论文:Inverted Residuals and Linear Bottlenecks Mobile Networks for Classification, Detection and Segmentation
链接:https://128.84.21.199/abs/1801.04381
第三方代码(可用于在ImageNet数据集上训练):https://github.com/miraclewkf/MobileNetV2-PyTorch
这篇文章提出的MobileNet V2是之前MobileNet V1的改进版。MobileNet V1中主要是引入了depthwise separable convolution代替传统的卷积操作,相当于实现了spatial和channel之间的解耦,达到模型加速的目的,整体网络结构还是延续了VGG网络直上直下的特点,具体可以参考博客:MobileNet。和MobileNet V1相比,MobileNet V2主要的改进有两点:1、Linear Bottlenecks。也就是去掉了小维度输出层后面的非线性激活层,目的是为了保证模型的表达能力。2、Inverted Residual block。该结构和传统residual block中维度先缩减再扩增正好相反,因此shotcut也就变成了连接的是维度缩减后的feature map。接下来分别介绍这两部分内容。
第一部分是Linear Bottlenecks
在MobileNet V1中除了引入depthwise separable convolution代替传统的卷积,还做了一个实验是用width multiplier参数来做模型通道的缩减,相当于给模型“瘦身”,这样特征信息就能更集中在缩减后的通道中,但是如果此时加上一个非线性激活层,比如ReLU,就会有较大的信息丢失,因此为了减少信息丢失,就有了文中的linear bottleneck,意思就是bottleneck的输出不接非线性激活层,所以是linear,而什么是bottleneck的输出?就是维度缩减那一层的输出。原文是这么说的:assuming the manifold of interest is low-dimensional we can capture this by inserting linear bottleneck layers into the convolutional blocks. Experimental evidence suggests that using linear layers is crucial as it prevents nonlinearities from destroying too much information. 后面Figure1有实验证明。
To summarize, we have highlighted two properties that are indicative of the requirement that the manifold of interest should lie in a low-dimensional subspace of the higher-dimensional activation space:
1. If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to
a linear transformation.
2. ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
第一点的意思是:对于ReLU层输出的非零值而言,ReLU层起到的就是一个线性变换的作用,这个从ReLU的曲线就能看出来。
第二点的意思是:ReLU层可以保留input manifold的信息,但是只有当input manifold是输入空间的一个低维子空间时才有效。
Figure1是证明ReLU对不同维度输入的信息丢失对比。图表下面的文字介绍了具体的操作过程,显然,当把原始输入维度增加到15或30后再作为ReLU的输入,输出恢复到原始维度后基本不会丢失太多的输入信息;相比之下如果原始输入维度只增加到2或3后再作为ReLU的输入,输出恢复到原始维度后信息丢失较多。因此在MobileNet V2中,执行降维的卷积层后面不会接类似ReLU这样的非线性激活层,也就是linear bottleneck的含义。

第二部分是Inverted residuals
Figure2展示了从传统卷积到depthwise separable convolution再到本文中的inverted residual block的差异。(a)表示传统的3*3卷积操作,假设输入channel数量为n,那么(a)中红色立方体(卷积核)的维度就是3*3*n。(b)就是在MobileNet V1中采用的depthwise separable convolution。(c)是在(b)的基础上增加了一个类似bottleneck的操作(最窄的那个)。(d)和(c)在本质上是一样的,想象无数个相连的(c)和无数个相连的(d)。另外要注意的是在(c)和(d)中虚线框后面是没有激活层的,这正是前面第一部分的内容。(d)正是本文MobileNet V2的inverted residual block结构,和原来ResNet中residual block对维度的操作正好是相反的。

Figure3是residual block和本文的inverted residual block的对比。在residual block中是先降维再升维,在inverted residual block中是先升维再降维。

