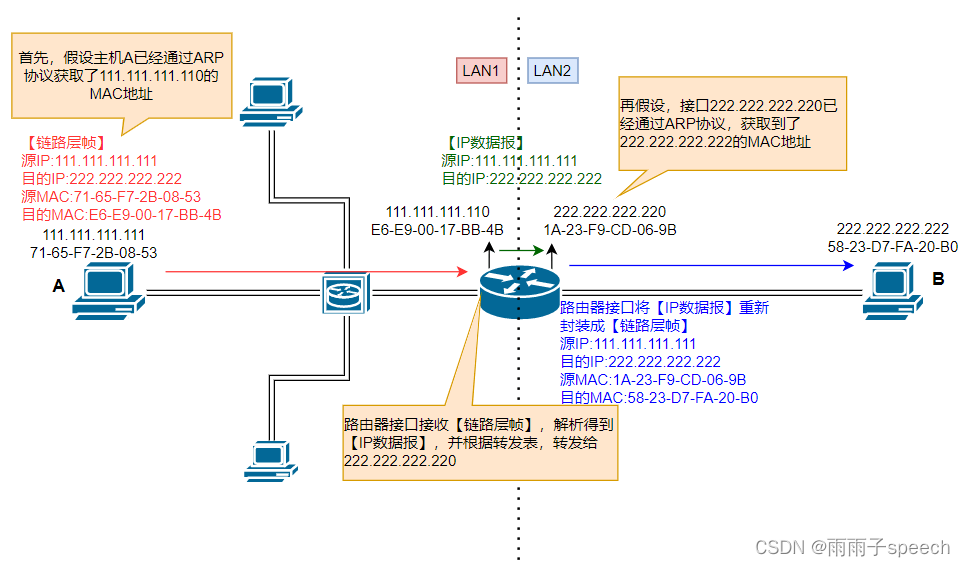
系列文章目录
C plus plus 面向对象编程
文章目录
- 系列文章目录
- 前言
- 一、编程语言概述
- 1.1低级语言概述
- 1.2高级语言概述
- 1.3面向过程、面向对象概述
- 二、面向过程编程的特性
- 三、面向对象编程的特性
- 四、类和对象
- 4.1 类的概述
- 4.2 类的声明与定义
- 4.3 类的实现
- 4.4 对象的生命
- 五、构造函数
- 5.1构造函数概述
- 5.2 复制构造函数
- 5.2 析构函数
- 六、类成员
- 6.1 访问类成员
- 6.2 内联成员函数
- 6.3 静态类成员
- 6.4 隐藏的this指针
- 6.5 嵌套类
- 6.6 局部类
- 七、友元
- 7.1 友元概述
- 7.1 友元类
- 7.1 友元方法
- 八、命名空间
- 8.1使用命名空间
- 8.2 定义命名空间
- 8.3 定义嵌套的命名空间
- 8.4 定义未命名的命名空间
- 九、总结
前言
编程语言分为高级语言和低级语言两大类,大致分为3种结构:面向机器,面向过程和面向对象。
一、编程语言概述
1.1低级语言概述
机器语言:
计算机硬件只能识别“断开”和“闭合”两种物理状态,也就是0和1。使用机器指令效率最高,因为无需对指令进行翻译。但是机器语言对人类不友好,一大串0和1,很难识别和记忆,且容易出错。
汇编语言:
采用人类容易记忆和识别的助记符来代表一些0和1的指令,比如AND代表加法。
用助记符(Mnemonics)代替机器指令的操操作码,用地址符号(Symbol)或标号(Label)代替指令或操作数的地址。在不同的设备中,汇编语言对应着不同的机器语言指令集,通过汇编过程转换成机器指令。普遍地说,特定的汇编语言和特定的机器语言指令集是一一对应的,不同平台之间不可直接移植。
MOVAX,2MOV BX,3ADD AX,BX
越是低级的语言对机器越是友好,越是符合机器的思考方式,因此执行效率高。
越是高级的语言对人类越是友好,越是符合人类的思考方式,因此开发效率高。
1.2高级语言概述
高级语言的可移植性是基于编译或者解释这个过程,对人类友好的高级语言只有经过处理才能被操作系统识别并加载到计算机硬件上最终执行。
高级语言的编译和解释都是面向操作系统而言,并非面对计算机硬件。
编译型语言
编译型语言:程序在执行之前需要一个专门的编译过程,把程序编译成 为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++、Pascal、Delphi等.
