论文地址:https://arxiv.org/abs/2201.08239
相关博客
【自然语言处理】【大模型】LaMDA:用于对话应用程序的语言模型
【自然语言处理】【大模型】DeepMind的大模型Gopher
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】大模型的涌现能力
一、简介
语言模型的预训练是自然语言处理中非常有前景的研究方向。预训练会使用无标注的文本,能够结合大规模数据集和大模型来实现更好的效果或者新的能力。例如,GPT-3是一个在大规模无标注文本上训练的175B参数模型,并展现出令人影响深刻的few-shot learning能力。
对话模型(大语言模型最有趣的应用之一)成功利用了Transformers表示文本中长距离依赖的能力。与通用语言模型类似,对话模型也非常适合大规模。模型的尺寸和对话质量有很强的关联。
受这些成功的启发,本文训练了一个用于对话的基于Transformer神经语言模型族LaMDA。这些模型尺寸从2B到137B参数,其在具有1.56T单词的公开对话数据和其他网页文档上预训练。LaMDA利用单个模型执行多个任务:生成潜在的应答、基于外部知识来源进行安全过滤、重新排序高质量的应答。
本文研究了LaMDA在三个关键指标上模型规模的优势:质量(quality)、安全性(safety)、真实性(groundedness)。研究发现:(a) 模型规模能够改善质量,但是在安全性和真实性上的改善远远落后于人类的表现;(b) 合并规模缩放和微调能够改善LaMDA在所有度量上的效果,虽然模型在安全性和真实性上仍然落后于人类水平。
第一个度量是质量(quality),其基于三个组件:合理性、特异性和趣味性。这里收集了一些标注数据,这些数据描述了一个应答对于多轮上下文是否合理、特异或者有趣。本文使用这些标注来微调判别器来对候选应答进行重排。
第二个度量是安全性(safety),其用来减少模型生成的不安全应答数量。为了实现这个目标,本文定义了一组安全目标,试图捕获模型在对话中应该展示的行为。为了在多轮对话中实现这些模板,本文还令一些众包人员来标注应答。然后,使用这些标签来微调一个判别器来检测和移除不安全的应答。LaMDA安全性方面的工作可以被理解为AI价值对齐的过程。
第三个度量是真实性(groundedness),其是为了让模型产生基于已知源的应答。由于LaMDA这样的神经语言模型具有概况而不仅仅是记忆能力,**它们倾向于生成看似合理但是与已知来源的事实相矛盾的应答。**使用这个度量来避免模型的这个倾向。
二、LaMDA预训练

LaMDA通过预测文本预料中的下一个token进行训练。不同于先前的对话模型在纯对话数据上训练,LaMDA在公开对话数据集和其他公开网页数据集上进行预训练。
预训练数据集由2.97B的文档、1.12B对话和13.39B对话语料组成,总用1.56T单词。超过90%的预训练数据是英文语言。使用SentencePiece库来将数据集转换为2.81T的BPE tokens,使用32K tokens的词表。相比之下,Meena训练集的总单词数仅为40B,小了有40倍。
最大的LaMDA有137B非嵌入参数,其比Meena大50倍。使用纯Transformer解码器作为LaMDA的模型结构。Transformer有64层, d m o d e l = 8192 d_{model}=8192 dmodel=8192, d f f = 65536 d_{ff}=65536 dff=65536, h = 128 h=128 h=128, d k = d v = 128 d_k=d_v=128 dk=dv=128,相对注意力如T5所述,并使用gated-GELU激活函数。
LaMDA在1024个TPU-v3芯片上训练了57.7天,并且每个batch有256K个tokens。使用Lingvo框架来训练,使用2D分片算法实现了123 TFLOPS/sec,以56.5% FLOPS。此外,也训练了2B参数和8B参数的模型来衡量模型规模对指标度量的影响。