下面的这两张图是原文中的Figure6,分别是对前面两部分的效果做的总结。
左边图(a)是关于non-linearity的效果(蓝色曲线),显然top1准确率要高于在bottleneck后加relu层(绿色曲线 ),证明了Linear Bottlenecks的有效性。原文的描述如下:Theoretically, the linear bottleneck models are strictly less powerful than models with non-linearities, because the activations can always operate in linear regime with appropriate changes to biases and scaling. However our experiments shown in Figure 6a indicate that linear bottlenecks improve performance, providing a strong support for the hypothesis that a non-linearity operator is not beneficial in the low-dimensional space of a bottleneck.
右边图(b)是关于shotcut连接在不同维度的feature map上的影响,换句话说就是inverted residual(蓝色曲线)和传统residual(绿色曲线)的差别,证明了inverted residual的有效性,红色曲线是不加shotcut的情况。原文的描述如下:The new result reported in this paper is that the shortcut connecting bottleneck perform better than shortcuts connecting the expanded layers (see Figure 6b for comparison).

整体的网络结构如Table2所示。图中有几个问题:1、文中说有19层,但是在table2中只有17层。2、第6行的input应该是14*14*64,而不是28*28*64,因为第5行采用的是stride=2的卷积。3、最后一行的input应该是1*1*1280,而不是1*1*k。表中的t表示expansion factor,也就是每个inverted residual block的第一个1*1卷积的升维比率,比如第三行的输入channel是16,则每个inverted residual block的第一个1*1卷积的输入channel是16,输出channel是16*6。c是每个inverted residual block的最后一层输出channel。n表示block的重复个数,s表示stride。

实验结果:
Table4是几个加速模型在ImageNet数据集上的Top1准确率以及模型大小、速度的对比。
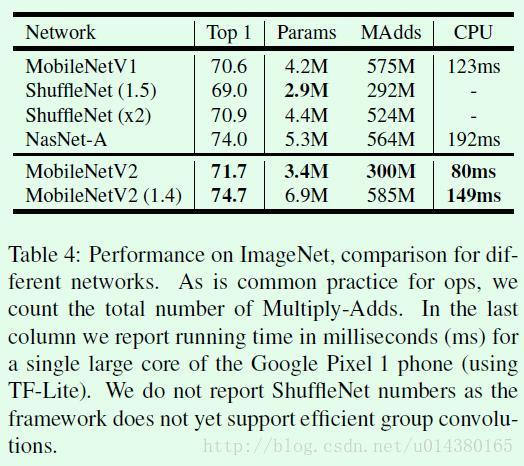
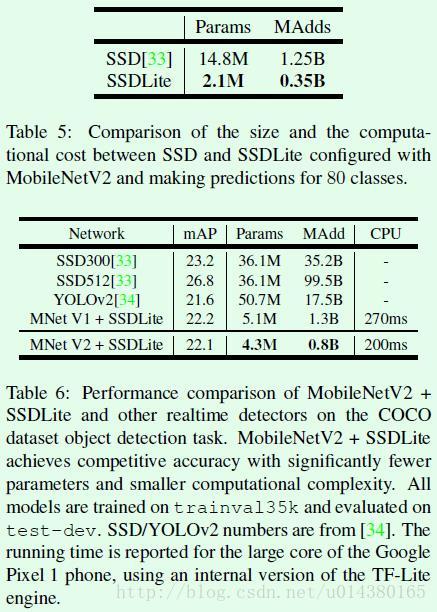
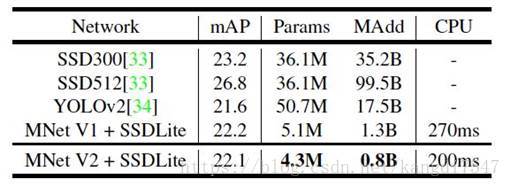
Table5是关于SSD和SSDLite在关于参数量和计算量上的对比。SSDLite是将SSD网络中的3*3卷积用depthwise separable convolution代替得到的。
Table6是几个常见目标检测模型的对比。