说,C/C++内存分区其实只有两个,即代码区和数据区
3) 函数调用模型
3.1 宏函数
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MYADD(x, y) x+y
// 运算保证完整性
#define MYADD2(x, y) ((x)+(y))// 在预编译阶段做了宏替换
// 宏函数注意:保证运算的完整性
// 宏函数使用场景:将频繁短小的函数,封装为宏函数
// 优点:以空间换时间(入栈和出栈的时间)
void test23()
{int a = 10;int b = 20;printf("a + b = %d\n", MYADD(a, b)); // x+y == a+b == 10+20 = 30printf("a + b = %d\n", MYADD(a, b) * 20); // x+y*20 == a+b*20 == 10+20*20 == 410// 运算保证完整性printf("a + b = %d\n", MYADD2(a, b)); // 30printf("a + b = %d\n", MYADD2(a, b) * 20); // 600
}int main()
{test23();system("pause");return EXIT_SUCCESS;
}
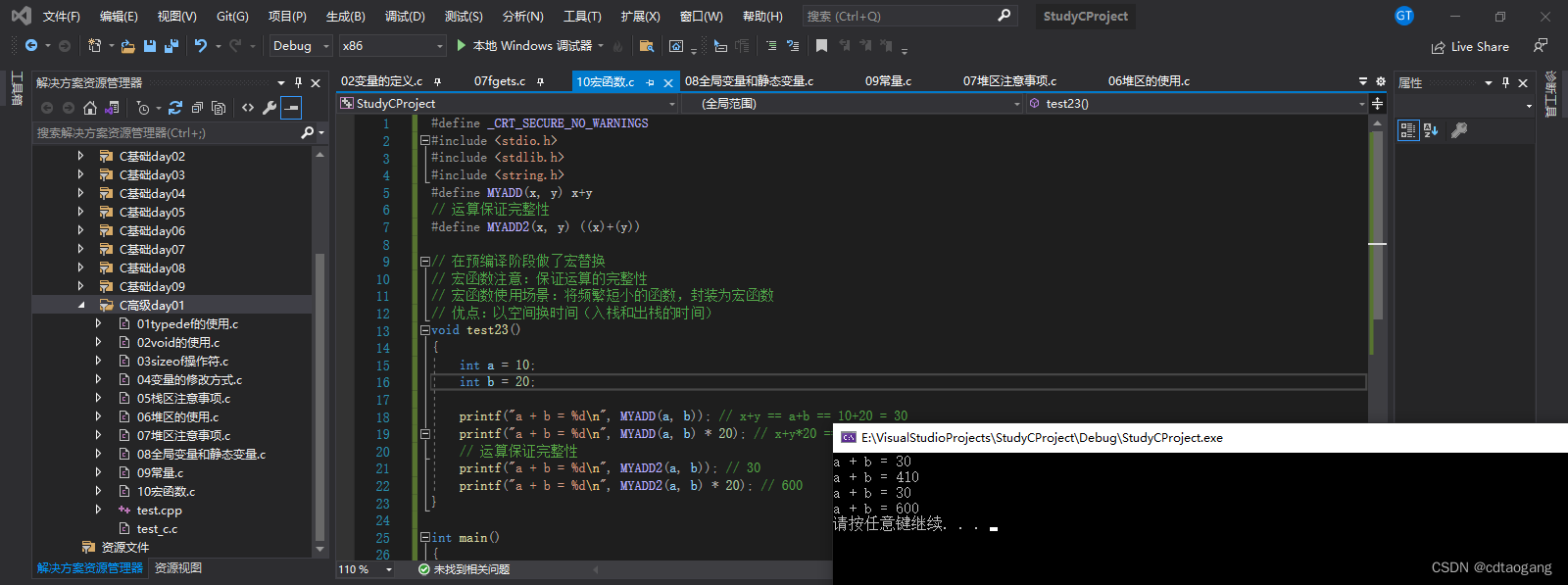
3.2 函数调用流程
栈(stack)是现代计算机程序里最为重要的概念之一,几乎每一个程序都使用了栈,没有栈就没有函数,没有局部变量,也就没有我们如今能见到的所有计算机的语言。在解释为什么栈如此重要之前,我们先了解一下传统的栈的定义:
在经典的计算机科学中,栈被定义为一个特殊的容器,用户可以将数据压入栈中(入栈,push),也可以将压入栈中的数据弹出(出栈,pop),但是栈容器必须遵循一条规则:先入栈的数据最后出栈(First In Last Out,FILO)
在经典的操作系统中,栈总是向下增长的。压栈的操作使得栈顶的地址减小,弹出操作使得栈顶地址增大。
栈在程序运行中具有极其重要的地位。最重要的,栈保存一个函数调用所需要维护的信息,这通常被称为堆栈帧(Stack Frame)或者活动记录(Activate Record).一个函数调用过程所需要的信息一般包括以下几个方面:
- 函数的返回地址;
- 函数的参数;
- 局部变量;