编译就是把一个事先编好的叫做“编译程序”(编译器)的软件安装在计算机内,当需要执行高级语言程序时,编译程序就把整个“高级语言的源程序”翻译成“机器语言的目标程序”。
解释型语言
而相对的,解释性语言编写的程序不进行预先编译,以文本方式存储程序代码。在发布程序时,看起来省了道编译工序。但是,在运行程序的时候,解释性语言必须先解释再运行。
解释型语言进入计算机后,解释程序一边扫描一边解释,逐句输入逐句翻译,计算机一行一行执行,并不产生目标程序。
比如JAVA就是一种解释型高级语言。
编译型语言由于程序执行速度快,同等条件下对系统要求较低,因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++、Pascal/Object Pascal(Delphi)等都是编译语言,而一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如Java、JavaScript、BASIC、Perl、Python、Ruby、MATLAB 等等。
1.3面向过程、面向对象概述
面向过程(Procedure Oriented 简称PO :如C语言):
从名字可以看出它是注重过程的。 当解决一个问题的时候,面向过程会把事情拆分成: 一个个函数和数据(用于方法的参数) 。 然后按照一定的顺序,执行完这些方法(每个方法看作一个过程),等方法执行完了,事情就搞定了。 面向过程的高级语言有C,Fortran语言。
面向对象(Object Oriented简称OO :如C++,JAVA等语言):
看名字它是注重对象的。 当解决一个问题的时候,面向对象会把事物抽象成对象的概念,就是说这个问题里面有哪些对象,然后给对象赋一些属性和方法,然后让每个对象去执行自己的方法,问题得到解决。面向对象的高级语言有C++,Java,Python, C#, EIFFEL,Simula 67等。
面向过程和面向对象并用的语言: PHP。当然面向对象是大势所趋。
二、面向过程编程的特性
面向过程编程的主要思想是先做什么后做什么,在一个过程中实现特定功能。一个大的实现过程还可以分成多个模块,各个模块可以按功能进行划分,然后组合在一起实现特定功能。在面向过程编程中,程序模块可以是一个函数,也可以是整个源文件。
面向过程编程主要以数据为中心,传统的面向过程的功能分解法属于结构化分析方法。分析者将对象系统的现实世界看作一个大的处理系统,然后将其分解为若干个子处理过程,解决系统的总体控制问题。在分析过程中,用数据描述各子处理过程之间的联系,整理各子处理过程的执行顺序。面向过程编程一般流程如下:
现实世界→面向过程建模(流程图,变量,函数)→面向过程语言→执行求解面向过程编程的稳定性、可修改性和可重用性都比较差。
(1)软件重用性差
重用性是指同一事物不经修改或稍加修改就可多次重复使用的性质。软件重用性是软件工程追求的目标之一。处理不同的过程都有不同的结构,当过程改变时,结构也需要改变,前期开发的代码无法得到充分的再利用。
(2)软件可维护性差
软件工程强调软件的可维护性,强调文档资料的重要性,规定最终的软件产品应该由完整、一致的配置成分组成。在软件开发过程中,始终强调软件的可读性、可修改性和可测试性是软件的重要的质量指标。面向过程编程由于软件的重用性差,造成维护时其费用和成本也很高,而且大量修改的代码存在着许多未知的漏洞。
(3)开发出的软件不能满足用户需要
大型软件系统一般涉及各种不同领域的知识,面向过程编程往往描述软件的各个最低层的,针对不同领域设计不同的结构及处理机制,当用户需求发生变化时,就需要修改最底层的结构。当处理用户需求变化较大时,过程编程将无法修改,可能导致软件的重新开发。
面向过程编程的特性: 面向过程编程有费解的数据结构,复杂的组合逻辑,详细的过程和数据之间的关系,高深的算法,面向过程开发的程序可以描述成算法加数据结构。面向过程开发是分析过程与数据之间的边界在哪里,进而解决问题。
三、面向对象编程的特性
面向对象中的对象也可以是一个抽象的事物,可以从类似的事物中抽象出一个对象,例如圆形、正方形、三角形,可以抽象得出的对象是简单图形,简单图形就是一个对象,它有自己的属性和行为,图形中边的个数是它的属性,图形的面积也是它的属性,输出图形的面积就是它的行为。
面向对象有三大特点,即封装、继承和多态。
(1)封装
封装有两个作用,一个是将不同的小对象封装成一个大对象,另一个是把一部分内部属性和功能对外界屏蔽。例如一辆汽车,它是一个大对象,它由发动机、底盘、车身和轮子等这些小对象组成。在设计时可以先对这些小对象进行设计,然后小对象之间通过相互联系确定各自大小等方面的属性,最后就可以安装成一辆汽车。
(2)继承
继承是和类密切相关的概念。继承性是子类自动共享父类数据结构和方法的机制,这是类之间的一种关系。在定义和实现一个类时,可以在一个已经存在的类的基础之上进行,把这个已经存在的类所定义的内容作为自己的内容,并加入若干新的内容。
在类层次中,子类只继承一个父类的数据结构和方法,称为单重继承,子类继承了多个父类的数据结构和方法,则称为多重继承。
在软件开发中,类的继承性使所建立的软件具有开放性、可扩充性,这是信息组织与分类的行之有效的方法,它简化了对象、类的创建工作量,增加了代码的可重性。
继承性是面向对象程序设计语言不同于其他语言的最重要的特点,是其他语言所没有的。采用继承性,使公共的特性能够共享,提高了软件的重用性。
(3)多态
多态性是指相同的行为可作用于多种类型的对象上并获得不同的结果。不同的对象,收到同一消息可以产生不同的结果,这种现象称为多态性。多态性允许每个对象以适合自身的方式去响应共同的消息。
面向对象技术充分体现了分解、抽象、模块化、信息隐藏等思想,有效提高软件生产率,缩短软件开发时间、提高软件质量,是控制复杂度的有效途径。
面向对象不仅适合普通人员,也适合经理人员。降低维护开销的技术可以释放管理者的资源,将其投入到待处理的应用中。在经理们看来,面向对象不是纯技术的,它既能给企业的组织也能给经理的工作带来变化。
当一个企业采纳了面向对象,其组织将发生变化。类的重用需要类库类和类库管理人员,每个程序员都要加入到两个组中的一个:一个是设计和编写新类组,另一个是应用类创建新应用程序组。面向对象不太强调编程,需求分析相对地将变得更加重要。
面向对象编程主要有代码容易修改、代码复用性高、满足用户需求3个特点。
(1) 代码容易修改
面向对象编程的代码都是封装在类里面,如果类的某个属性发生变化,只需要修改类中成员函数的实现即可,其他的程序函数不发生改变。如果类中属性变化比较大,则使用继承的方法重新派生新类。
(2) 代码复用性高
面向对象编程的类都是具有特定功能的封装,需要使用类中特定的功能,只需要声明该类并调用其成员函数即可。如果需要的功能在不同类,还可以进行多重继承,将不同类的成员封装到一个类中。功能的实现可以像积木一样随意组合,大大提高了代码的复用性。
(3) 满足用户需求
由于面向对象编程的代码复用性高,用户的要求发生变化时,只需要修改发生变化的类。如果用户的要求变化比较大时,就对类进行重新组装,将变化大的类重新开发,功能没有发生变化的类可以直接拿来使用。面向对象编程可以及时地响应用户需求的变化。
面向对象编程的特性: 面向对象则是将编程思维设计成符号人的思维逻辑。