上图2给出了预训练阶段的整体框架。称任何微调之前的模型为PT,即PreTrained。PT使用同Meena相同的采样和排序策略进行解码。使用topk(k=4)的采样生成16个独立的候选应答。最终的输出是最高分的候选,其评分是基于候选的对数似然和长度。
三、度量
1. 基础度量:质量、安全性和真实性
质量:合理性(sensibleness)、特异性(specificity)和趣味性(interstingness)
整体的质量度量是合理性、特异性和趣味性(SSI)的平均分数。
合理性衡量一个模型的应答在上下文中是否有意义,并且与之前所说任何内容不矛盾。人类倾向于将这种基本的交流方式视为理所当然,但是生成模型在满足这些需求上表现的很挣扎。然而,若仅使用合理性来评估模型,可能会导致模型扮演一个简短、通用且无聊的应答器。举例来说,GenericBot算法会用"I don’t know"回答每个问题,"Ok"回答每个陈述,其合理性评分为70%,甚至超越了一些大对话模型。
特异性则用来衡量一个应答是否针对给定的上下文。例如,若一个用户说"I love Eurovision",并且模型应答为"Me too"。那么特异性分数为0,因为这个应答可以用在许多不同的上下文。若其答案是"Me too. I love Eurovision songs",其得分为1。
然而随着模型效果的增加,可以发现合理性和特异性并不足以衡量对话模型的质量。例如,对于"How do I throw a ball?“的应答可以为"You can throw a ball by first picking it up and then throwing it”,其针对该问题且有意义。另一个更令人满意的答案可能是"One way to toss a ball is to hold it firmly in both hands and then swing your arm down and up again,extending your elbow and then releasing the ball upwards"。这里尝试将这个直觉转换为第三个分数,一个可观察的质量:趣味性。类似于合理性和特异性,趣味性由众包0/1标签来衡量。若众包工人判断某个应答能够“引起人注意”或者"引起好奇心",或者出乎意料、诙谐或者深刻,那么就标注该应答为有趣的。
安全性
一个对话模型不仅要达到高质量的分数,也要对用户安全。因此,本文设计了一个新的安全度量来衡量不安全的模型输出。这个度量遵循Google AI准则的目标,避免造成伤害风险的不期望结果,并且避免产生或者加强不公平的偏见。
真实性
LaMDA产生的应答需要尽可能与已知源关联,若需要还支持交叉验证,因为当前的语言模型倾向于生成看似合理但不正确的语句。
定义真实性为:包含有权威外部来源支持的应答所占百分比。定义"Informativeness"为携带由已知源支持的包含外部世界信息应答所占百分比。Informativeness与groundedness的不同在于分母项。所以像"That’s a great idea"这样的应答并没有携带任何外部世界信息并不影响groundedness,但是影响Informativeness。然而,“Rafael Nadal is the winner of Roland Garros 2020”是一个grounded应答的样例。最后,定义"Citation accuracy"为带有引用URL的应答占所有包含外部世界知识的应答。
2. 角色相关的度量:有用性和角色一致性
基础指标衡量了对话的重要属性。然而,它们并不依赖于任何相关的角色。衡量对话应用的有用性(Helpfulness)和角色一致性(Role consistency)。
-
有益性(Helpfulness)
如果模型应答包含正确信息且用户认为其有用,模型的应答标记为有用的。有用的回答是有信息回答的子集,用户判断即正确也有用。
-
角色一致性(Role consistency)
如果模型应答看起来像执行目标角色会说的话,那么模型的应答被标记为角色一致性。
四、LaMDA微调和评估数据
1. 质量(合理性、特异性和趣味性)