- 保存的上下文:包括在函数调用前后需要保持不变的寄存器。
我们从下面的代码,分析以下函数的调用过程:
int func(int a,int b){int t_a = a;int t_b = b;return t_a + t_b;
}int main(){int ret = 0;ret = func(10, 20);return EXIT_SUCCESS;
}
思考1:a、b变量入栈,是从左往右还是从右往左?
思考2:a、b变量是由main函数(主调函数)管理释放还是由func函数(被调函数)管理释放?
3.3 调用惯例
现在,我们大致了解了函数调用的过程,这期间有一个现象,那就是函数的调用者和被调用者对函数调用有着一致的理解,例如,它们双方都一致的认为函数的参数是按照某个固定的方式压入栈中。如果不这样的话,函数将无法正确运行。
如果函数调用方在传递参数的时候先压入a参数,再压入b参数,而被调用函数则认为先压入的是b,后压入的是a,那么被调用函数在使用a,b值时候,就会颠倒。
因此,函数的调用方和被调用方对于函数是如何调用的必须有一个明确的约定,只有双方都遵循同样的约定,函数才能够被正确的调用,这样的约定被称为 “调用惯例(Calling Convention) ” ,一个调用惯例一般包含以下几个方面:
函数参数的传递顺序和方式
函数的传递有很多种方式,最常见的是通过栈传递。函数的调用方将参数压入栈中,函数自己再从栈中将参数取出。对于有多个参数的函数,调用惯例要规定函数调用方将参数压栈的顺序:从左向右,还是从右向左。有些调用惯例还允许使用寄存器传递参数,以提高性能。
栈的维护方式
在函数将参数压入栈中之后,函数体会被调用,此后需要将被压入栈中的参数全部弹出,以使得栈在函数调用前后保持一致。这个弹出的工作可以由函数的调用方来完成,也可以由函数本身来完成。
为了在链接的时候对调用惯例进行区分,调用惯例要对函数本身的名字进行修饰。不同的调用惯例有不同的名字修饰策略。
事实上,在c语言里,存在着多个调用惯例,而默认的是cdecl.任何一个没有显示指定调用惯例的函数都是默认是cdecl惯例。比如我们上面对于func函数的声明,它的完整写法应该是:
int _cdecl func(int a,int b);
注意: _cdecl不是标准的关键字,在不同的编译器里可能有不同的写法,例如gcc里就不存在_cdecl这样的关键字,而是使用__attribute__((cdecl)).