面向对象程序设计者的任务包括两个方面:一是设计所需的各种类和对象,即决定把哪些数据和操作封装在一起;二是考虑怎样向有关对象发送消息,以完成所需的任务。这时它如同一个总调度,不断地向各个对象发出消息,让这些对象活动起来(或者说激活这些对象),完成自己职责范围内的工作。
各个对象的操作完成了,整体任务也就完成了。显然,对一个大型任务来说,面向对象程序设计方法是十分有效的,它能大大降低程序设计人员的工作难度,减少出错几率。
面向对象开发的程序可以描述成 “对象+消息”。面向对象编程一般流程如下:
现实世界->面向对象建模(类图,对象,方法)->面向对象语言->执行求解
四、类和对象
C++既可以开发面向过程的应用程序,也可以开发面向对象的应用程序。类是对象的实现,面向对象中的类是抽象概念,而类是程序开始过程中定义的一个对象,用类定义的对象可以是现实生活中的真实对象,也可以是从现实生活中抽象的对象。
4.1 类的概述
面向对象中的对象需要通过定义类来声明,对象一词是一种形象的说法,在编写代码过程中则是通过定义一个类来实现。
C++类不同于汉语中的类、分类、类型,它是一个特殊的概念,可以是对统一类型事物进行抽象处理,也可以是一个层次结构中的不同层次节点。类是一个新的数据类型,它和结构体有些相似,是由不同数据类型组成的集合体,但类要比结构体增加了操作数据的行为,这个行为就是函数。
4.2 类的声明与定义
类是用户自己指定的类型,如果程序中要用到类这种类型,就必须自己根据需要进行声明,或者使用别人设计好的类。下面来看一下如何设计一个类。
类的声明格式如下:
class 类名标识符
{
public:
数据成员的声明;
成员函数的声明;
private:
数据成员的声明;
成员函数的声明;
protected:
数据成员的声明;
成员函数的声明;
}
类的声明格式的说明如下:
- class 是定义类结构体的关键字,大括号内被称为类体或类空间。
- 类名标识符指定的就是类名,类名就是一个新的数据类型,通过类名可以声明对象。
- 类的成员有函数和数据两种类型。
- 大括号内是定义和声明类成员的地方,关键字 public 、private 、protected 是类成员访问的修饰符。
类中的数据成员的类型可以是任意的,包含整型、浮点型、字符型、数组、指针和引用等,也可以是对象。另一个类的对象可以作为该类的成员,但是自身类的对象不可以作为该类的成员,而自身类的指针或引用则可以作为该类的成员。
注意:定义类结构体和定义结构体时大括号后要有分号。
4.3 类的实现
关于类的实现有两点说明:
(1) 类的数据成员需要初始化,成员函数还要添加实现代码。类的数据成员不可以在类的声明中初始化。
(2) 空类是C++中最简答的类,在需要时再定义类成员及实现。
定义类的两种方法:
(1) 第一种方法是将类的成员函数都定义再类的体内。
(2) 第二种方法,也可以将类体内的成员函数的实现放在类体外,但如果类成员定义在类体外,需要用到域运算符”::”,放在类体内和类体外的效果是一样的。
C++语言可以实现将函数的声明和函数的定义放在不同的文件内,一般在头文件放入函数的声明,在实现文件放入函数的实现。同样可以将类的定义放在头文件中,将类成员函数的实现放在实现文件内。
4.4 对象的生命
定义一个新类后,就可以通过类名来声明一个对象。声明的形式如下:
类名 对象名表
类名是定义好的新类的标识符,对象名表中是一个或多个对象的名称,如果声明的是多个对象就用逗号运算符分隔。
例如声明一个对象如下:
CPerson p;
CPerson p1,p2,p3;
声明完对象就是对象的引用了,对象的引用有两种方式,一种是成员引用方式,一种是对象指针方式。
(1) 成员引用方式
对象名.成员名
这里 “ . “ 是一个运算符,该运算符的功能是表示对象的成员。
成员函数引用的表示如下:
对象名.成员名(参数表)
(2) 对象指针方式
对象声明形式的对象名表,除了是用逗号运算符分隔的多个对象名外,还可以是对象名数组。对象名指针和引用的对象名。
声明一个对象指针:
CPerson ✳p;
但要想使用对象的成员,需要“->”运算符,它是表示成员的运算符,与” . ” 运算符的意义相同。“->“用来表示对象指针所指的成员,对象指针就是指向对象的指针,例如:
CPerson ✳p;
p->m_ilndex;
下面的对象数据成员的两种表示形式是等价的:
对象指针名->成员名(参数表)
与
(*对象指针名).成员名(参数表)
五、构造函数
5.1构造函数概述
在类的实例进入其作用域时,也就是建立一个对象,构造函数就会被调用,那么构造函数的作:当建立一个对象时,常常需要做某些初始化的工作,例如对数据成员进行赋值设置类的属性,而这些操作刚好放在构造函数中完成。
其构造方法如下:
class CPerson()
{public:CPerson(); //构造函数int m_ilndex;int getIndex();
}
//构造函数
CPerson::CPerson()
{m_ilndex = 10;
}CPerson 是默认构造函数,如果不显式的写上函数的声明也可以。
构造函数是可以有参数的,修改上面的代码,使其构造函数待有参数,例如:
class CPerson
{public:CPerson(int ilndex); //构造函数int m_ildex;int setIndex(int ilndex);
}
//构造函数
CPerson::CPerson(int ilndex)
{m_ilndex = ilndex;
}使用构造函数进行初始化操作
#include <iostream>
using namespace std;
//定义 CPerson类class CPerson
{public:CPerson();CPerson(int ilndex,short shAge,double Salary);int m_ilndex;short m_shAge;double m_Salary;int getlndex();short getAge();double getSalary();
};
//在默认构造函数中初始化CPerson::CPerson()
{m_ilndex = 0;m_shAge = 10;m_Salary = 1000;
}CPerson::CPerson(int ilndex,short shAge,double Salary)
{m_ilndex = ilndex;m_shAge = shAge;m_Salary = Salary;
}
int CPerson::getlndex()
{return m_ilndex;
}
int main()
{CPerson p1;cout<<"m_ilndex is:"<<p1.getlndex()<<endl;CPerson p2(20,30,40);cout<<"m_ilndex is:"<<p2.getlndex()<<endl;return 0;
}程序声明了两个对象p1和p2,p1使用默认构造函数初始化成员变量,p2使用带参数的构造函数初始化,所以在调用同一个类成员函数getIndex时输出结果不同。其运行结果如下图所示:

5.2 复制构造函数
在开发程序时可能需要保持对象的副本,以便在后面执行的过程中恢复对象的状态。可以使用复制构造函数来实现。复制构造函数就是函数的参数是一个已经初始化的类对象。
使用复制构造函数实例如下:
#include <iostream>
using namespace std;class CPerson