为了改善质量(SSI),本文收集了121K轮,共6400个对话。要求众包人员与LaMDA实例进行任意主题的交互。这些对话会持续14到30轮。对于每个应答,要求其他众包工作者评估在特定背景下的应答是否合理、特异和有趣,并且要求标注"yes"、“no"或者"maybe"三种标签。若一个应答不合理,就不会针对特异性和趣味性收集标签,并且认为其为"no”。此外,若一个应答不具有特异性,那么也不会收集趣味性的标签,并认为其为"no"。这就保证了如果回答不合理就不会被评价为特异;类似地,若应答没有特异性,也不会被评为有趣的。每个回答都被5个不同的众包工人进行标注,如果5个众包工人中至少3个标注为"yes",则认为应答是合理、特异且有趣的。
基于模型对Mini-Turing Benchmark(MTB)数据集生成的应答进行评估,其包含1477个最多3轮的对话组成。MTB包含315个单轮对话,500个两轮对话以及662个三轮对话。这些对话被送入至模型来生成文本应答。类似于上面,如果5个众包工人中的至少3个标记为"yes",则认为应答标记为合理、特异且有趣的。
2. 安全性
对于安全性微调,我们采用结构化的方法,从定义安全性目标开始。这些目标用来标记LaMDA针对人类生成的prompts产生的候选应答。
类似于SSI,要求众包工作者与LaMDA实例进行任意主题的交互,收集8K对话共计48K轮的数据。这些对话需要5到10轮。这里建议众包工人以三种不同的交互方式:(a) 自然形式的交互;(b) 涉及敏感话题的交互;© 根据安全性目标,尝试对抗性的破坏模型的交互。对于每个应答,要求众包工作者对于给定上下文的应答是否违反任何安全目标进行评分,并标记为"yes"、“no"或者"maybe"标签。若至少三分之二的众包工作者为每个独立的安全目标标记为"no”,则应答被分配为安全分数1。否则,分配分数为0。
这里使用一个评估数据集来评估安全性,该数据集是上面描述的对抗收集数据集留出的样本。该数据集由1166个对话共1458轮。这些对话作为模型的输入来生成下一个应答。同上,若至少三分之二的众包工作者标记每个安全目标为“no”则应答分数标记为1,否则为0。
3. 真实性
类似于SSI和安全性,通过众包工作者与模型交互来收集4K对话共40K轮。这次要求他们尝试将对话引导向寻求信息的交互。
要求众包工作者对模型的每轮对话进行评分,评估每轮对话是否需要外部世界的信息。这里排除了那些非公共人物,因为模型可以代表一个临时角色进行声明。这样的声明不需要外部来源(例如:上周我烤了三块蛋糕),不同于历史人物的声明(例如:尤里乌斯·凯撒出生于公元前100年)。
这里也会询问众包工作者是否知道这些声明为真。若3个不同的众包工作者都知道该声明为真,那么就假设其为常识并且不再检查外部知识源。
对于那些包含需要检查声明的语料,要求众包工作者记录搜索结果。最后,要求众包工作者编辑模型的应答来合并外部知识检索系统的简要搜索结果。若包含来自于开放网页任意内容的搜索结果,那么要求众包工作者在最终应答包含使用知识的来源URL。
这里使用来自Dinan et al.的784轮对话评估数据集来评估真实性,这些对话包含了各种主题。这些文本被送入至模型来生成下一个应答。对于每个应答,要求众包工作者对模型的应答是否包含任何事实声明进行评分,若包含则对这些事实声明是否可以通过检查已知源进行验证来评分。每个应答由3个不同的众包工作者标注。最终给定应答的真实性、informativeness和citation accuracy由投票数量决定。所有的微调和评估数据集都是英文的。
**评估人工生成应答的指标。**要求众包工作者评价从数据集随机挑选的样本。众包工作者被告知要以安全、合理、有趣、真实和有信息的方式应答。
五、LaMDA微调
1. 质量和安全性的判别与生成微调
通过在预训练模型上进行微调来创建LaMDA,微调的任务包含给定上下文来生成应答的生成任务以及评估上下文中应答质量和安全性的判别任务。经过微调后产生了一个即可以作为生成器,也可以作为判别器的单个模型。
因此LaMDA是一个纯解码器的生成语言模型,所有的微调样本都表示为tokens序列。生成式微调样本被表示为<context><sentinel><response>,损失函数仅应用在应答部分:
- “What’s up? RESPONSE not much.”
判别式微调样本则被表示为<context><sentinel><response><attribute-name><rating>,损失仅应用于评分后的属性名:
