1. 架构说明
Java中的线程池是通过Executor框架实现的,该框架中用到了Executor,ExecutorService,ThreadPoolExecutor这几个类。

Executor接口是顶层接口,只有一个execute方法,过于简单。通常不使用它,而是使用ExecutorService接口:

那么问题来了,怎么创建一个连接池对象呢?通常使用Executors工具类
2. Executors工具类
架构图可以看到Executors工具类,有没有联想到Collections,Arrays等。没错,可以用它快速创建线程池。
List list = Arrays.asList("");
ExecutorService threadPool = Executors.newCachedThreadPool();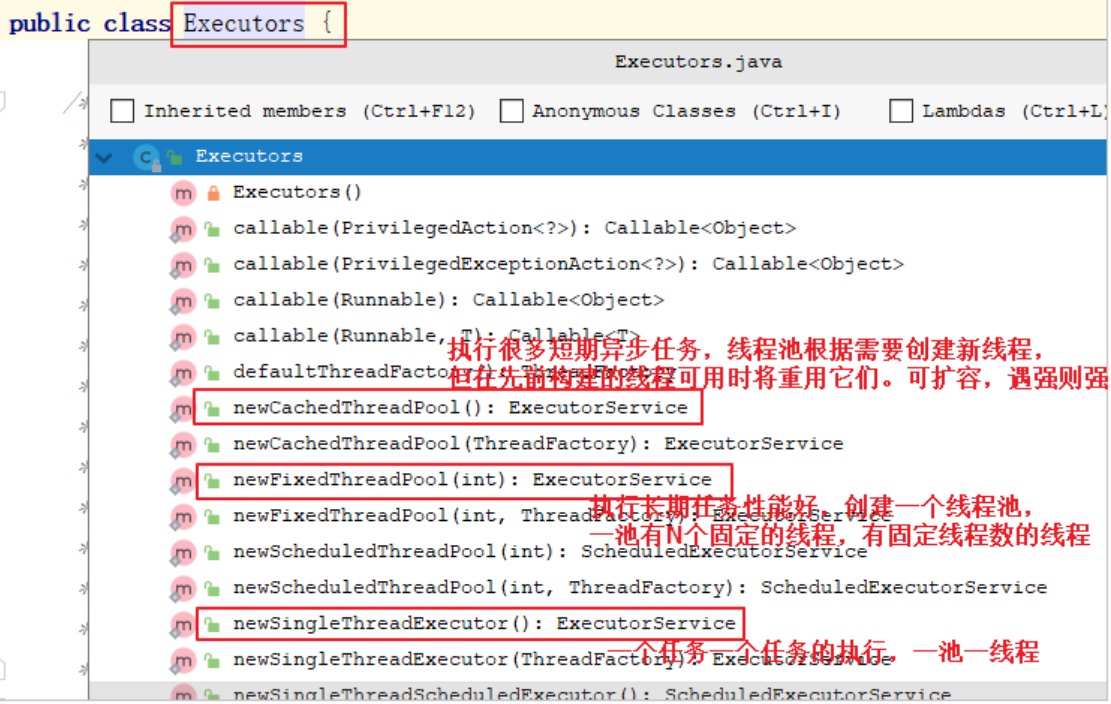
直接编码演示:每种连接池的效果
public class ThreadPoolDemo {public static void main(String[] args) {// 创建单一线程的连接池// ExecutorService threadPool = Executors.newSingleThreadExecutor();// ExecutorService threadPool = Executors.newFixedThreadPool(3);ExecutorService threadPool = Executors.newCachedThreadPool();try {for (int i = 0; i < 5; i++) {threadPool.execute(()->{System.out.println(Thread.currentThread().getName() + "执行了业务逻辑");});}} catch (Exception e) {e.printStackTrace();} finally {threadPool.shutdown();}}
}① Executors.newCachedThreadPool: 短期任务线程池
当线程不足时,有新的任务直接创建新线程执行
- 参数1:线程池运行稳定时需要维护的核心线程数量
- 参数2: 最大允许创建的线程个数: Integer.MAX_VALUE 创建线程过多可能会导致OOM
- 参数3+4: 线程池稳定时 闲置的线程的存活时间
- 参数5:任务阻塞队列 SynchronousQueue不存储元素的阻塞队列
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>()); }
② Executors.newFixedThreadPool(5); 固定线程数线程池
当线程不足时,任务存到了任务队列中,有空闲线程时才会去执行
- 参数1:核心线程数
- 参数2:最大可创建的线程数
- 参数3+4: 非核心线程数以外的线程的空闲存活时间 没有意义
- 参数5:任务队列 new LinkedBlockingQueue<Runnable>() 最多可以存储Integer.MAX_VALUE多个任务对象(runnable)
任务不能及时处理时,任务队列最多支持Integer最大值个任务,可能会导致OOM
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()); }
③ Executors.newSingleThreadExecutor():执行单个任务的线程池
最大线程数核心线程数固定为1,任务队列长度没有限制 也可能会导致OOM
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>())); }
④ Executors.newScheduledThreadPool(5):延迟任务的线程池
任务队列长度、最大线程数都为Integer最大值,可能会导致OOM
public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue()); }
3. 线程池7大参数
述案例中的三个方法的本质都是ThreadPoolExecutor的实例化对象,只是具体参数值不同。
Executors.newSingleThreadExecutor():单个线程的线程池。
Executors.newFixedThreadPool(int nThreads):创建一个自定义个数线程的线程池。
Executors.newCachedThreadPool():按内存大小弹性的分配线程数量。
corePoolSize:线程池中的常驻核心线程数
maximumPoolSize:线程池中能够容纳同时 执行的最大线程数,此值必须大于等于1
keepAliveTime:多余的空闲线程的存活时间 当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到 只剩下corePoolSize个线程为止
unit:keepAliveTime的单位
workQueue:任务队列,被提交但尚未被执行的任务
threadFactory:表示生成线程池中工作线程的线程工厂, 用于创建线程,一般默认的即可
handler:拒绝策略,表示当队列满了,并且工作线程大于 等于线程池的最大线程数(maximumPoolSize)时,如何来拒绝 请求执行的runnable的策略
4. 自定义线程池
在《阿里巴巴java开发手册》中指出了线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程,这样一方面是线程的创建更加规范,可以合理控制开辟线程的数量;另一方面线程的细节管理交给线程池处理,优化了资源的开销。而线程池不允许使用Executors去创建,而要通过ThreadPoolExecutor方式,这一方面是由于jdk中Executor框架虽然提供了如newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()等创建线程池的方法,但都有其局限性,不够灵活;使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险。