| 调用惯例 | 出栈方 | 参数传递 | 名字修饰 |
|---|---|---|---|
cdecl | 函数调用方 | 从右至左参数入栈 | 下划线+函数名 |
stdcall | 函数本身 | 从右至左参数入栈 | 下划线+函数名+@+参数字节数 |
fastcall | 函数本身 | 前两个参数由寄存器传递,其余参数通过堆栈传递。 | @+函数名+@+参数的字节数 |
pascal | 函数本身 | 从左至右参数入栈 | 较为复杂,参见相关文档 |
3.4 函数变量传递分析
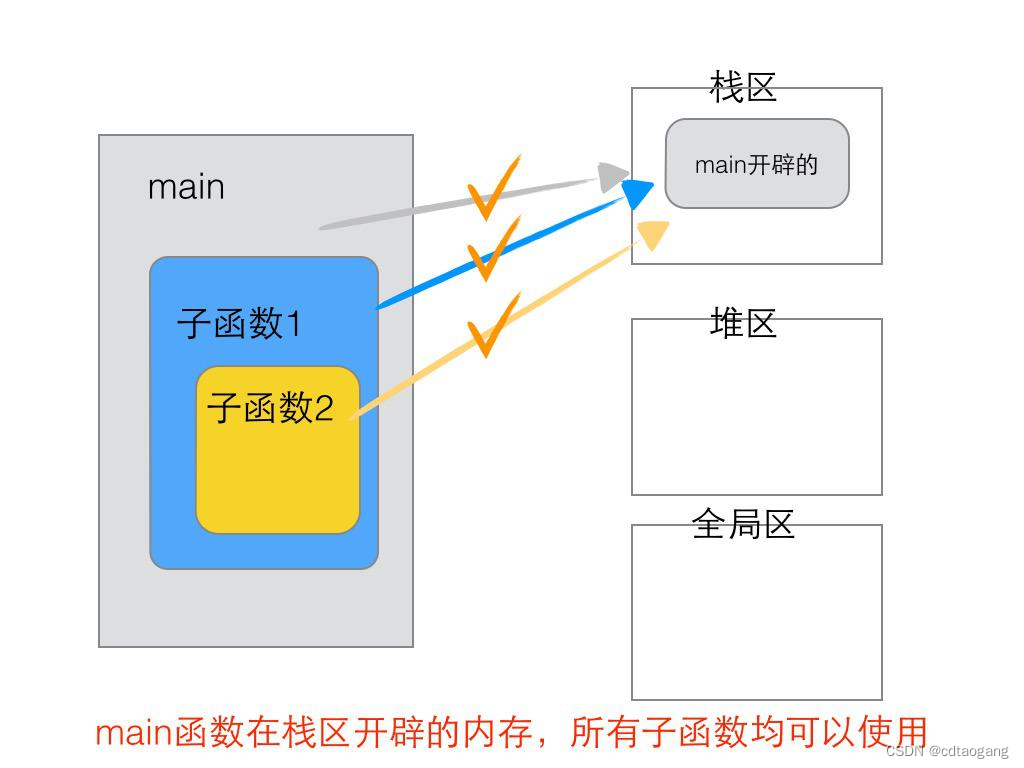