{public:CPerson(); CPerson(int ilndex,short shAge,double Salary);//构造函数CPerson(CPerson & copyPerson); //复制构造函数int m_ilndex;short m_shAge;double m_Salary;int getlndex();short getAge();double getSalary();
};
//构造函数
CPerson::CPerson(int ilndex,short shAge,double Salary)
{m_ilndex = ilndex;m_shAge = shAge;m_Salary = Salary;
}
//复制构造函数
CPerson::CPerson(CPerson & copyPerson)
{m_ilndex = copyPerson.m_ilndex;m_shAge = copyPerson.m_shAge;m_Salary = copyPerson.m_Salary;
}
CPerson::CPerson()
{}short CPerson::getAge()
{return m_shAge;
}int CPerson::getlndex()
{return m_ilndex;
}double CPerson::getSalary()
{return m_Salary;
}int main()
{CPerson p1(20,30,100); //打印初始化的构造函数cout<<"m_ilndex of p1 is:"<<p1.getlndex()<<endl;cout<<"m_shAge of p1 is:"<<p1.getAge()<<endl;cout<<"m_Salary of p1 is:"<<p1.getSalary()<<endl;CPerson p2; //打印未初始化的构造函数cout<<"m_ilndex of p2 is:"<<p2.getlndex()<<endl;cout<<"m_shAge of p2 is:"<<p2.getAge()<<endl;cout<<"m_Salary of p2 is:"<<p2.getSalary()<<endl;CPerson p3(p1); //打印复制的已经初始化的构造函数cout<<"m_ilndex of p3 is:"<<p3.getlndex()<<endl;cout<<"m_shAge of p3 is:"<<p3.getAge()<<endl;cout<<"m_Salary of p3 is:"<<p3.getSalary()<<endl;return 0;
}程序中先用带参数的构造函数声明对象p1,然后通过复制构造函数声明对象p3,因为p1已经是初始化完成的类对象,可以作为复制构造函数的参数。
5.2 析构函数
构造函数和析构函数是类体定义中比较特殊的两个函数,因为它们两个都没有返回值,而且构造函数名标识符和类名标识符相同,析构函数名标识符就是在类名标识符前面加“~“符号。
构造函数主要是用来在对象创建时,给对象中的一些数据成员赋值,主要目的就是来初始化对象。析构函数的功能是用来释放一个对象的,在对象删除前,用它来做一些清理工作,它与构造函数的功能正好相反。
析构函数实例如下:
#include <iostream>
#include <string.h>
using namespace std;class CPerson
{public:CPerson();~CPerson();char* m_Message;void ShowStartMessage();void ShowFrameMessage(); };CPerson::CPerson()
{m_Message = new char[2048];
}
void CPerson::ShowStartMessage()
{strcpy(m_Message,"Welcome to MR");cout<<m_Message<<endl;
}
void CPerson::ShowFrameMessage()
{strcpy(m_Message,"***************");cout<<m_Message<<endl;
}
CPerson::~CPerson()
{delete[] m_Message;
}
int main()
{CPerson p;p.ShowFrameMessage();p.ShowStartMessage();p.ShowFrameMessage();return 0;
}程序在构造函数中使用new为成员m_Message分配空间,在析构函数中使用delete释放由new分配的空间。成员m_Message为字符指针,在ShowStartMessage成员函数中输出字符指针所指向的内容。
使用析构函数的注意事项如下:
- 一个类中只可能定义一个析构函数。
- 析构函数不能重载。
- 构造函数和析构函数不能使用return 语句返回值,不用加上关键字void。
构造函数和析构函数的调用环境:
- 自动变量的作用域是某个模块,当此模块被激活时,自动变量调用构造函数,当退出此模块时,会调用析构函数。
- 全局变量在进入main函数之前会调用构造函数,在程序终止时会调用析构函数
- 动态分配的对象在使用new为对象分配内存时会调用构造函数;使用delete 删除对象时会调用析构函数。
- 临时变量是为支持计算,由编译器自动产生的。临时变量的生存期的开始和结尾调用构造函数和析构函数。
六、类成员
6.1 访问类成员
类的三大特点之一就是具有封装性,封装在类里面的数据可以设置成对外可见或不可见。通过关键字 public 、private 、protected 可以设置类中数据成员对外是否可见,也就是其他类是否可以访问该数据成员。
关键字 public 、private 、protected 说明类的成员是共用的、私用的,还是保护的。这3个关键字将类划分为3个区域,在public 区域的类成员可以在类作用域外被访问,而privat区域和protected 区域的类成员只能在类作用域内被访问。
这3种类成员的属性如下:
- public 属性的成员对外可见,对内可见。
- private 属性的成员对外不可见,对内可见。
- protected 属性的成员对外不可见,对内可见,且派生类是可见的。
如果在类定义时没有加任何关键字,默认状态类成员都在private区域。
6.2 内联成员函数
在定义函数时,可以使用inline 关键字将函数定义为内联函数。在定义类的成员函数时,也可以使用inline 关键字将成员函数定义为内联成员函数。其实,对于成员函数来说,如果其定义是在类体中,即使没有使用inline 关键字,该成员函数也被认为是内联成员函数。
例如:
class CUser //定义一个CUser类
{
private:char m_Username[128]; //定义数据成员char m_Password[128];
public:inline char* GetUsername()const; //定义一个内联成员函数
};
char* CUser::GetUsername()const //实现内联成员函数
{return (char*)m_Username;
}
程序中,使用inline 关键字将类中的成员函数设置为内联成员函数。此外,也可以在类成员函数的实现部分使用inline 关键字标识函数为内联成员函数。