public class ThreadPoolDemo {public static void main(String[] args) {// 创建单一线程的连接池// ExecutorService threadPool = Executors.newSingleThreadExecutor();// 创建固定数线程的连接池// ExecutorService threadPool = Executors.newFixedThreadPool(3);// 可扩容连接池// ExecutorService threadPool = Executors.newCachedThreadPool();//创建延时任务的连接池//ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(3);//executor.scheduleAtFixedRate(()->{// System.out.println("任务正在执行:"+ new Date());//},5 , 3 , TimeUnit.SECONDS);// 自定义连接池ExecutorService threadPool = new ThreadPoolExecutor(2, 5,2, TimeUnit.SECONDS, new ArrayBlockingQueue<>(3),Executors.defaultThreadFactory(),//new ThreadPoolExecutor.AbortPolicy()//new ThreadPoolExecutor.CallerRunsPolicy()//new ThreadPoolExecutor.DiscardOldestPolicy()//new ThreadPoolExecutor.DiscardPolicy()new RejectedExecutionHandler() {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {System.out.println("自定义拒绝策略");}});try {for (int i = 0; i < 9; i++) {threadPool.execute(() -> {System.out.println(Thread.currentThread().getName() + "执行了业务逻辑");});}} catch (Exception e) {e.printStackTrace();} finally {threadPool.shutdown();}}
}5. 自定义线程池线程数说明
开发中我们可以把任务分为计算(CPU)密集型和IO密集型。
计算(CPU)密集型任务大部份时间用来做计算、逻辑判断,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,任务同时进行的数量应当等于CPU的核心数。一般公式:线程数量=CPU核数+1个。
IO密集型CPU消耗很少,任务的大部分时间都在等待IO操作完成(99%的时间都花在IO上,花在CPU上的时间很少)。此类任务,任务越多,CPU效率越高,但也有一个限度。大部分任务都是IO密集型任务,比如Web应用。一般公式:线程数量=CPU核数/(1-阻塞系数) 阻塞系数为0.8~0.9之间。
6. 线程池底层工作原理
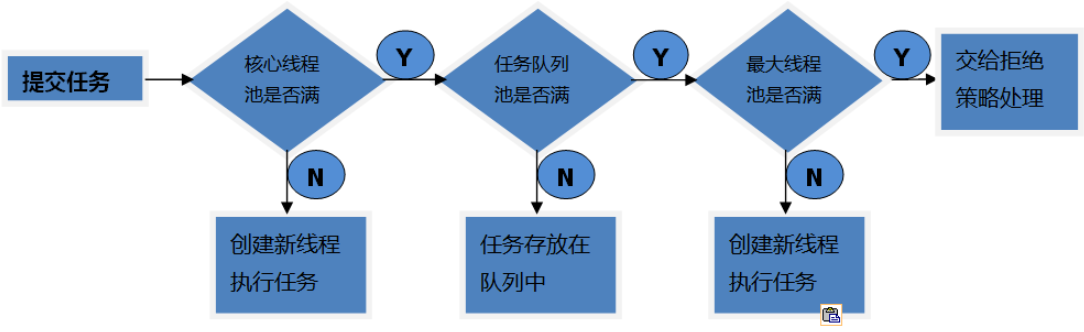
具体流程:
重要的事情说三遍:以下重要:以下重要:以下重要:
在创建了线程池后,线程池中的线程数为零。
当调用execute()方法添加一个请求任务时,线程池会做出如下判断:
如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列;
如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
如果队列满了且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。
当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。
所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小。
7. 拒绝策略
一般我们创建线程池时,为防止资源被耗尽,任务队列都会选择创建有界任务队列,但种模式下如果出现任务队列已满且线程池创建的线程数达到你设置的最大线程数时,这时就需要你指定ThreadPoolExecutor的RejectedExecutionHandler参数即合理的拒绝策略,来处理线程池"超载"的情况。
ThreadPoolExecutor自带的拒绝策略如下:
AbortPolicy(默认):直接抛出RejectedExecutionException异常阻止系统正常运行
CallerRunsPolicy:“调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。
DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加人队列中 尝试再次提交当前任务。
DiscardPolicy:该策略默默地丢弃无法处理的任务,不予任何处理也不抛出异常。 如果允许任务丢失,这是最好的一种策略。
以上内置的策略均实现了RejectedExecutionHandler接口,也可以自己扩展RejectedExecutionHandler接口,定义自己的拒绝策略。


![[React] useRef用法和特性](https://img-blog.csdnimg.cn/d8702d68909d44919d15527c2131a752.png)