Python爬虫下载QQ音乐网站歌曲
1.分析QQ音乐网站数据请求url

在QQ音乐搜索歌曲页面,通过浏览器调试工具,监测到向服务器发出的请求,获取到的json数据中list正好保存了对应于单页搜索结果的数据。查看请求header,得到url
https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=62072551069125820&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E7%97%B4%E5%BF%83%E6%8D%A2%E6%83%85%E6%B7%B1&g_tk=5381&jsonpCallback=searchCallbacksong2143&loginUin=0&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0
在这个url中其它参数可以暂不理会,关键之处在于“&w”这个参数,其后接的是是搜索歌曲名的UTF编码,如此我们便可以构建自己的url。
点击进入播放歌曲页面,继续打开调试工具分析,发现当前播放歌曲的url地址。

http://dl.stream.qqmusic.qq.com/C400004afGuZ2dqj8b.m4a?vkey=1DF82C55AACA1AB90AFC28540E545FF61B3BBC57E7CB196E251CC6F4CD76BAA6EF59478BA1147CBB3FB0CE1E7836415D9BB0C64F82F82E30&guid=2397748896&uin=0&fromtag=66
经过分析,发现这个url结构为http://dl.stream.qqmusic.qq.com/+[歌曲文件名]+.m4a?vkey=+[vkey]+&guid=2397748896&uin=0&fromtag=66
继续观察network请求,发现其中有个get请求会返回当前歌曲的文件名以及vkey字符串