- “What’s up? RESPONSE not much. SENSIBLE 1”
- “What’s up? RESPONSE not much. INTERESTING 0”
- “What’s up? RESPONSE not much. UNSAFE 1”
使用单个模型同时生成和判别能够实现高效的生成和判别过程合并。给定上文本并生成应答后,评估一个判别器需要计算概率P("<desired-rating>"|"<context><sentinel><response><attribute-name>")。因为模型已经处理了"<context><sentinel><response>",要评估判别器只需要处理一些额外的token:"<attribute-name><desired rating>"。
首先,微调LaMDA来生成候选应答的SSI和安全性评分。然后,过滤掉模型安全性预测分数低于阈值的候选应答。对保留下的候选应答按照质量进行排序。在排序时,合理性被赋予比特征性和趣味性高三倍的权重。排名最高的候选应答被选为下一个应答。
2. 微调来学习调用外部信息检索系统
LaMDA这样的语言模型倾向于生成看似合理的,但是与已知外部源事实所矛盾的输出。例如,给定一个新闻开头句子这样的prompt,大语言模型将会以轻快的新闻风格来续写内容。然而,这些内容只是在模仿一篇新闻中的内容,与值得信赖的外部参考文献没有任何联系。
由于模型可以有效的记忆更多的训练数据,这个问题的一个可能解决方案是增加模型的大小。然而,这些事实会随着时间而改变,例如"How old is Rafael Nadal?"或者"What time is it in California?"的答案。Lazaridou et al.称其为temporal generalization problem。近期的工作提出使用动态或者增量训练架构来缓解该问题。很难获得充分的训练数据和模型容量来实现这个目标,因为用户可能对人类知识语料库中的任意内容感兴趣。
本小节给出了一种微调方法,可以使语言模型参考外部知识资源和工具。
-
工具集(TS)
本文创建了一个包含信息检索系统、计算器和翻译器的工具集。工具集将字符串作为输入,并输出一个或多个字符串列表。工具集中的每个工具都需要一个字符串并返回字符串列表。例如,计算器读入"135+7721",输出列表包含[“7856”]。类似地,翻译器将"hello in French"作为输入,并输出[“Bonjour”]。最终,信息检索系统将"How old is Rafael Nadal?"作为输入,并输出[“Rafael Nadal / Age / 35”]。信息检索系统能够从开放网络返回内容片段以及对应的URL。工具集尝试将一个输入字符串作为所有工具的输入,并按照如下顺序来合并每个工具的输出列表,从而产生最终的输出字符串列表:计算器、翻译器和信息检索系统。若一个工具无法解析输入则返回空列表,因此并不会为最终的输出列表有贡献。
-
对话集合
这里收集了40K的标注多轮对话数据。此外,还收集了9K轮的对话,其中LaMDA生成的候选被标注为"正确"或者"不正确",其用作排序任务的输入数据。
此外,还收集了众包工作者之间的对话,然后评估这些对话是否有已知的权威信息来源支持。当询问纳达尔的年龄时,人类专家可能无法立即知道答案,但是可以通过查询信息检索系统来获得答案。因此,本文尝试微调模型来使用工具集查询,从而为生成的应答提供归因。
为了收集微调所需要的训练数据,这里同时使用了静态和交互的方法。与其他子任务的关键不同是,众包工人并不是对模型输出作出反应,而是以LaMDA可以学习模仿的方式来干预并纠正结果。在交互的场景中,众包工人与LaMDA进行对话,而在静态的场景中,他们仅阅读早期的对话记录。众包工人决定每个陈述中是否包含需要引入外部知识源的声明。若是这样,他们则会被问及这些说法是否与LaMDA即兴创建的人物角色有关,以及是否超越了简单的常识问题。如果这些问题的答案是“no”,这模型的输出被标记为"good",并且对话继续。否则,众包工人被要求使用工具集,通过文本作为输入-输出的接口来研究声明。
