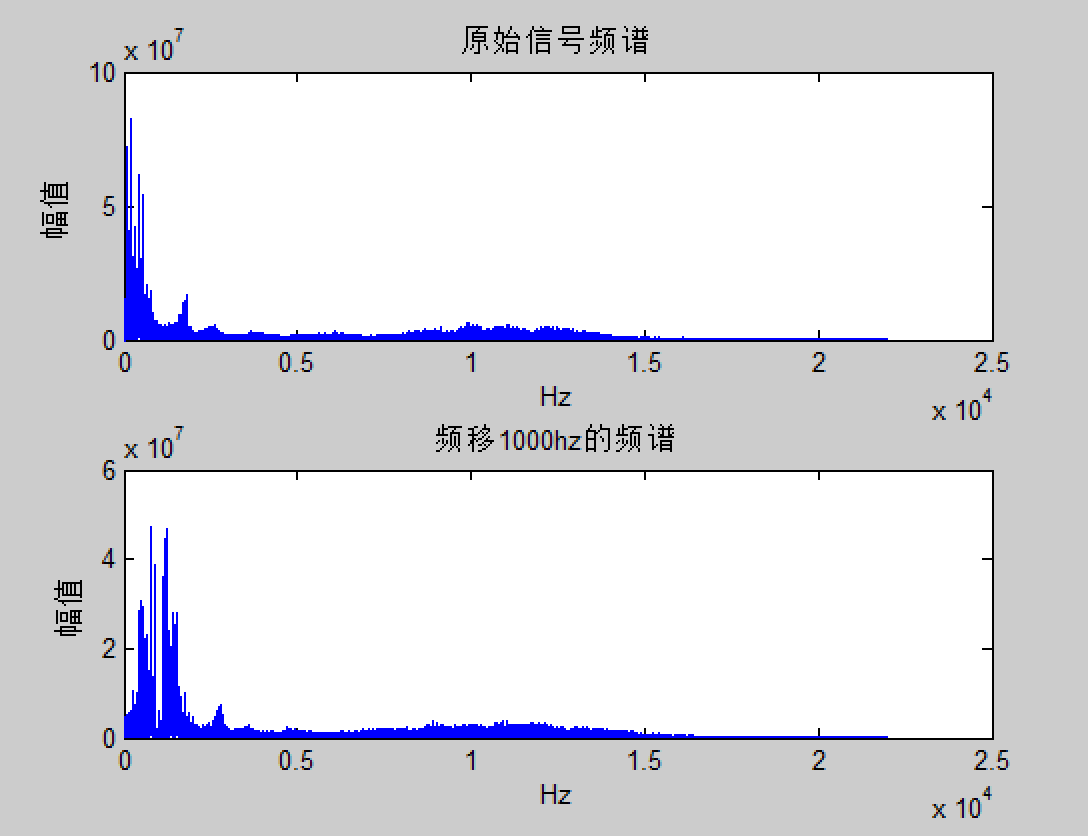
声音最重要的两个元素就是语速和语调,改变声音的辨识度主要也是从这两方面入手。我们可以通过对音频数据进行插值或者抽值修改,以达到降低语速和增加语速的目的。同时我们也可以通过对数据进行线性拉伸来调节音调。语速调整+语调调整,就可以让我们的声音千变万化。
在视频处理过程中,为了保证音画同步效果,我们一般不会通过调节语速来进行变声。视频变声处理一般都是通过调节音调来实现变声效果的。这里介绍一下如何通过使用FFmpeg的音频滤镜实现变调不变速的效果。
变声效果实现需要使用三个滤镜分别是:asetrate、aresample和atempo。asetrate在保持PCM数据不变的情况下调节采样率,这会导致语速和语调发生变化,语速和音调发生变化之后,再使用aresample滤镜将采样率恢复。这样一来音频数据的语速和音调就发生变化了,由于我们只想改变音调不想改变语速,所以我们通过atempo滤镜将语速恢复正常。
变调不变速滤镜的流程图如下图所示:

滤镜初始化
通过FFmpeg初始化变声滤镜的示例如下所示。通过滤镜处理的音频数据,音调会发生变化。
//滤镜描述
char description[512];
double ratio = 0.7;
int new_sample_rate = output_audio_encode_ctx->sample_rate* ratio;
double tempo = 1.0 / ratio;snprintf(description, sizeof(description),"[in]asetrate=%d[res];[res]aresample=%d[res1];[res1]atempo=%0.3f[out]",new_sample_rate,output_audio_encode_ctx->sample_rate,tempo
);bool init_change_tone_filter(AVFilterGraph* graph, const char* filter_desc)
{//创建输入输出参数AVFilterInOut *outputs = avfilter_inout_alloc();AVFilterInOut *inputs = avfilter_inout_alloc();char src_des[512];char ch_layout[128];int nb_channels = 0;int pix_fmts[] = {output_audio_encode_ctx->sample_fmt, AV_SAMPLE_FMT_NONE };nb_channels = av_get_channel_layout_nb_channels(audio_decode_ctx->channel_layout);av_get_channel_layout_string(ch_layout, sizeof(ch_layout), nb_channels, audio_decode_ctx->channel_layout);//设置输入的采样的参数sprintf(src_des, "time_base=%d/%d:sample_rate=%d:sample_fmt=%d:channel_layout=%s:channels=%d",audio_decode_ctx->time_base.num, audio_decode_ctx->time_base.den, audio_decode_ctx->sample_rate, audio_decode_ctx->sample_fmt, ch_layout,nb_channels);//初始化输入缓存const AVFilter *src_filter = avfilter_get_by_name("abuffer");int ret = avfilter_graph_create_filter(&buffersrc_ctx, src_filter, "in1", src_des, NULL, graph);if (ret < 0){goto end;}//初始化输出缓存const AVFilter *sink_filter = avfilter_get_by_name("abuffersink");ret = avfilter_graph_create_filter(&buffersink_ctx, sink_filter, "out", NULL, NULL, graph);if (ret < 0){goto end;}ret = av_opt_set_int_list(buffersink_ctx, "sample_fmts", pix_fmts,AV_SAMPLE_FMT_NONE, AV_OPT_SEARCH_CHILDREN);//指定输出引脚outputs->name = av_strdup("in");outputs->filter_ctx = buffersrc_ctx;outputs->pad_idx = 0;outputs->next = NULL;//指定输入引脚inputs->name = av_strdup("out");inputs->filter_ctx = buffersink_ctx;inputs->pad_idx = 0;inputs->next = NULL;//初始化滤镜if ((ret = avfilter_graph_parse_ptr(graph, filter_desc, &inputs, &outputs, NULL)) < 0)goto end;//滤镜生效ret = avfilter_graph_config(graph, NULL);if (ret < 0)goto end;av_buffersink_set_frame_size(buffersink_ctx, output_audio_encode_ctx->frame_size);end://释放对应的输入输出avfilter_inout_free(&inputs);avfilter_inout_free(&outputs);return ret;
}
工程示例
这里我们通过音频滤镜对输入视频文件中的音频流进行变声处理,处理之后再进行输出。这样一来视频文件中的音频辨识度就会被掩盖。
#pragma execution_character_set("utf-8")
#define _CRT_SECURE_NO_WARNINGS
#include <string>
#include <iostream>
#include <thread>
#include <memory>
#include <iostream>
#include <fstream>extern "C"
{
#include <libavcodec/avcodec.h>
#include <libavfilter/avfilter.h>
#include <libavformat/avformat.h>