例如:
class CUser //定义一个CUser类
{
private:char m_Username[128]; //定义数据成员char m_Password[128];
public:char* GetUsername()const; //定义一个内联成员函数
};
inline char* CUser::GetUsername()const //实现内联成员函数
{return (char*)m_Username;
}
程序中的代码演示了在何处使用关键字inline。对于内联函数来说,程序会在函数调用的地方直接插入函数代码,如果函数体语句较多,则会导致程序代码膨胀。如果将类的析构函数定义为内联函数,可能会导致潜在的代码膨胀。
6.3 静态类成员
如果将类成员定义为静态类成员,则允许使用类名直接访问。静态类成员是在类成员定义前使用static 关键字标识。例如:
Class CBook
{
public:static unsigned int m_Price; //定义一个静态数据成员
}
定义静态数据成员时,通常需要在类体外部对静态数据成员进行初始化。例如:
unsigned int CBook::m_Price = 10; //初始化静态数据成员
对于静态成员来说,不仅可以通过对象访问,还可以直接使用类名访问。例如:
int main(int argc,char* argv[])
{CBook book; //定义一个CBook 类对象bookcout<<CBook::m_Price<<endl; //通过类名访问静态成员cout<<book.m_Price<<endl; //通过对象访问静态成员return 0;
}
在一个类中,静态数据成员是被所有的类对象所共享的,这就意味着无论定义多少个类对象,类的静态数据成员只有一份,同时,如果某一个对象修改了静态数据成员,其他对象静态数据成员(实际上是通一个静态数据成员)也将改变。
对于静态数据成员,还需要注意以下几点。
- 静态数据成员可以是当前类的类型,而其他数据成员只能是当前类的指针或应用类型。
在定义类成员时,对于静态数据成员,其类型可以是当前类的类型,而非静态数据成员不可以除非数据成员的类型为当前类的指针或引用类型。例如:
class CBook
{public:static unsigned int m_Price; CBook m_Book; //非法的定义,不允许在该类中定义所属类的对象
static CBook m_VCbook; //正确,静态数据成员允许定义类的所属类对象CBook *m_pBook; //正确,允许定义类的所属类型的指针类型对象
}
- 静态数据成员可以作为成员函数的默认参数。
在定义类的成员函数时,可以为成员函数指定默认参数,其参数的默认值也可以是类的静态数据成员,但是不同的数据成员则不能作为成员函数的默认参数。例如:
class CBook //定义CBook类
{
public:static unsigned int m_Price; //定义一个静态数据成员int m_Pages; //定义一个普通数据成员void Outputlnfo(int data = m_Price) //定义一个函数,以静态数据成员作为默认参数{cout<<data<<endl; //输出信息}void OutputPage(int page = m_Pages) //错误的定义,类的普通数据成员不能作为默认参数{cout<<page<<endl; //输出信息}
};- 定义类的静态成员函数与定义普通成员函数类似,只是在成员函数前添加 static 关键字。例如:
static void OutputInfo(); //定义类的静态成员函数
类的静态成员函数只能访问类的静态数据成员,而不能访问普通的数据成员。例如:
class CBook //定义一个类CBook
{
public:static unsigned int m_Price; //定义一个静态数据成员int m_Pages; //定义一个普通数据成员static void Outputlnfo() //定义一个静态成员数据{cout<<m_Price<<endl; //正确的访问cout<<m_Pages<<endl; //非法的访问,不能访问非静态数据成员}
}
在上述代码中,语句“cout<<m_Pages<<endl;” 是错误的,因为m_Pages 是非静态数据成员,不能再静态成员函数中访问。
此外,对于静态成员函数不能定义为 const 成员函数,即静态成员函数末尾不能使用const关键字。下面的静态成员函数的定义是非法的。
static void Outputlnfo()const; //错误的定义,静态成员函数末尾不能使用const 关键字
在定义静态数据成员函数时,如果函数的实现代码处于类体之外,则再函数的实现部分不能再标识 static 关键字。例如:
static void CBook::Outputlnfo() //错误的函数定义,不能使用static关键字
{Cout<<m_Price<<endl; //输出信息
}
上述代码如果去掉static关键字则是正确的。例如:
void CBook::Outputlnfo() //错误的函数定义,不能使用static关键字
{Cout<<m_Price<<endl; //输出信息
}
6.4 隐藏的this指针
对于类的非静态成员,每一个对象都有自己的一份拷贝,即每个对象都有自己的数据成员,不过成员函数却是每个对象共享的。那么调用共享的成员函数是通过类中隐藏的this指针找到自己的数据成员。
例如,每一个对象都有自己的一份拷贝。
#include <iostream>
#include <string.h>
using namespace std;class CBook //定义一个CBook类
{
public:int m_Pages; //定义一个数据成员void OutputPages() //定义一个成员函数{cout<<m_Pages<<endl; //输出信息}
};
int main()
{CBook vbBook,vcBook; //定义两个CBook类对象vbBook.m_Pages = 512; //设置vbBook对象的成员数据vcBook.m_Pages = 570; //设置vcBook对象的成员数据vbBook.OutputPages(); //调用OutputPages方法输出vbBook对象的数据成员vcBook.OutputPages(); //调用OutputPages方法输出vcBook对象的数据成员return 0;
}
程序运行结果如图所示:

在每个类的成员函数(非静态成员函数)中都隐含包含一个this指针,指向被调用对象的指针,其类型为当前类类型的指针类型,在const 方法中,为当前类类型的const指针类型。实际上,编译器为了实现this指针,在成员函数中自动添加了this指针对数据成员的方法。此外,为了将this指针指向当前调用对象,并在成员函数中能够使用,在每个成员函数中都隐含包含一个this指针作为参数,并在函数调用时将对象自身的地址隐含作为实际参数传递。例如,以OutputPages(CBook* this) 成员函数为例,编译器将其定义为:
void OutputPages()