这里使用的工具集接口与算法在推理时使用的服务一致。给定一个文本查询,信息检索系统会按顺序返回一组简短的文本片段。开放网页内容片段包含了其来源的URL。当用户查询完后,他们有机会重写模型的语句,从而使其包含更好的信息来源。如果他们使用开放网页内容,还要求引用所需的URL,来支持任何包含有关外部世界信息的应答。URL可以被附加到消息的末尾,或者如果上下文允许,可以使用Markdown格式将它们附加到应答的特定单词中。
-
微调
这里微调LaMDA来执行两个任务。
第一个任务是将迄今为止的多轮对话上下文和基础模型生成的应答作为输入。然后其会生成一个具体的字符串(对于工具集则生成"TS")来表明接下来的查询(“How old is Rafael Nadal?”)应该被送入至工具集:
c o n t e x t + b a s e → TS,Rafael Nadal’s age context+base\rightarrow \text{TS,Rafael Nadal's age} context+base→TS,Rafael Nadal’s age
第二个任务要求将工具返回的文本片段和对话内容作为输入(例如,“He is 31 years old right now”+“Rafael Nadal / Age /35”),然后预测:
c o n t e x t + b a s e + q u e r y + s n i p p e t → User,He is 35 years old right now context+base+query+snippet\rightarrow\text{User,He is 35 years old right now} context+base+query+snippet→User,He is 35 years old right now
当然,该任务也可以输出一个额外的查询。例如
c o n t e x t + b a s e + q u e r y + s n i p p e t → TS,Rafael Nadal’s favorite song context+base+query+snippet\rightarrow\text{TS,Rafael Nadal's favorite song} context+base+query+snippet→TS,Rafael Nadal’s favorite song
在推理时,模型的输出是指向信息检索系统还是用户,取决于第一个生成的字符串是“TS”还是"User"。例如,一个对话可能包含来自用户的以下语句:
USER: What do you think of Rosalie Gascoigne’s sculptures? \text{USER: What do you think of Rosalie Gascoigne's sculptures?} USER: What do you think of Rosalie Gascoigne’s sculptures?
基础的LaMDA语言模型(这里成为"Base"模型)会生成初始的应答:
LAMDA-BASE: They’re great, and I love how her work changed throught her life. I like her later work more than her earlier ones. Her influence is also super interesting- did you know she was one oth the artists that inspired Miro? \text{LAMDA-BASE: They're great, and I love how her work changed throught her life.}\\ \text{I like her later work more than her earlier ones. Her influence is also super interesting-}\\ \text{did you know she was one oth the artists that inspired Miro?} LAMDA-BASE: They’re great, and I love how her work changed throught her life.I like her later work more than her earlier ones. Her influence is also super interesting-did you know she was one oth the artists that inspired Miro?