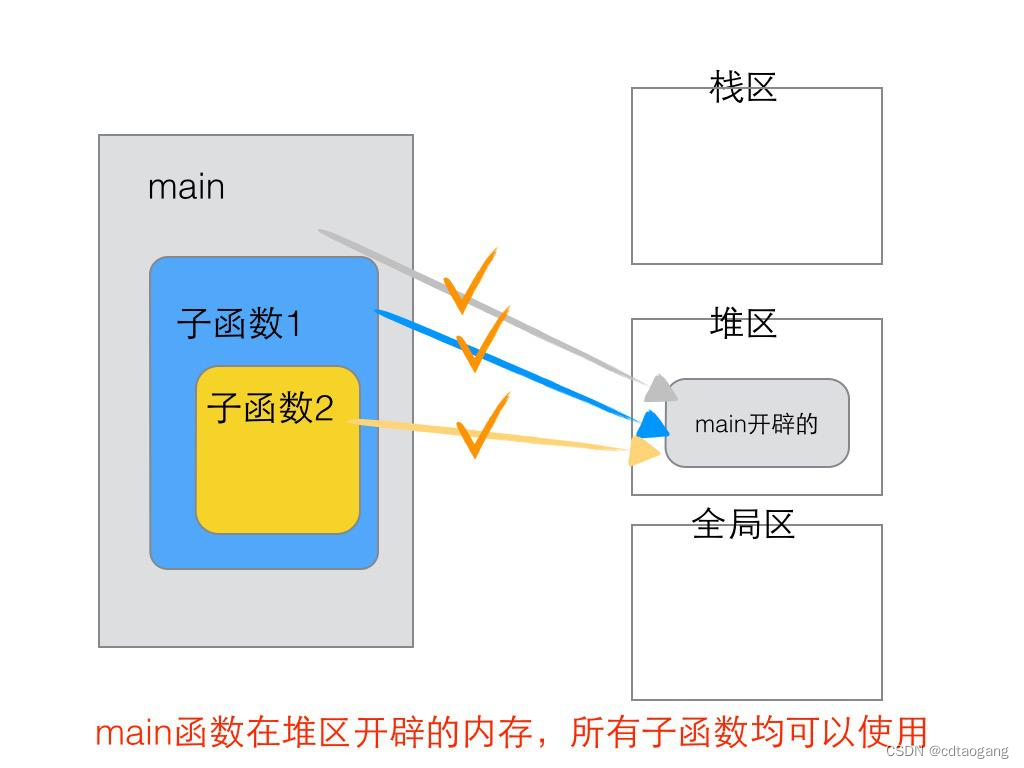
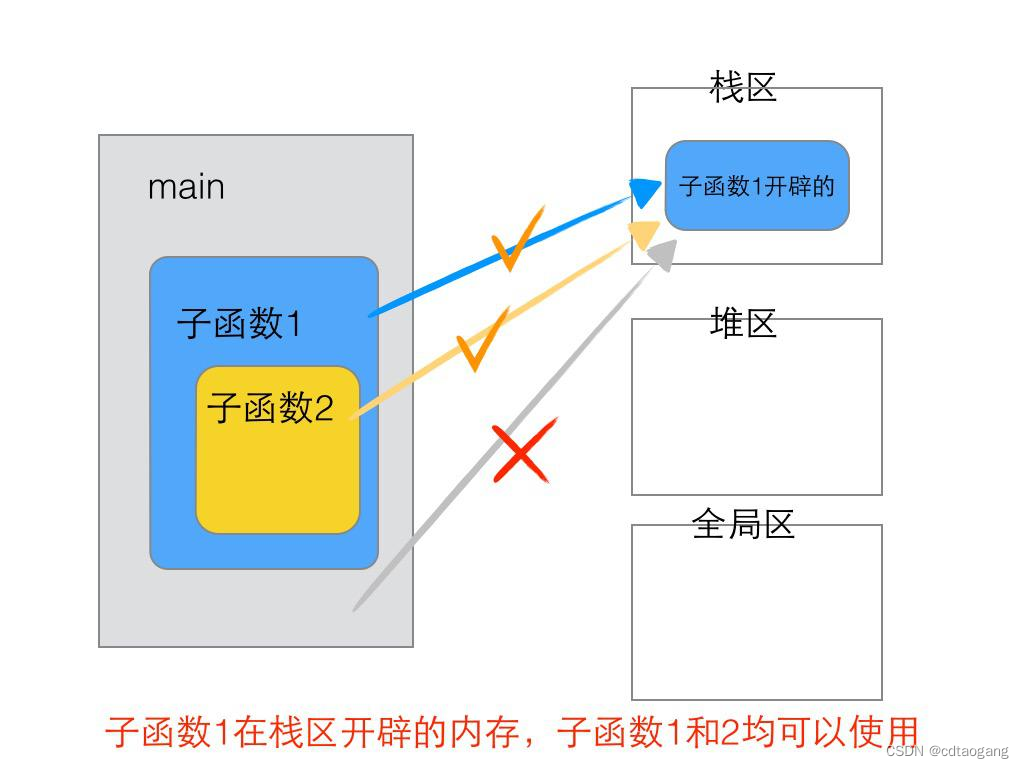
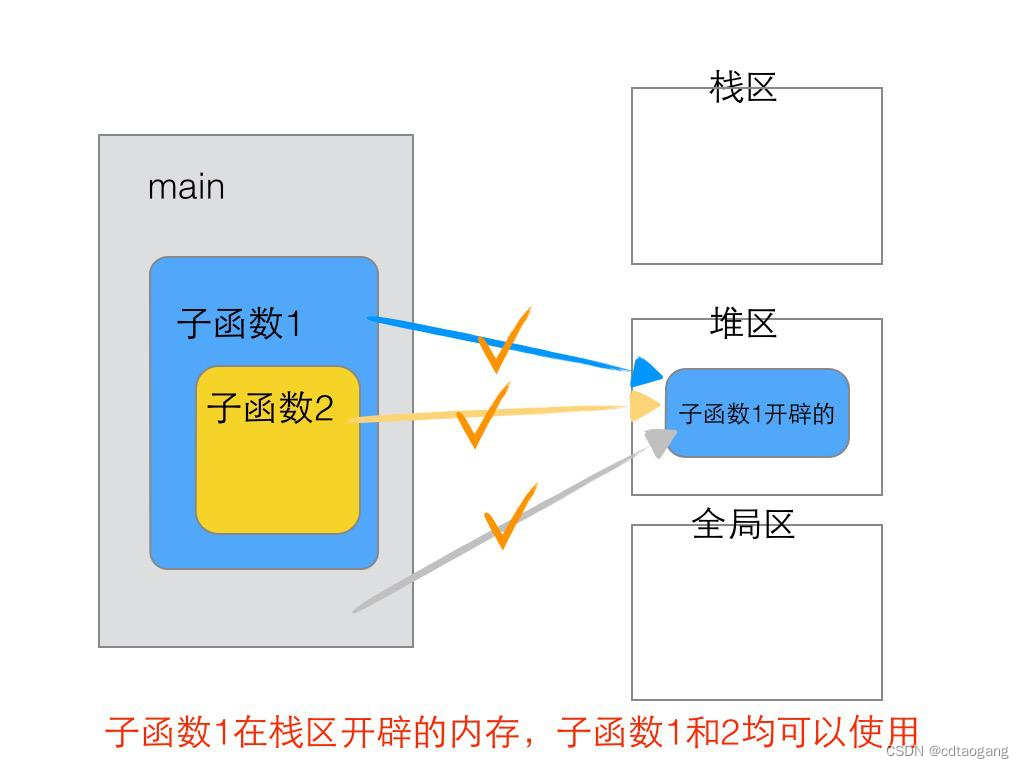
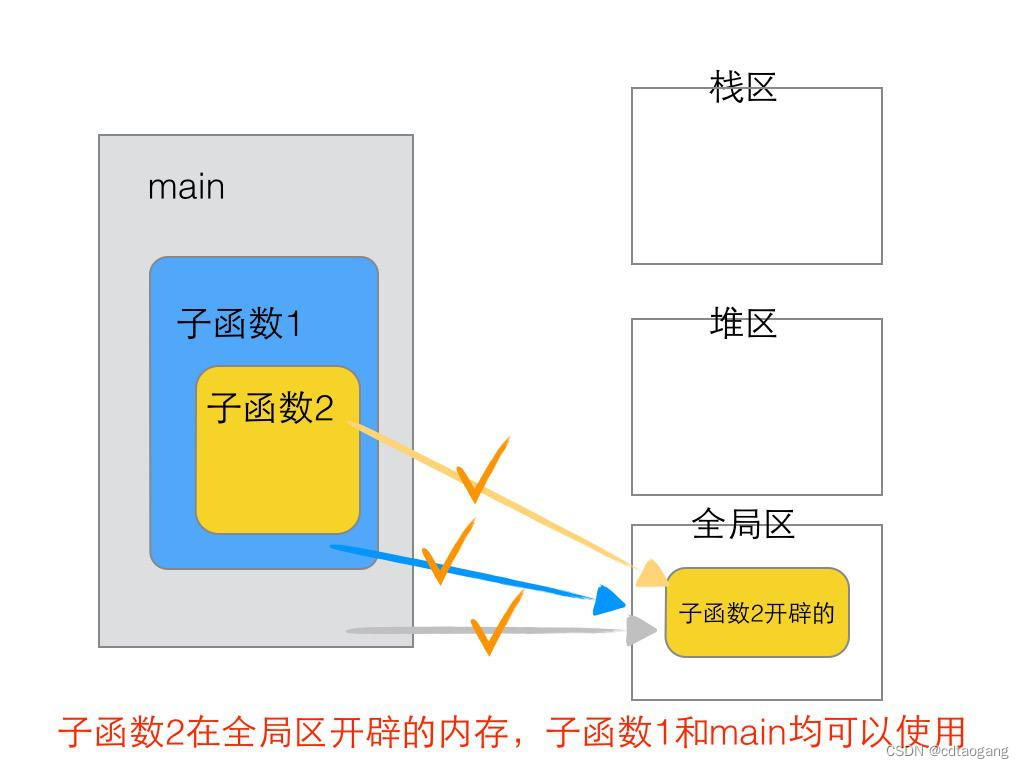
简单示例:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>void B()
{}void A()
{int b; // 在函数A、B中可以使用,但在main函数中使用不了B();