{cout<<this->m_Pages<<endl; //使用this指针访问数据成员
}
实际上,编译器为了实现this指针,在成员函数中自动添加了this指针对数据成员的方法,类似于上面的OutputPages方法。此外,为了将this指针指向当前调用对象,并在成员函数中能够使用,在每个成员函数中都隐含包含一个this指针作为函数参数,并在函数调用时将对象自身的地址隐含作为实际参数传递。例如,以OutputPages成员函数为例,编译器将其定义为:
void OutputPages(CBook* this) //隐含添加this指针
{cout<<this->m_Pages<<endl;
}
在对象调用成员函数时,传递对象的地址到成员函数中。以“vc.OutputPages();” 语句为例,编译器将其解释为“vbBook.OutputPages(&vbBook);”,这就使得this指针合法,并能够在成员函数中使用。
6.5 嵌套类
C++语言允许在一个类中定义另一个类,这被称之为嵌套类。
对于内部的嵌套类来说,只允许其在外围的类域中使用,在其他类域或者作用域中是不可见的。
例如下面的代码在定义Clist类时,在内部又定义一个嵌套类CNode。
class CList //定义CList 类
{
public: //嵌套类为公有的class CNode //定义嵌套类CNode{friend class CList; //将CList 类作为自己的友元类private:int m_Tag; //定义私有成员public:char m_Nmae[20]; //定义共用数据成员}; //CNode 类定义结束
public:CNode m_Node; //定义一个CNode类型数据成员void SetNodeName(const char *pchData) //定义成员函数{if(pchData != NULL) //判读指针是否为空{strcpy(m_Node.m_Nmae,pchData); //访问CNode类的共用数据}}void SetNodeTag(int tag) //定义成员函数{m_Node.m_Tag = tag; //访问CNode类的私有数据}}上述代码在嵌套CNode中定义了一个私有成员m_Tag,定义了一个公有成员m_Name,对于外围类CList来说,通常它不能够访问
嵌套类的私有成员,虽然嵌套类是在其内部定义的。但是,上述代码在定义CNode类时将CList类作为自己的友元类,这使得CList类能够访问CNode类的私有成员。
对于内部嵌套类来说,只允许其在外围的类域中使用,在其他类域或者作用域中是不可见的。例如下面的定义是非法的。
int main(int argc,char* argv[])
{CNode node; //错误的定义,不能访问CNode类return 0;
}
上述代码在main函数的作用域中定义了一个CNode对象,导致CNode没有被声明的错误。对于main函数来说。嵌套类CNode是不可见的,但是可以通过使用外围的类域作为
限定符来定义CNode对象。如下的定义将是合法的。
int main(int argc ,char* argv)
{CList::CNode node; //合法的定义return 0;
}
上述代码通过使用外围类域作为限定符访问到了CNode类。但是这样做通常是不合理的。也是有限制条件的。因为既然定义了嵌套类。通常都不允许在外界访问,这违背了使用嵌套类的原则。
其次,在定义嵌套类时,如果将其定义为私有的域或受保护的,即使使用外围类域作为限定符,外界也无法访问嵌套类。
6.6 局部类
类的定义可以放在头文件中,也可以放在源文件中。还有一种情况,类的定义也可以放置在函数中,这样的类被称之为局部类。
例如,定义一个局部类CBook
void LocalClass() //定义一个函数
{class CBook //定义一个局部类CBook{private:int m_Pages; //定义一个私有数据成员public:void SetPages(int page){if(m_Pages != page){m_Pages = page; //为数据成员赋值}}int GetPages(){return m_Pages; //获取数据成员信息}}CBook book; //定义一个CBook对象book.SetPages(300); //调用SetPages方法cout<<book.GetPages()<<endl; //输出信息}上述代码在LocalClass函数中定义了一个类CBook,该类被称为局部类,对于局部类CBook,在函数之外是不能够被访问的,因为局部类被封装在了函数的局部作用域中。
七、友元
7.1 友元概述
在讲述类的内容时说明了隐藏数据成员的好处,但是有些时候,类会允许一些特殊的函数直接读写其私有数据成员。
使用friend 关键字可以让特定的函数或者别的类的所有成员函数对私有数据成员进行读写。这既可以保持数据的私有性,又能够使特定的类或函数直接访问私有数据。
有时候,普通函数需要直接访问一个类的保护或私有数据成员。如果没有友元机制,则只能将类的数据成员声明为公共的,从而任何函数都可以无约束地访问它。
普通函数需要直接访问类的保护或私有数据成员的原因主要是为提高效率。
下面来介绍使用友元函数的情况。例如:
#include <iostream>
#include <string.h>
using namespace std;class CRectangle
{public:CRectangle(){m_iHeight = 0;m_iWidth = 0;}CRectangle(int iLefTop_x,int iLefTop_y,int iRightBottom_x,int iRightBottom_y){m_iHeight = iRightBottom_y - iLefTop_y;m_iWidth = iRightBottom_x - iLefTop_x;}int getHeight(){return m_iHeight;}int getWidth(){return m_iWidth;}friend int ComputerRectArea(CRectangle & myRect); //声明为友元函数protected:int m_iHeight;int m_iWidth;};int ComputerRectArea(CRectangle & myRect) //友元函数定义
{return myRect.m_iHeight*myRect.m_iWidth;
}int main()
{CRectangle rg(0,0,100,100);cout<<"Result of ComputerRectArea is: " << ComputerRectArea(rg)<<endl;return 0;
}其运行结果如下图所示:

在ComputerRectArea 函数的定义中可以看到使用CRectangle 的对象可以直接引用其中的数据成员,这是因为在CRectangle类中将ComputerRectArea函数声明为友元了。
从中可以看到使用友元保持了CRectangle 类中数据的私有性,起到了隐藏数据成员的好处,又使得待定的类或函数可以直接访问这些隐藏数据成员。
7.1 友元类