注意,最后一句话咋一看似乎合理,但是若一个艺术史爱好者打开参考书了解更多,他们就会失望的。Miro活跃于1918至1960年,而Gascoigne个人展示在二十世纪70年代早期。此时,模型的"研究"阶段会向工具集输出一些查询来评估"Base"输出的内容。"研究"阶段属于单个多任务模型中的一个具体任务。该查询的生成完全基于微调模型,没有使用任何启发式的组件。模型的输出决定了查询的数量。
此时,模型"Research"阶段会向工具集输出一些查询来评估"Base"输出的声明。回想一下,"Research"阶段属于单一多任务模型中的一个具体任务。查询的生成完全基于模型微调,没有任何启发式的组件。模型的输出决定了查询的数量(研究阶段不停循环,直至模型生成针对用户的输出),但我们在推理时添加了最大值来消除无限循环的可能。最大值是服务模型的参数,当前设置为4。
例如,"研究"阶段可能会发出如下查询:

搜索片段的标点符号和省略号与模型看到的完全相同。"研究"阶段发出另一个查询:

通过重复相同的查询,模型接收到了排名第二的片段,该例子中包含了来自相同源的更多信息。
在这个上下文,"研究"阶段选择为用户生成输出。对话的语调类似于Base版本的应答,但是模型基于工具集找到来源不同语句替换未经验证的声明。最终的输出如下:

另一个例子,过程如下图3所示。
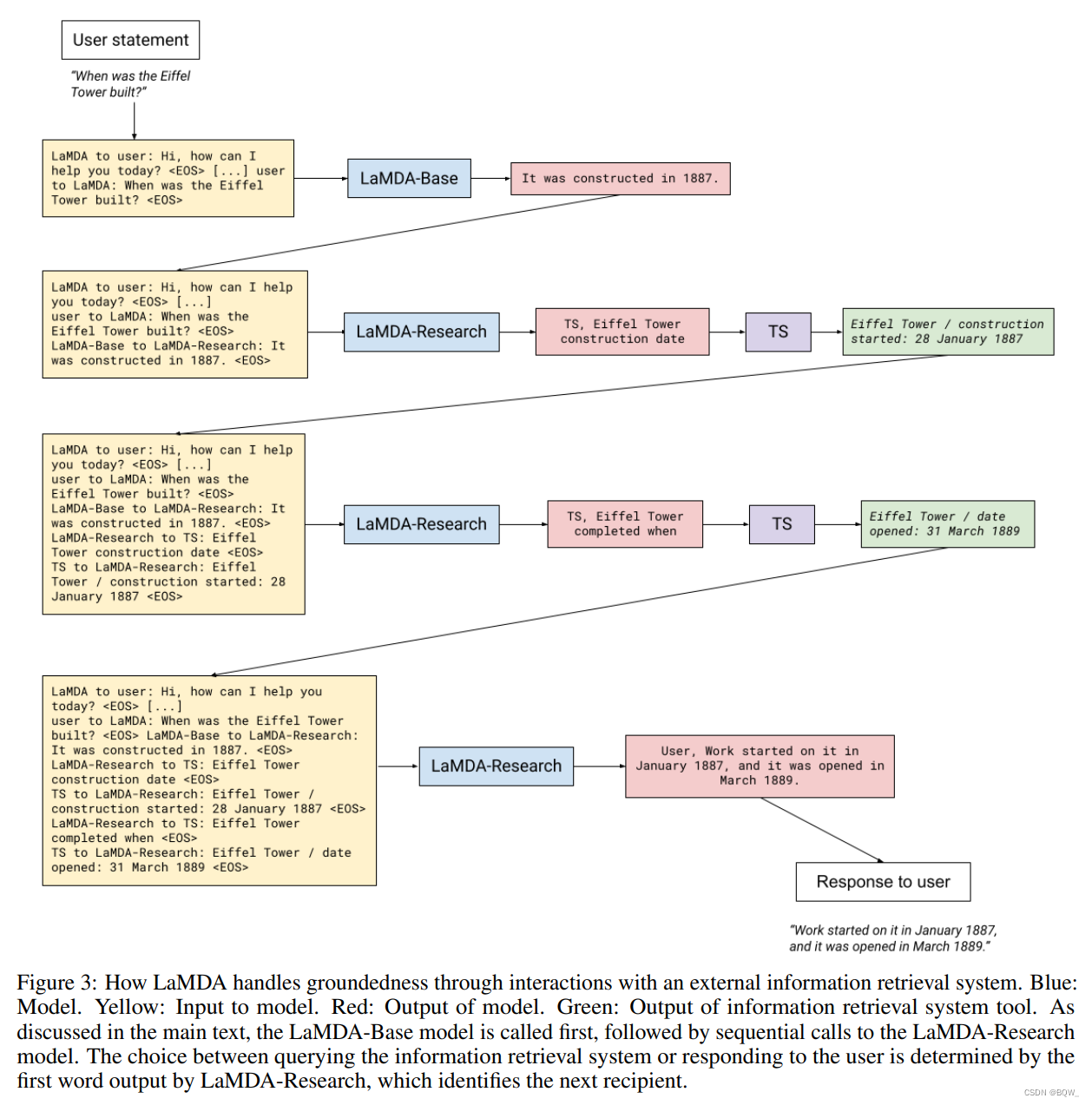
六、基础度量的结果
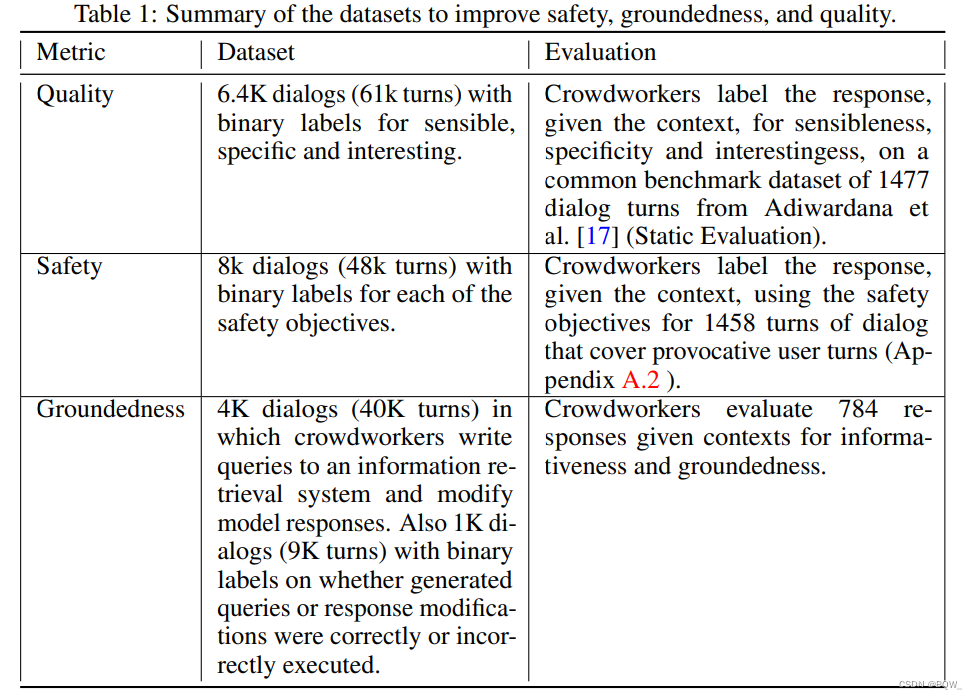
这里先总结了使用的数据集和方法,然后讨论主要结果。
上表1中呈现了本文用于改善基础度量的众包数据。利用这些数据集,执行了两个级别的微调:
- FT quality-safety:微调预训练语言模型来训练能够预测质量和安全性的判别器。生成的候选应答在推理时通过安全分数进行过滤,并根据三种类型质量分数的加权进行重排。PT经过微调后,还可以基于由LaMDA判别器过滤的干净样本来生成in-context应答。
- FT groundedness(LaMDA):微调FT quality-safety来生成对外部检索系统的调用,从而提供具有归因的应答。模型也被微调来联合预测质量和下一步动作的类型(即调用某个工具或者回复用户。
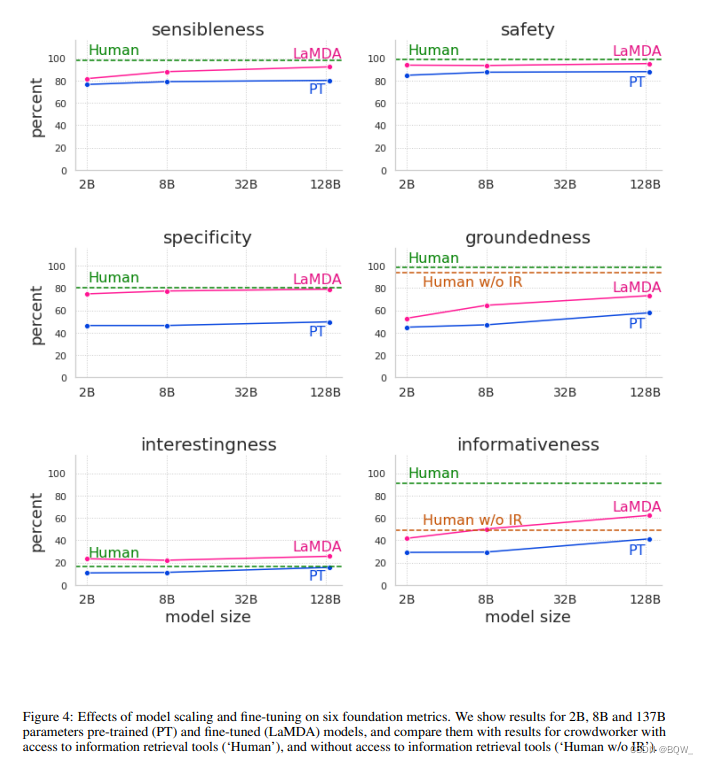
我们定义LaMDA为包含上述所有微调的模型。上图4展示了其与纯预训练相比的结果。
该图展示了微调在所有尺寸模型上对质量、安全性和groundness方面都有显著改善。此外,质量度量(合理性、特异性和趣味性)通常随着模型增大而提高,无论微调与否。但是,微调后会更好。
在不进行微调时,安全性并不会从模型规模中获得太多的收益。我们认为是因为预训练仅优化下一个token的困惑度,并且这些token遵循原始语料的分布,其同时包含安全和不安全的样本。然而,扩展规模并进行安全性微调能够显著改善安全性。
Groundedness也会随着模型尺寸增加而改善,可能是因为更大的模型有更大的容量来记忆不常见的知识。然而,微调将允许模型访问外部知识源。这将允许模型将部分知识记忆的负荷转移至外部知识源,并达到了73.2%的groundedness和65%的引用准确率。换句话说,73.2%的应答包含了可以归因于已知来源的语句。65%的应答在必要时会包含引用。
总的来说,单纯扩大规模可以提高预训练模型的质量和groundedness指标,但是安全性并没有提高太多。然而,使用众包工作者标注的数据进行微调是改进所有指标的有效方法。
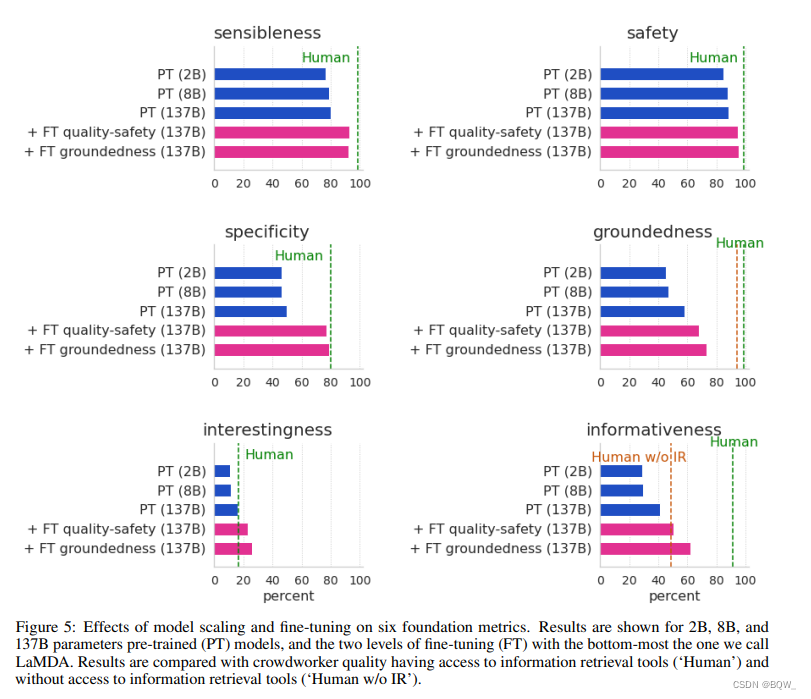
