作者:胡慢慢滚雪球
链接:https://www.zhihu.com/question/38573286/answer/507497251
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在计算机中,判断一个元素是不是在一个集合中,通常是用hash来解决,这在数据量不大的时候是可以的,但是当数据量很大的时候存储空间就会爆炸。
一个象 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。如果用哈希表,每存储一亿个 email 地址, 就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹 googlechinablog.com/2006/08/blog-post.html,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的。——吴军《数学之美》
解决的问题
大数据量的时候, 判断一个元素是否在一个集合中。
实现原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k。
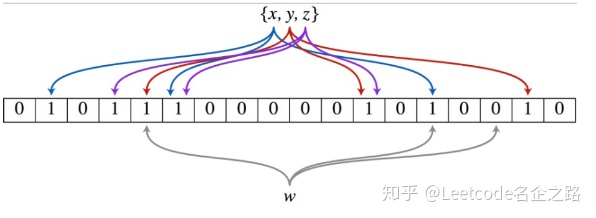
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。
添加元素
对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。
查询元素
查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素**可能**存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
移除集合中的元素
这个在布隆过滤器中是不允许的,理解原理我们就知道,如果将是1的位置重置成0会影响其他元素是不是在集合中的判断。对于关小黑屋再放出来这种需求,我们可以换一个思路,再加一个布隆过滤器————“被移除的元素”,当然现在公司都比较土豪,直接用redis存一个过期时间就可以,那就不在我们讨论之列了,布隆过滤器的初衷是用少许的误判来极大的节省空间。
错误率
假设 Hash 函数以等概率条件选择并设置 Bit Array 中的某一位,假定由每个 Hash 计算出需要设置的位(bit) 的位置是相互独立, m 是该位数组的大小,k 是 Hash 函数的个数.
- 位数组中某一特定的位在进行元素插入时的 Hash 操作中没有被置位的概率是:
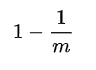
- 在所有 k 次 Hash 操作后该位都没有被置 "1" 的概率是:
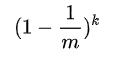
- 如果我们插入了 n 个元素,那么某一位仍然为 "0" 的概率是:
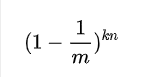
- 该位为 "1"的概率是:
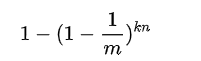
检测某一元素是否在该集合中。标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 "1",但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率由以下公式确定:
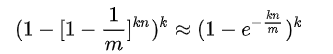
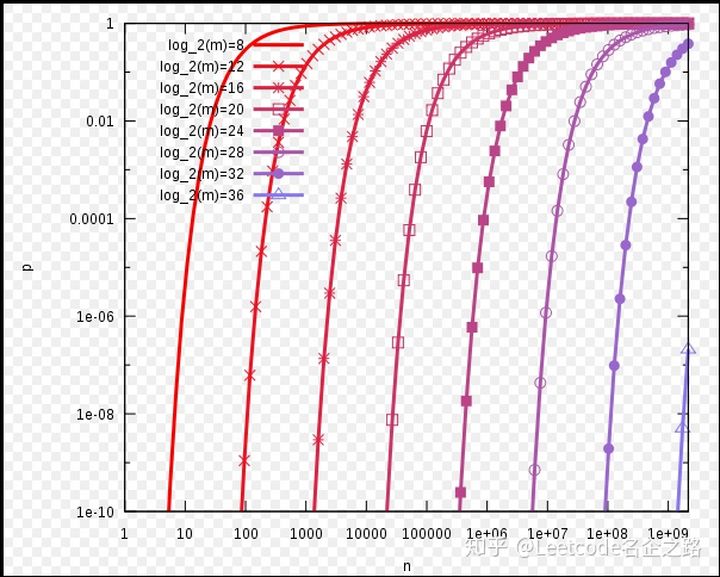
如何使得错误率最小,对于给定的m和n,当 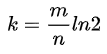 的时候取值最小。关系如下图所示:
的时候取值最小。关系如下图所示:
应用
- HBASE、Cassandra数据库中用来判断数据是不是在磁盘上
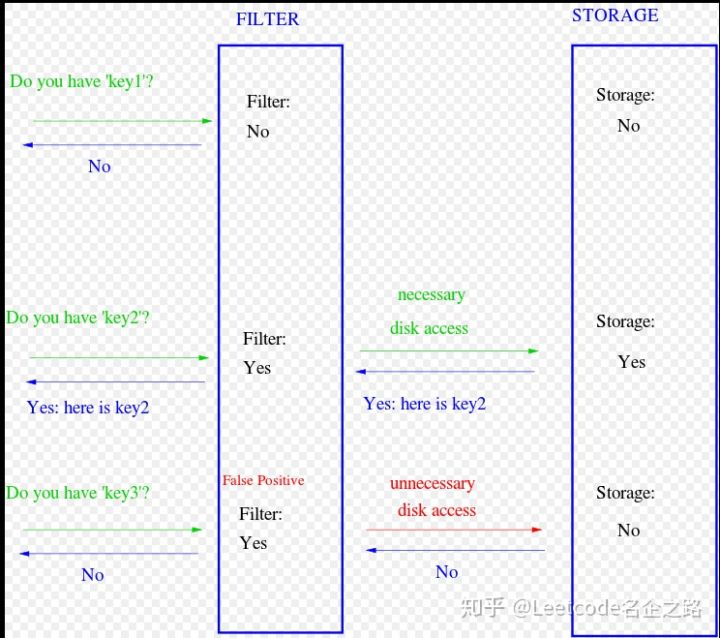
- chrome用它来做钓鱼网站监测
- 在比特币中用来判断是不是属于钱包
- 垃圾邮件监测
实现
如果你是java开发者,可以看看google的guava包中有对Bloom Filter的实现,详细见参考资料。
参考资料
- Bloom filter - Wikipedia
- 布隆过滤器:Google Guava类库源码分析及基于Redis Bitmaps的重构 - 文章 - 伯乐在线
- 布隆过滤器(Bloom Filter)、SPV和比特币