对于类的私有方法,只有在该类中允许访问,其他类是不能访问的。但在开发程序时,如果两个类的耦合度比较紧密,能够在一个类中访问另一个类的私有成员 会带来很大的方便。
C++语言提供了友元类和友元方法(或者称为友元函数)来实现访问其他类的私有成员。当用户希望另一个类能够访问当前类的私有成员时,可以在当前类中将另一个类作为自己的友元
类,这样在另一个类中就可以访问当前的私有成员了。例如定义友元类:
class Cltem //定义一个Cltem类
{
private:char m_Name[128]; //定义私有的数据成员void OutputName() //定义私有的成员函数{printf("%s\n",m_Name); //输出 m_Name}public:friend class CList; //将CList 类作为自己的友元类void SetltemName(const char* pchData) //定义共用成员函数,设置m_Name成员{if(pchData != NULL) //判断指针是否为空{strcpy(m_Name,pchData); //赋值字符串}}Cltem() //构造函数{memset(m_Name,0,128); //初始化数据成员m_Name}};
class CList //定义类CList
{private:Cltem m_ltem; //定义私有的数据成员m_ltem
public:void OutputName(); //定义共用成员函数};
void CList::OutputName()
{m_ltem.SetltemName("BeiJing"); //调用Cltem类的共用方法m_ltem.OutputName(); //调用Cltem类的私有方法
}在定义Cltem类时,使用friend 关键字将CList类定义为Cltem类的友元,这样CList类中的所有方法都可以访问Cltem类中的私有成员了。在CList类的OutPutltem
方法中,语句“m_ltem.OutputName()”演示了调用Cltem类私有方法OutputName.
7.1 友元方法
在开发程序时,有时需要控制另一个类对当前类的私有成员的方法。例如,假设需要实现只允许CList类的某个成员访问Cltem类的私有成员,而不允许其他成员函数访问Cltem类的私有数据,便可以通过定义友元函数来实现。在定义Cltem类时,可以将CList类的某个方法定义为友元方法,这样就限制了只有该方法允许访问Cltem类的私有成员。
定义友元方法:
#include <iostream>
#include <string.h>
using namespace std;class Cltem; //前导声明Cltem类
class CList //定义CList类
{private:Cltem *m_pltem; //定义私有数据成员m_pltempublic:CList(); //定义默认构造函数~CList(); //定义析构函数void Outputltem(); //定义Outputltem 成员函数};class Cltem //定义Cltem类
{friend void CList::Outputltem(); //声明友元函数
private:char m_Name[128]; //定义私有数据成员void OutputName(){printf("%s\n",m_Name); //输出数据成员}public:void SetltemName(const char* pchData) //定义共用方法{if(pchData != NULL) //判断指针是否为空{strcpy(m_Name,pchData); //赋值字符串}}Cltem() //构造函数{memset(m_Name,0,128); //初始化数据成员m_Name}
};void CList::Outputltem() //CList类的Outputltem成员函数的实现
{m_pltem->SetltemName("BeiJing"); //调用Cltem类的共用方法m_pltem->OutputName(); //在友元函数中访问Cltem类的私有方法OutputName}CList::CList()
{m_pltem = new Cltem(); //构造m_pltem对象
}
CList::~CList() //CList类的析构函数
{delete m_pltem; //释放m_pltem对象m_pltem = NULL; //将m_pltem对象设置为空
}int main(int argc,char* argv[]) //主函数
{CList list; //定义CList 对象listlist.Outputltem(); //调用CList的Outputltem方法return 0;
}其运行结果如下:

上述代码中,在定义Cltem类时,使用friend关键字将CList类的Outputltem方法设置为友元函数,在CList类的Outputltem方法中访问了Cltem类的私有方法OutputName对于友元函数来说,不仅可以是类的成员函数,还可以是一个全局函数。例如:
#include <iostream>
#include <string.h>
using namespace std;class Cltem //定义Cltem类
{friend void Outputltem(Cltem *pltem); //将全局函数 Outputltem 定义为友元函数
private:char m_Name[128]; //定义私有数据成员void OutputName(){printf("%s\n",m_Name); //输出数据成员}public:void SetltemName(const char* pchData) //定义共用方法{if(pchData != NULL) //判断指针是否为空{strcpy(m_Name,pchData); //赋值字符串}}Cltem() //构造函数{memset(m_Name,0,128); //初始化数据成员m_Name}
};void Outputltem(Cltem *pltem) //定义全局函数
{pltem->SetltemName("BeiJing"); //调用Cltem类的共用方法pltem->OutputName(); //在友元函数中访问Cltem类的私有方法OutputName}int main(int argc,char* argv[]) //主函数
{Cltem ltem; //定义一个Cltem类对象ltemOutputltem(<em); //通过全局函数访问Cltem类的私有方法return 0;
}其编译运行结果如下图所示:

在上面的代码中,定义全局函数OutputItem,在CItem类中使用friend 关键字将OutputItem函数声明为友元函数。而CItem类中OutputName函数的属性是私有的,那么对外是不可见的。因为OutputItem是CItem类的友元函数,所以可以引用类中的私有成员。
八、命名空间
8.1使用命名空间
在一个应用程序的多个文件中可能会存在同名的全局对象,这样会导致应用程序的链接错误,使用命名空间是消除命名冲突的最佳方式。
例如,下面的代码定义了两个命名空间。
namespace MyName1
{int ilnt1=10;int ilnt2=20;
};