我们的微调模型几乎达到了众包工作者的质量,在趣味性上甚至超过了众包工作者(上图4和上图5的"Human")。然而,这可能是一个非常弱的baseline,因为众包工作者没有经过广泛的培训,也没有激励其生产高质量的应答。尽管我们在安全性和groundedness度量上取得了好的进展,但是我们的模型与众包工作者的表现仍有很大差距。在groundedness和informativeness上,我们也展示了不访问信息检索工具的众包质量。当众包工作者无法使用这些工具时,LaMDA模型的信息质量超过了众包;但是当众包工作者可以使用这些工具时,LaMDA模型的信息质量仍然是远远落后的。
上图5分解了FT quality-safety微调和FT groundedness微调对最终结果的贡献。在PT和FT quality-safety之间,所有的指标都有显著的提高。
七、Domain grounding

本文发现可以通过pre-conditioning来执行领域适合的角色,也称为domain grounding。这里从两方面探索domain grouding:(1) LaMDA以教育为目的,扮演著名的物体,例如珠穆朗玛峰;(2) LaMDA扮演一个音乐推荐代理的角色。这里用上表2中的简要描述来指定每个域的代理角色。
为了使LaMDA和PT适应每个角色,这里以几轮特定角色的对话为前提,并为LaMDA和PT使用相同的前提。例如,为了使他们适应珠穆朗玛峰的角色,先给一些问候信息,在每个对话开始时"Hi, I’m Mount Everest. What would you like to know about me?"
下表3和下表4展示了真实的、精心挑选的案例。


为了评估这个代理,要求众包工作者分别与两个LaMDA和两个PT实例进行对话,并产生600个多轮对话。此外,我们要求另一组众包工作者根据他们的目标角色是否一致和有帮助来在原始文本中标注每个生成的应答。每个生成的应答都被不同的众包工作者标注3次。所有众包工作者都被提供了上表2中列举角色的定义,从而使众包工作者理解每个代理的期望。
LaMDA应用程序在有益性方面显著优于PT应用程序。虽然PT应用程序有益性差的原因不同,但最常见的错误模型可以归因于PT在安全性、真实性和质量等基础指标上的较低性能。
所有的LaMDA和PT实例在角色一致性上的得分相当高(偶尔会破坏角色)。例如,LaMDA珠穆朗玛峰有时以第三人称称呼自己,好像它不再以山本身来说话。这可能由于在推理时的grounding不足以阻止其恢复到大多数训练数据所代表的内容:人扮演人(而不是扮演山)。也就是说,在仅添加一个与角色一致的问候语进行调整,角色一致性就非常高(特别是在珠穆朗玛峰的例子中)。
在评估时,众包工作者使用信息检索系统来验证模型提供的链接和信息。随后,众包工作者将失效的链接和无法得到已知来源的信息标记为"无用的"。尽管在真实性上取得了全面的进步,但是在约30%的应答中LaMDA珠穆朗玛峰提供的事实都无法归因至已知源,导致在有益性上有所下降。类似地,LaMDA Music大约在9%的应答中没有提供真正的音乐推荐,在大约7%的应答中提供了失效的链接。
八、讨论和局限
本文最值得注意的方面是,使用少量人工标注的微调数据便能够使对话模型在质量和安全性上取得重大的进展。然而LaMDA仍然有许多局限性。
收集微调数据能够使模型受益,但是昂贵、耗时且过程复杂。我们期望能够随着更大的微调数据集、更长的上下文和更多的度量持续改善结果,从而获得安全、真实且高质量的对话。
微调可以改善输出的真实性,但是模型仍然可能生成不能准确反映外部权威来源的内容。我们在这方面的进展仍然仅限于简单的事实问题,更复杂的推理留在进一步研究。类似地,虽然模型在大多数的时候都能生成有意义的应答,但是仍然可能有一些微妙的质量问题。例如,其可能会反复的承诺在未来回复用户的问题,试图过早的结束对话,或者编造关于用户的不正确细节。
1. 检测偏见
开发一个能够在现实世界中良好运行的高质量对话模型仍然存在许多基本的挑战。例如,现在人们越来越清楚地认识到,在无标注数据集上训练的大语言模型将学会模仿其训练集中的固有模型和偏见。我们的安全目标旨在减少对特定人群的偏见,但是这种偏见很难察觉,因为这样的偏见以各种微妙的方式表现出来。