再看看请求header

https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?g_tk=5381&jsonpCallback=MusicJsonCallback7574790907800089&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&cid=205361747&callback=MusicJsonCallback7574790907800089&uin=0&songmid=003ySAW93jISYE&filename=C400004afGuZ2dqj8b.m4a&guid=2397748896
在这个url中主要看两个参数:songmid和filename
这时再回头看看之前在搜索页得到的json数据
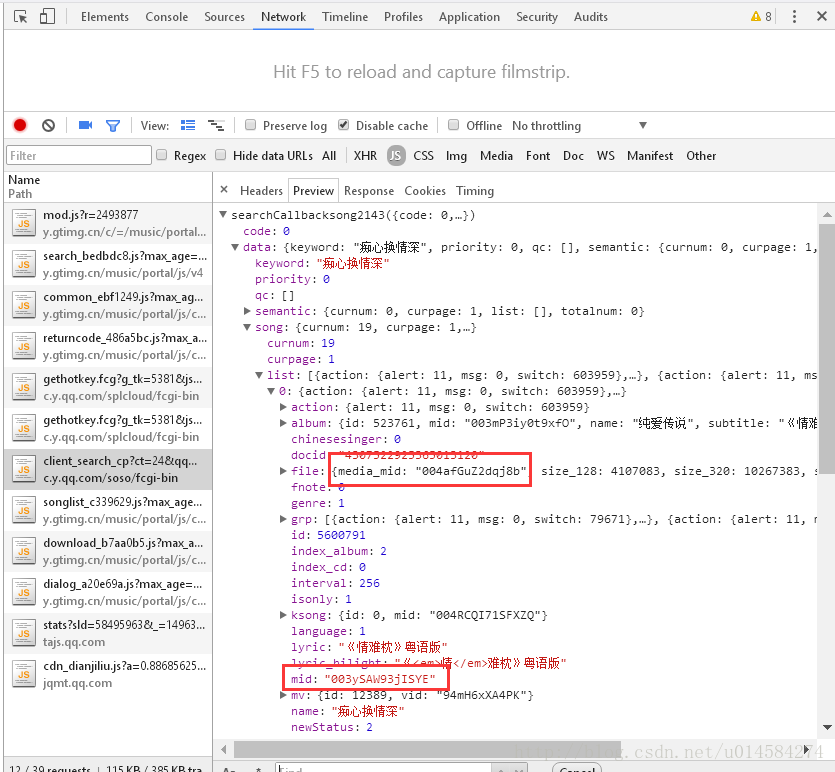
正好对应上边两个参数中的内容,如此我们便理清了思路,接下来就可以上代码了。
2.编写python代码
Crawler.py文件封装了一些爬虫函数
# -*- coding: utf-8 -*-
#Crawler.py
import urllib
import urllib2
import itertools
import urlparse
import datetime
import cookielib
import time
import reclass Crawler:htmls=[]cookies=cookielib.CookieJar()def download(self,url,headers={'User-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)'},num_retries=2):print 'Downloading:',url.decode('utf-8'),'\n'request=urllib2.Request(url,headers=headers)try:html=urllib2.urlopen(request).read()except urllib2.URLError as e:print 'Download error:',e.reason,'\n'html=Noneif num_retries > 0:if hasattr(e,'code') and 500 <= e.code < 600:return self.download(url,num_retries=num_retries-1)return htmldef crawl_sitemap(self,url,max_errors=5,delay=0):sitemap=self.download(url)links=re.findall('<loc>(.*?)</loc>',sitemap)mThrottle=Throttle(delay)for link in links:if delay > 0:mThrottle.wait(link)html=self.download(link)self.htmls.append(html)def link_crawler(self,seed_url,link_regex,max_depth=-1,delay=0):crawl_queue=[seed_url]seen={seed_url:0}mThrottle=Throttle(delay)while crawl_queue:url=crawl_queue.pop()depth=seen[url]if delay !=0:mThrottle.wait(url) if depth != max_depth:html=self.download(url)if html is None:continue for link in self.get_links(html):if re.match(link_regex,link):link=urlparse.urljoin(seed_url,link)if link not in seen:seen[link]=depth+1crawl_queue.append(link)def get_links(self,html):webpage_regex=re.compile('<a[^>]+href=["\'](.*?)["\']',re.IGNORECASE)return webpage_regex.findall(html)def ID_crawler(self,url,user_agent='wswp',max_errors=5,delay=0):num_errors=0mThrottle=Throttle(delay)for page in itertools.count(1):if delay > 0:mThrottle.wait(url % page)html=self.download(url % page,user_agent)if html is None:num_errors +=1if num_errors==max_errors:breakelse:num_errors=0self.htmls.append(html)def clear(self):del self.htmls[:]def dynamic_download(self,url,data={},type='POST',headers={'user_agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2717.400 QQBrowser/9.6.11133.400'}):print 'Downloading:',urldata=urllib.urlencode(data)opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookies))if type=='POST':request=urllib2.Request(url=url,headers=headers,data=data)else:url=url+'?'+datarequest=urllib2.Request(url=url,headers=headers)html=opener.open(request).read()return htmlclass Throttle:def __init__(self,delay):self.delay=delayself.domains={}def wait(self,url):domain=urlparse.urlparse(url).netloclast_accessed=self.domains.get(domain)if self.delay > 0 and last_accessed is not None:sleep_secs=self.delay-(datetime.datetime.now()-last_accessed).secondsif sleep_secs > 0:time.sleep(sleep_secs)self.domains[domain]=datetime.datetime.now()
MusicCrawler.py文件是实现上诉思路的主要文件
# -*- coding: utf-8 -*-
#MusicCrawler.py
import Crawler
import os
import re
import timeglobal mCount
global song_namemCount=0def write_file(data):global mCountif not os.path.exists("D:/%s/" % song_name.decode('utf-8')):os.mkdir('D:/%s/' % song_name.decode('utf-8'))if not data:returnwith open('D:/%s/%s.m4a' % (song_name.decode('utf-8'),str(mCount)),'wb') as code:code.write(data) def MusicJsonCallback(e):headers={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Cache-Control':'no-cache','Connection':'keep-alive','Host':'dl.stream.qqmusic.qq.com','Pragma':'no-cache','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2717.400 QQBrowser/9.6.11133.400'}url='http://dl.stream.qqmusic.qq.com/%s?vkey=%s&guid=3218858725&uin=0&fromtag=66' % (e['data']['items'][0]['filename'],e['data']['items'][0]['vkey'])data=mCrawler.download(url,headers=headers)write_file(data)def searchCallbacksong(e):headers={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Cache-Control':'no-cache','Connection':'keep-alive','Host':'dl.stream.qqmusic.qq.com','Pragma':'no-cache','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2717.400 QQBrowser/9.6.11133.400'}for index,item in enumerate(e['data']['song']['list']):global mCountmCount=mCount+1if item['type']==0:url='https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?g_tk=5381&jsonpCallback=MusicJsonCallback&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&cid=205361747&callback=MusicJsonCallback&uin=0&songmid=%s&filename=C400%s.m4a&guid=3218858725' % (item['ksong']['mid'] if item['language']==2 else item['mid'],item['file']['media_mid'])html=mCrawler.download(url,headers=headers)exec(html)elif item['type']==111:url=item['url']+'?fromtag=38'data=mCrawler.download(url,headers=headers)write_file(data)elif item['type']==112:url='http://dl.stream.qqmusic.qq.com/C1L0%s.m4a?fromtag=38' % item['file']['media_mid']data=mCrawler.download(url,headers=headers)write_file(data)mCrawler=Crawler.Crawler()song_name=raw_input(unicode('输入歌曲名:','utf-8').encode('gbk'))
song_name=unicode(song_name,'gbk').encode('utf-8')headers={'authority':'c.y.qq.com','method':'GET','path':'/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60916586359500801&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%s&g_tk=5381&jsonpCallback=searchCallbacksong&loginUin=0&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0' % song_name,'scheme':'https','accept':'*/*','accept-language':'zh-CN,zh;q=0.8','cache-control':'no-cache','pragma':'no-cache','referer':'https://y.qq.com/portal/search.html','user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2717.400 QQBrowser/9.6.11133.400'}
html=mCrawler.download('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=66640132791913660&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%s&g_tk=5381&jsonpCallback=searchCallbacksong&loginUin=0&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0' % song_name,headers=headers)
exec(html)3.注意事项
- 本文代码是基于python2.7版本
- url构建中有一些细节问题,在上边并未全部体现出,具体细节请看代码。
- 本人初学python,有不足之处请多包涵,谢谢。