namespace MyName2
{int ilnt1=10;int ilnt2=20;
}
在上面的代码中,namespace是关键字,而MyName1和MyName2是定义的两个命名空间名称,大括号中是所属命名空间中的对象。虽然在两个大括号中定义的变量一样的,但是因为在不同的命名空间中,所以避免了标识符的冲突,保证了标识符的唯一性。
总而言之,命名空间就是一个命名的范围区域,程序员在这个特定的范围内创建的所有标识符都是唯一的。
8.2 定义命名空间
命名空间的定义格式为:
namespace 名称
{常量、变量、函数等对象的定义
}
定义命名空间要使用关键字namespace ,例如:
namespace MyName
{int ilnt1=10;int ilnt2=20;
}
在代码中,MyName就是定义的命名空间的名称,在大括号中定义了两个整型变量ilnt1和ilnt2,那么这两个整型变量就是属于MyName这个命名空间范围内的。
引用空间成员的一般形式是:
命名空间名称::成员
例如引用MyName命名空间中的成员:
MyName::ilnt1 = 30;
在实例中,定义命名空间包含变量成员,使其具有唯一性。
#include <iostream>
using namespace std;
namespace MyName1 //定义命名空间
{int iValue = 10;
}
namespace MyName2 //定义命名空间
{int iValue = 20;
}
int iValue=30; //全局变量
int main()
{cout<<MyName1::iValue<<endl; //引用MyName1 命名空间中的变量cout<<MyName2::iValue<<endl; //引用MyName2 命名空间中的变量cout<<iValue<<endl;return 0;
}
其编译运行结果如下图所示:

程序中使用namespace关键字定义两个命名空间,分别是MyName1和MyName2。在两个命名空间范围中,都定义了变量iValue,不过对其赋值分别为10和20。
在源文件中又定义一个全局变量iValue ,赋值为30。在主函数main中分别调用命名空间中的iValue变量和全局变量,将值进行输出显示。MyName1::iValue 表示引用MyName1命名空间中的变量,而MyName2::iValue表示引用MyName2命名空间中的变量,iValue是全局变量。
通过使用命名空间的方法,虽然定义相同名称的变量表示不同的值,但是也可以正确的进行引用显示。
还有另一种引用命名空间中成员的方法,就是使用using namespace语句。一般形式为:
using namespace 命名空间名称;
例如在源程序中包含MyName命名空间:
using namespace MyName;
ilnt = 30;
如果使用using namespace 语句,则在引用空间中的成员时直接使用就可以。例如:
#include <iostream>namespace MyName //定义命名空间
{int iValue = 10; //定义整型变量
};
using namespace std; //使用命名空间std
using namespace MyName; //使用命名空间MyNameint main()
{cout<<iValue<<endl; //输出命名空间中的变量return 0;
}
其结果编译运行结果如下图所示:

在程序中先定义命名空间MyName,之后使用using namespace 语句,使用MyName命名空间,这样在main 函数中使用的iValue变量就是指MyName 命名空间中的iValue 变量。
需要注意的是,如果定义多个命名空间,并且在这些命名空间中都有相同标识符的成员,那么使用using namespace 语句进行包含在引用成员时就会产生歧义性。这时最好还是使用作用域限定符来进行引用。
8.3 定义嵌套的命名空间
命名空间可以定义在其他的命名空间中,在这种情况下,仅通过使用外部的命名空间作为前缀,程序便可以引用在命名空间之外定义的其他标识符。然而,在命名空间内不定的标识符需要作为外部命名空间和内部命名空间名称的前缀出现。例如:
namespace Output
{void Show() //定义函数{cout<<"Outputs function!"<<endl;}namespace MyName{void Demo //定义函数{cout<<"MyName function!"<<endl;}}
}
上述代码中,在Output命名空间中又定义了一个命名空间MyName,如果程序中访问MyName命名空间中的对象,可以使用外层的命名空间和内层的命名空间作为前缀。例如:
Output::MyName::Demo(); //调用MyName命名空间中的函数
用户也可以直接使用using 命令引用嵌套的MyName命名空间。例如:
using namespace Output::MyName; //引用嵌套的MyName命名空间
Demo(); //调用MyName命名空间中的函数
上述代码中,“using namespace Output::MyName;” 语句只是引用了嵌套在Output命名空间中的MyName命名空间,并没有引用Output命名空间,因此试图访问Output命名空间中定义的对象是非法的。例如:
using namespace Windows::GDI;
show(); //错误的访问,无法访问Output命名空间中的函数
定义嵌套的命名空间。
#include <iostream>
using namespace std;
namespace Output //定义命名空间
{void Show(){cout<<"Output function!"<<endl;}namespace MyName //定义嵌套命名空间{void Demo() //定义函数{cout<<"MyName function!"<<endl;}}
}int main()
{Output::Show(); //调用Output命名空间中的函数Output::MyName::Demo(); //调用MyName命名空间中的函数
}
在程序中定义了Output命名空间,在其中又定义了命名空间MyName。
Show 函数属于Output命名空间中的成员,而Demo函数属于MyName命名空间中的成员。在main函数中调用Show和Demo函数时,要将所属的命名空间的作用范围写出。Output::Show表示在Output命名空间范围Show函数,Output::MyName::Demo 表示在嵌套命名空间MyName中的成员函数。
程序编译运行结果如下:

8.4 定义未命名的命名空间
尽管为命名空间指定名称是有益的,但是C++中也允许在定义中省略命名空间的名称来简单的定义为命名的命名空间。
例如定义一个包含两个整型变量的未命名的命名空间:
namespace
{int iValue1 = 10;int iValue2 = 20;
}
事实上在未命名空间中定义的标识符被设置为全局命名空间,但这样就违背了命名空间的设置原则。所以,未命名的命名空间没有被广泛应用。
九、总结
面向对象编程,其设计思路和人们日常生活中处理问题的方法相同,类是实现面向对象程序设计的基础。