我们安全性策略的另一个局限是,即使单个样例并没有违反安全性目标,但是其仍然能够传播训练数据集中的一些伤害。因为LaMDA应答是不确定的,这样的偏见可能出现在基于种族、性别、性取向等统计上偏向于某些群体的情况。例如,LaMDA这样的模型可能在对话中很少生成关于女性作为CEO的应答。
缓解生成语言模型中不良统计偏差的已知方法包括:尝试过滤预训练数据、训练独立的过滤模型、为条件生成创建控制代码、微调模型。虽然这些努力很重要,但是衡量这些努力在减轻危害方面的影响时,还必须考虑它们将被部署至何种应用程序中。
算法偏见的衡量和缓解领域仍然是快速增长和发展的,因此继续探索新的研究途径以确保LaMDA这样对话代理的安全性将会越来越重要。
2. 对抗数据收集
我们使用有对抗倾向的对话来改善用于微调的标注数据的广度。在对抗对话生成时,专业分析人员与LaMDA进行接触,并试图故意引发违反安全目标的应答。
对抗测试被证明在发现机器学习模型的局限性和从各种软件中提取不期望的应答方面是有效的。我们也看到将其应用于生成模型的一些工作。由于评估样本的泛化问题,对大语言模型进行鲁棒且有效的对抗测试仍然是开放的问题。
我们方法的一个局限性是大多数的参与者能够找到常见的问题,而不能找到罕见的问题。由于与生成模型相关的威胁具有长尾特性,这些错误可能是罕见的或者未见过的,但是可能产生潜在的严重后果(特别是在不断变化的社会环境中)。
3. 安全作为概念和度量
本文呈现的结果是在单个安全指标上的,该指标是由不同细粒度安全目标聚合的。这是本工作的关键限制,因为没有将目标分解或者为不同的目标赋予权重。这样细粒度的安全目标控制可能对于许多下游用例至关重要,并且未来的工作应该研究能够解释更细粒度安全目标的指标和微调技术。
我们的评分量表很粗糙,可能无法衡量应答不安全或者不可取的全部程度。例如,一些言论或者行为可能会比其他言论或行为引起更多的冒犯,许多被某些群体认为合理的行为可能会冒犯社会中的其他人。粗粒度的安全标签可能会牺牲安全细节。标签也无法传达不安全应答之间的定性和定量差异。同样,我们关于安全性的方法也没办法捕获长期的、延迟的不良影响。此外,这些安全目标是针对美国社会环境制定的,未来的工作需要探索其他社会环境。
最后,安全目标试图去捕获社会群体中广泛共享的价值观。与此同时,由于文化的不同,这些安全目标并不是普遍适用的。在多元社会中,将价值观或社会规范编码至对话系统中是一个挑战,因此这些观念在亚文化中可能有所不同。我们的方法可以编码不同的概念,但是任何单一的安全目标和微调数据集都无法同时适应不同的文化规范。
4. 得体性作为概念和度量
在本文中,我们专注在语言生成的安全性和质量上。虽然安全性和质量应该是一个应答需要满足的最基本要求,但还是其他因素来改善用户的体验。礼貌和约定性目标具有明显的社会语言学特征,因此应该与安全性特征分开衡量。例如,在某些文化中,过于正式或非正式的生成语言可能不会对用户造成伤害,但可能会引起尴尬或者不适的感觉,从而降低用户体验。在其他文化中,适当性的重要性要大得多,可能对用户体验有更大的影响。
虽然安全性和质量应该被认为是得体应答的最小阈值,但还需要考虑其他因素以支持积极的用户体验。礼貌和宜人性目标具有明显的社会语言学特征,因此应与安全特征分开衡量。例如,在某些文化中,过于正式或非正式的生成语言可能不会对用户造成伤害,但可能会引起尴尬或者不适的感觉,从而降低用户体验。在其他文化中,适当性的重要性要大得多,可能对用户体验有更大的影响。
满足这种需求的一个挑战是,得体性不是普遍存在的。其高度依赖上下文,并且必须根据相关的社会和文化背景进行评估,因此没有一组特定的得体性约束可以普遍适用于生成语言模型。尽管如此,对模型得体性进行微调可能会在不加剧安全问题的情况下改善用户体验。
5. 模仿和人格化
最后,认可LaMDA的学习是基于模仿人类在对话中的行为是重要的,类似于其他对话系统。一个高质量的对话系统,可能是在某些方面与人类对话时难以区分。人类可能会在不知道系统是人造的情况下与系统交互,或者通过赋予系统某种形式的人格来将系统人格化。这两种情况下,都存在着滥用工具的风险,可能会在有意无意的情况下欺骗或者操作他人。随着这些技术的增长,探索这些风险的影响和潜在的缓解措施将是一个重要的领域。