}int main()
{int a; // 在main函数和A、B函数中都可以使用(传参)A();system("pause");return EXIT_SUCCESS;
}
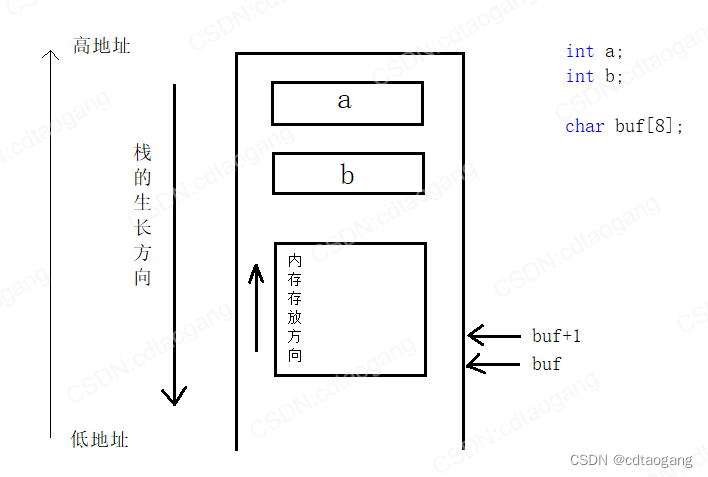
4) 栈的生长方向和内存存放方向
4.1 栈的生长方向
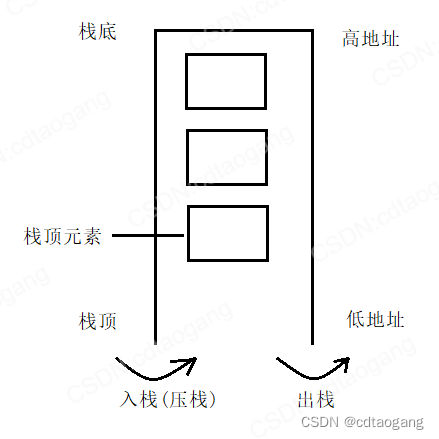
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 栈的生长方向
void test24()