#include <libavformat/avio.h>
#include <libavutil/avutil.h>
#include <libavutil/frame.h>
#include <libavutil/time.h>
#include <libavfilter/buffersink.h>
#include <libavfilter/buffersrc.h>
#include <libavutil/opt.h>
}
#include "AudioFilter.h"using namespace std;//输入媒体文件的上下文
AVFormatContext * input_format_ctx = nullptr;//输出媒体文件的上下文
AVFormatContext* output_format_ctx;//音视频解码器
AVCodecContext *audio_decode_ctx = NULL;//视频索引和音频索引
int video_stream_index = -1;
int audio_stream_index = -1;//输出音频编码器
static AVCodec * output_audio_codec;
//输出音频编码器的上下文
AVCodecContext* output_audio_encode_ctx = NULL;//滤镜容器和缓存
AVFilterGraph* audio_graph = NULL;
AVFilterContext *buffersink_ctx = nullptr;;
AVFilterContext *buffersrc_ctx = nullptr;;
AVPacket packet;//起始时间
static int64_t startTime;int open_output_file(char *fileName)
{int ret = 0;ret = avformat_alloc_output_context2(&output_format_ctx, NULL, NULL, fileName);if (ret < 0){return -1;}//创建输出流for (int index = 0; index < input_format_ctx->nb_streams; index++){if (index == video_stream_index){AVStream * stream = avformat_new_stream(output_format_ctx, NULL);avcodec_parameters_copy(stream->codecpar, input_format_ctx->streams[video_stream_index]->codecpar);stream->codecpar->codec_tag = 0;}else if (index == audio_stream_index){//打开解码器AVCodec* audio_decoder = avcodec_find_decoder(input_format_ctx->streams[audio_stream_index]->codecpar->codec_id);audio_decode_ctx = avcodec_alloc_context3(audio_decoder);avcodec_parameters_to_context(audio_decode_ctx, input_format_ctx->streams[audio_stream_index]->codecpar);ret = avcodec_open2(audio_decode_ctx, audio_decoder, NULL);//创建编码器AVCodec *encoder = avcodec_find_encoder(output_format_ctx->oformat->audio_codec);output_audio_encode_ctx = avcodec_alloc_context3(encoder);output_audio_encode_ctx->codec_id = encoder->id;output_audio_encode_ctx->sample_fmt = audio_decode_ctx->sample_fmt;output_audio_encode_ctx->sample_rate = audio_decode_ctx->sample_rate;output_audio_encode_ctx->channel_layout = audio_decode_ctx->channel_layout;output_audio_encode_ctx->channels = av_get_channel_layout_nb_channels(audio_decode_ctx->channel_layout);output_audio_encode_ctx->bit_rate = audio_decode_ctx->bit_rate;output_audio_encode_ctx->time_base = { 1, audio_decode_ctx->sample_rate };ret = avcodec_open2(output_audio_encode_ctx, encoder, nullptr);//创建音频输出流AVStream * stream = avformat_new_stream(output_format_ctx, encoder);stream->id = output_format_ctx->nb_streams - 1;stream->time_base = output_audio_encode_ctx->time_base;if (output_format_ctx->oformat->flags & AVFMT_GLOBALHEADER)output_format_ctx->flags |= AV_CODEC_FLAG_GLOBAL_HEADER;ret = avcodec_parameters_from_context(stream->codecpar, output_audio_encode_ctx);av_dict_copy(&stream->metadata, input_format_ctx->streams[audio_stream_index]->metadata, 0);}}//打开输出流ret = avio_open(&output_format_ctx->pb, fileName, AVIO_FLAG_WRITE);if (ret < 0){return -2;}//写文件头信息ret = avformat_write_header(output_format_ctx, nullptr);if (ret < 0){return -3;}if (ret >= 0)cout << "open output stream successfully" << endl;return ret;
