本文参考:布隆过滤器详解__瞳孔的博客-CSDN博客_布隆过滤器
布隆过滤器以及python实现_追光的鲲的博客-CSDN博客_python布隆过滤器
目录
一、概述
二、布隆过滤器原理
2.1 原理
2.2 误判率
2.3 特性
2.4 添加元素步骤
2.5 查询元素步骤
2.6 布隆过滤器的使用场景
三、布隆过滤器python示例
一、概述
它由很长的二进制向量和一系列(多个)hash函数组成,主要用于判断一个元素是否在一个集合中(存在一定的误差)。
hash函数可以调用包中的hash方法,通过不同的seed可以得到一系列的hash函数。通过hash值对向量长度取余数可以得到hash对应向量的位置信息。
通常要判断一个元素是否在某个集合中,一般是将集合中所有元素保存起来,然后通过比较确定,这种属于精准判断的方式。链表、树、哈希表等数据结构都是这种思路。但是随着集合中元素的增加,需要的存储空间也会呈现线性增长。
布隆过滤器不需要提前存储集合中的元素就能实现判断。
二、布隆过滤器原理
2.1 原理
布隆过滤器是由一个固定大小的二进制向量和一系列hash函数组成的。在初始状态下,对于长度为m的位数组,它的所有位都被置为0,如下图所示:

当有变量被加入集合时,通过K个hash函数将整个变量映射成向量中的k个点,把它们置为1。
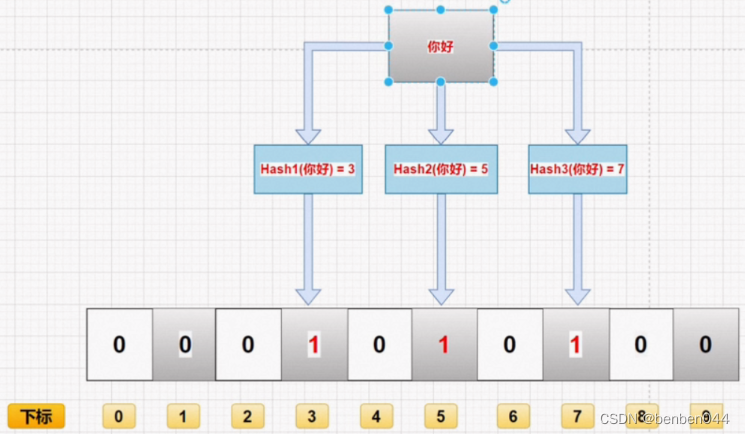
查询某个变量的时候,只要看这些点是不是都是1就可以大概率知道集合中有没有它了。
(1)如果这些点中出现了一个0,则被查询变量一定不在;
(2)如果都是1,则被查询变量很可能存在,而不是一定存在,因为hash函数会存在碰撞。
2.2 误判率
布隆过滤器的误判是指多个输入经过hash之后在相同的位置置为1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的bit位被多次映射且置为1。这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个bit并不是独占的,很有可能多个元素共享了某一位。如果直接删除了这一位的话,会影响其他的元素。
2.3 特性
(1)如果一个元素判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。
(2)布隆过滤器可以添加元素,但是不能删除元素,因为删除元素会导致误判率增加。
2.4 添加元素步骤
(1)将要添加的元素给K个哈希函数
(2)得到对应于位数组上的k个位置
(3)将这k个位置设为1
2.5 查询元素步骤
(1)将要查询的元素给k个哈希函数
(2)得到对应于位数组上的k个位置
(3)如果k个位置有一个为0,则肯定不在集合中
(4)如果k个位置全部为1,则可能在集合中。
2.6 布隆过滤器的使用场景
URL去重、垃圾邮件识别、大集合中重复元素的判断和缓存穿透等问题。
(1)数据库防止穿库。使用布隆过滤器来减少不存在的行或列的磁盘查找,避免代价高昂的磁盘查找会大大提高数据库查询操作的性能。
(2)业务场景中判断用户是否阅读过某视频或文章,比如抖音或头条,当然会导致一定的误判,但不会让用户看到重复的内容。
(3)缓存击穿场景。一般判断用户是否在缓存中,如果在则直接返回结果,不在则查询db,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应。这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查到则穿透到db。如果不在布隆器中,则直接返回。
三、布隆过滤器python示例
'''
布隆过滤器
n:数据规模
p:要求的误判率
二进制数据位数 m = -n*lnp/(ln2)^2
哈希函数个数 k=m/n*ln2
'''import math
import mmh3
from bitarray import bitarrayclass BloomFilter:def __init__(self, n=10000000, p=0.0000001):self.m = int(-n * math.log(p) / math.pow(math.log(2), 2)) # 需要的总bit位数self.k = int(self.m * math.log(2) / n) # 需要最少的hash次数self.mem = int(self.m / 8 / 1024 / 1024) # 需要多少m内存def add(self, value):raise Exception("未实现的方法")def is_exist(self, value):raise Exception("未实现的方法")def get_hashes(self, value):raise Exception("未实现的方法")class RAMBloomFilter(BloomFilter):# 内置100个随机种子SEEDS = [543, 460, 171, 876, 796, 607, 650, 81, 837, 545, 591, 946, 846, 521, 913, 636, 878, 735, 414, 372,344, 324, 223, 180, 327, 891, 798, 933, 493, 293, 836, 10, 6, 544, 924, 849, 438, 41, 862, 648, 338,465, 562, 693, 979, 52, 763, 103, 387, 374, 349, 94, 384, 680, 574, 480, 307, 580, 71, 535, 300, 53,481, 519, 644, 219, 686, 236, 424, 326, 244, 212, 909, 202, 951, 56, 812, 901, 926, 250, 507, 739, 371,63, 584, 154, 7, 284, 617, 332, 472, 140, 605, 262, 355, 526, 647, 923, 199, 518]def __init__(self, n=10000000, p=0.0000001):super().__init__(n, p)self.seeds = self.SEEDS[0 : self.k]self.bloom = bitarray(self.m)self.bloom.setall(0)def add(self, value):hashes = self.get_hashes(value)for index in hashes:self.bloom[index] = 1def is_exist(self, value):hashes = self.get_hashes(value)exist = Truefor index in hashes:exist = exist & self.bloom[index]return existdef get_hashes(self, value):hashes = []for seed in self.seeds:hash = mmh3.hash(value, seed)hashes.append(hash % self.m)return hashesramBloomFilter = RAMBloomFilter()
ramBloomFilter.add("university")
print(ramBloomFilter.is_exist("university"))
print(ramBloomFilter.is_exist("university2"))