{int a = 10; // 栈底-高地址int b = 20;int c = 30;int d = 40; // 栈顶-低地址printf("%d\n", &a);printf("%d\n", &b);printf("%d\n", &c);printf("%d\n", &d);
}int main()
{test24();system("pause");return EXIT_SUCCESS;
}
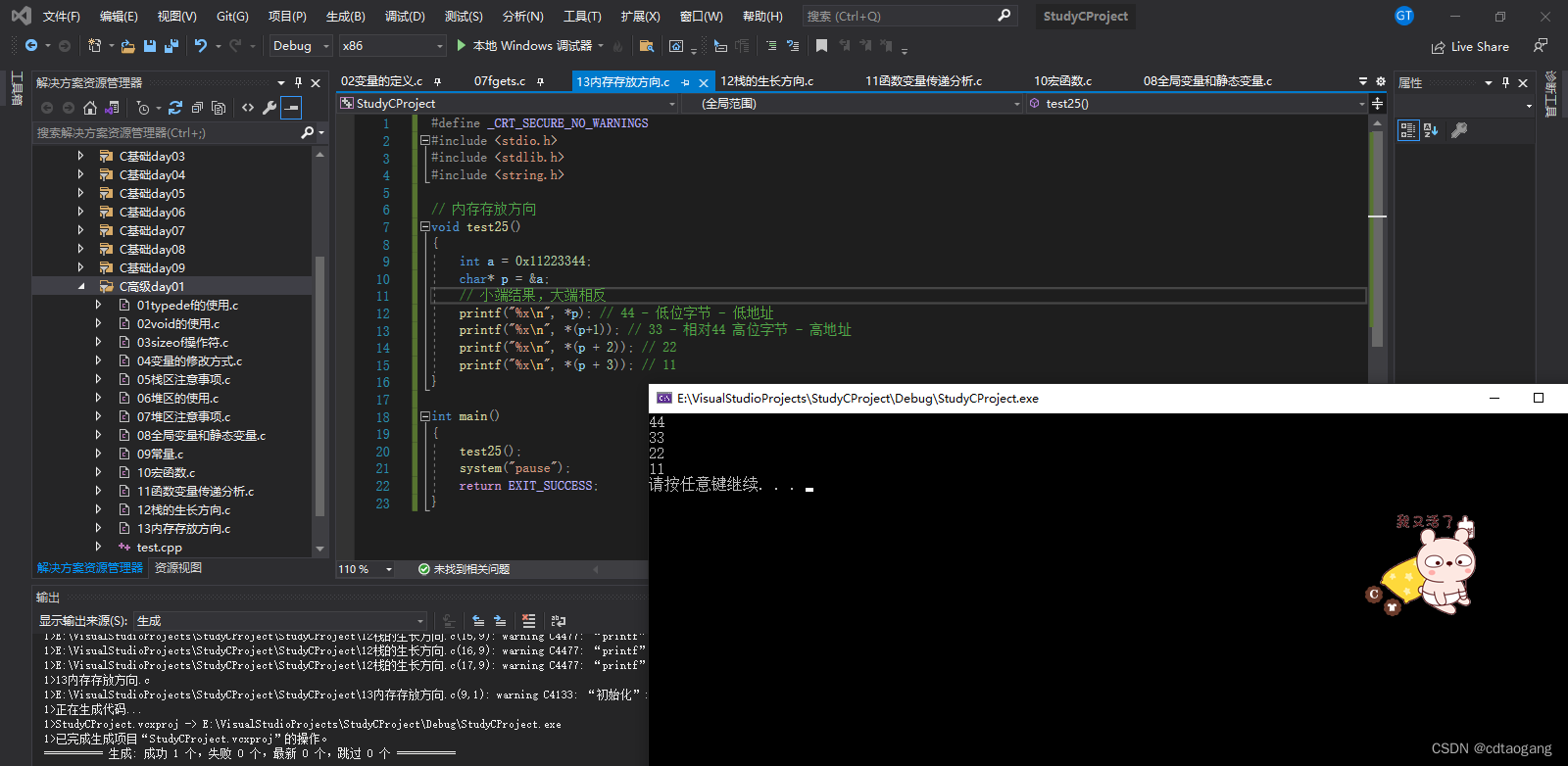
4.2 内存存放方向
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 内存存放方向
void test25()
{int a = 0x11223344;char* p = &a;// 小端结果,大端相反printf("%x\n", *p); // 44 - 低位字节 - 低地址printf("%x\n", *(p+1)); // 33 - 相对44 高位字节 - 高地址printf("%x\n", *(p + 2)); // 22printf("%x\n", *(p + 3)); // 11
}int main()
{test25();system("pause");return EXIT_SUCCESS;
}