}bool init_change_tone_filter(AVFilterGraph* graph, const char* filter_desc)
{//创建输入输出参数AVFilterInOut *outputs = avfilter_inout_alloc();AVFilterInOut *inputs = avfilter_inout_alloc();char src_des[512];char ch_layout[128];int nb_channels = 0;int pix_fmts[] = {output_audio_encode_ctx->sample_fmt, AV_SAMPLE_FMT_NONE };nb_channels = av_get_channel_layout_nb_channels(audio_decode_ctx->channel_layout);av_get_channel_layout_string(ch_layout, sizeof(ch_layout), nb_channels, audio_decode_ctx->channel_layout);//设置输入的采样的参数sprintf(src_des, "time_base=%d/%d:sample_rate=%d:sample_fmt=%d:channel_layout=%s:channels=%d",audio_decode_ctx->time_base.num, audio_decode_ctx->time_base.den, audio_decode_ctx->sample_rate, audio_decode_ctx->sample_fmt, ch_layout,nb_channels);//初始化输入缓存const AVFilter *src_filter = avfilter_get_by_name("abuffer");int ret = avfilter_graph_create_filter(&buffersrc_ctx, src_filter, "in1", src_des, NULL, graph);if (ret < 0){goto end;}//初始化输出缓存const AVFilter *sink_filter = avfilter_get_by_name("abuffersink");ret = avfilter_graph_create_filter(&buffersink_ctx, sink_filter, "out", NULL, NULL, graph);if (ret < 0){goto end;}ret = av_opt_set_int_list(buffersink_ctx, "sample_fmts", pix_fmts,AV_SAMPLE_FMT_NONE, AV_OPT_SEARCH_CHILDREN);//指定输出引脚outputs->name = av_strdup("in");outputs->filter_ctx = buffersrc_ctx;outputs->pad_idx = 0;outputs->next = NULL;//指定输入引脚inputs->name = av_strdup("out");inputs->filter_ctx = buffersink_ctx;inputs->pad_idx = 0;inputs->next = NULL;//初始化滤镜if ((ret = avfilter_graph_parse_ptr(graph, filter_desc, &inputs, &outputs, NULL)) < 0)goto end;//滤镜生效ret = avfilter_graph_config(graph, NULL);if (ret < 0)goto end;av_buffersink_set_frame_size(buffersink_ctx, output_audio_encode_ctx->frame_size);end://释放对应的输入输出avfilter_inout_free(&inputs);avfilter_inout_free(&outputs);return ret;
}//输出变声之后的数据帧
static int output_frame(AVFrame *frame)
{int code;int ret = avcodec_send_frame(output_audio_encode_ctx, frame);if (ret < 0){printf("Error sending a frame for encoding\n");}while (1) {AVPacket outPacket{ nullptr };av_init_packet(&outPacket);ret = avcodec_receive_packet(output_audio_encode_ctx, &outPacket);if (ret < 0) {break;}av_packet_rescale_ts(&outPacket, output_audio_encode_ctx->time_base, output_format_ctx->streams[audio_stream_index]->time_base);outPacket.stream_index = audio_stream_index;ret = av_interleaved_write_frame(output_format_ctx, &outPacket);if (ret < 0){break;}}return ret;
}int main(int argc, char* argv[])
{if (argc != 3){printf("usage:%1 input filepath %2 outputfilepath");return -1;}//输入文件地址、输出文件地址string fileInput = std::string(argv[1]);string fileOutput = std::string(argv[2]);//打开输入文件,获取音频流和视频流信息int ret = avformat_open_input(&input_format_ctx, fileInput.c_str(), NULL, NULL);if (ret < 0){return ret;}ret = avformat_find_stream_info(input_format_ctx, NULL);if (ret < 0){return ret;}//查找音视频流的索引for (int index = 0; index < input_format_ctx->nb_streams; ++index){if (index == AVMEDIA_TYPE_AUDIO){audio_stream_index = index;}else if (index == AVMEDIA_TYPE_VIDEO){video_stream_index = index;}}audio_graph = avfilter_graph_alloc();//初始化输出if (open_output_file((char *)fileOutput.c_str()) < 0){cout << "Open file Output failed!" << endl;avfilter_graph_free(&audio_graph);return 0;}AVFrame *inAudioFrame = av_frame_alloc();AVFrame *outAudioFrame = av_frame_alloc();outAudioFrame->format = output_audio_encode_ctx->sample_fmt;outAudioFrame->sample_rate = output_audio_encode_ctx->sample_rate;outAudioFrame->channel_layout = output_audio_encode_ctx->channel_layout;outAudioFrame->nb_samples = output_audio_encode_ctx->frame_size;ret = av_frame_get_buffer(outAudioFrame, 0);//滤镜描述char description[512];double ratio = 0.7;int new_sample_rate = output_audio_encode_ctx->sample_rate* ratio;double tempo = 1.0 / ratio;snprintf(description, sizeof(description),"[in]asetrate=%d[res];[res]aresample=%d[res1];[res1]atempo=%0.3f[out]",new_sample_rate,output_audio_encode_ctx->sample_rate,tempo);char ch_layout[64];av_get_channel_layout_string(ch_layout, sizeof(ch_layout),av_get_channel_layout_nb_channels(output_audio_encode_ctx->channel_layout), output_audio_encode_ctx->channel_layout);//初始化滤镜ret = init_change_tone_filter(audio_graph, description);if (ret < 0){avfilter_graph_free(&audio_graph);return -1;}printf("%s",avfilter_graph_dump(audio_graph, NULL));int64_t audio_pts = 0;while (true){int ret = av_read_frame(input_format_ctx, &packet);if (ret == AVERROR_EOF){break;}else if(ret < 0){return -1;}if (packet.stream_index == video_stream_index){packet.pts = av_rescale_q_rnd(packet.pts, input_format_ctx->streams[video_stream_index]->time_base, output_format_ctx->streams[video_stream_index]->time_base, (AVRounding)(AV_ROUND_INF | AV_ROUND_PASS_MINMAX));packet.dts = av_rescale_q_rnd(packet.dts, input_format_ctx->streams[video_stream_index]->time_base, output_format_ctx->streams[video_stream_index]->time_base, (AVRounding)(AV_ROUND_INF | AV_ROUND_PASS_MINMAX));av_write_frame(output_format_ctx, &packet);}//音频帧通过滤镜处理之后编码输出else if (packet.stream_index == audio_stream_index){int ret = avcodec_send_packet(audio_decode_ctx, &packet);if (ret != 0){printf("unable to send packet");}ret = avcodec_receive_frame(audio_decode_ctx, inAudioFrame);if (ret == 0){ret = av_buffersrc_add_frame_flags(buffersrc_ctx, inAudioFrame, AV_BUFFERSRC_FLAG_KEEP_REF);av_frame_unref(inAudioFrame);if (ret < 0){printf("unable to add audio frame");}while (1){outAudioFrame->nb_samples = output_audio_encode_ctx->frame_size;ret = av_buffersink_get_samples(buffersink_ctx, outAudioFrame, outAudioFrame->nb_samples);if (ret == 0){outAudioFrame->pts = audio_pts;audio_pts += outAudioFrame->nb_samples;ret = output_frame(outAudioFrame);}else{break;}av_frame_unref(outAudioFrame);}}}av_packet_unref(&packet);}av_write_trailer(output_format_ctx);
End://结束的时候清理资源avfilter_graph_free(&audio_graph);avformat_close_input(&input_format_ctx);avcodec_free_context(&audio_decode_ctx);avcodec_free_context(&output_audio_encode_ctx);return 0;
}