主要运用了Python中的Requests包和json包获取内容,写入到Mongodb数据库并保存,pandas用于导出数据,代码详细我最后会给出github
接口分析并爬取歌单id
我发现html源码并没有我想要的数据,所以分析了Ajax请求,得到了我想要的数据。
在Chrome按F12(或Fn+F12)打开开发者工具,在Network中选择JS,并且刷新页面,找到关于歌单的渲染连接。
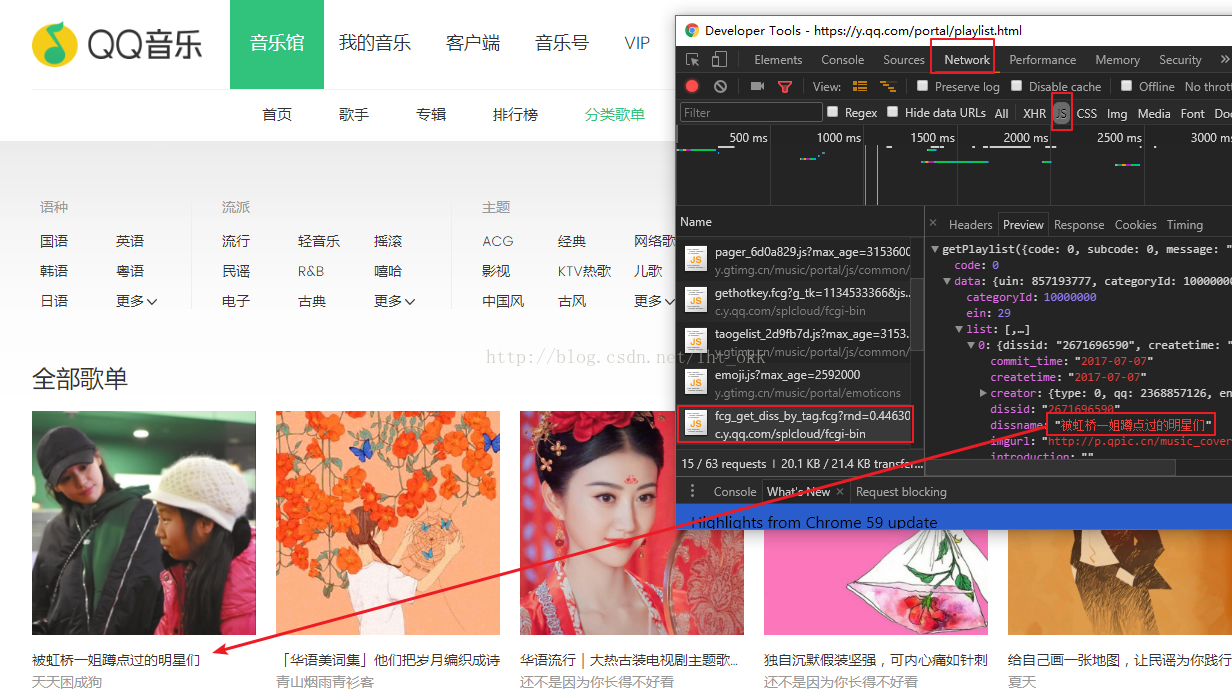
点击Headers获取链接https://c.y.qq.com/splcloud/fcgi-bin/fcg_get_diss_by_tag.fcg,注意参数和headers信息

#爬取歌单id
def getDissid(sin,ein):url = 'https://c.y.qq.com/splcloud/fcgi-bin/fcg_get_diss_by_tag.fcg'header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36','cookie':'RK=7dNm4/X+Yj; tvfe_boss_uuid=bf00ee54e9081ab4; pgv_pvi=8772238336; pac_uid=1_857193777; pgv_pvid=6457341280; o_cookie=80; ptcz=c761e59c8c8d6bd5198866d02a5cb7313af1af468006c455d6c2b5d26201d42e; pgv_si=s10759168; _qpsvr_localtk=0.08285763449905015; ptisp=ctc; luin=o0857193777; lskey=00010000228dd1371b945c68ecfd3b71d3071425024a7a8a2a23e3ffcb5b9904c9f7088d2ea8c01539ffed92; pt2gguin=o0857193777; uin=o0857193777; skey=@Kydi7w0EI; p_uin=o0857193777; p_skey=HjsE9sEjznJfXk*9KFEeW4VZr6i3*tlXZ2nuzEw8kCg_; pt4_token=c-p6sv3JEboA51cSQ3ABqxM8O80Jct3jYYkgy-aEQuE_; p_luin=o0857193777; p_lskey=000400008f9c296cd10c03a5173d22a184aad124d791568e90e4198beb8ad699a4d02fbfc059f71ab3d8758c; ts_last=y.qq.com/portal/playlist.html; ts_refer=ui.ptlogin2.qq.com/cgi-bin/login; ts_uid=3392060960','referer':'https://y.qq.com/portal/playlist.html'}paramter = {'g_tk':'1089387893','jsonpCallback':'getPlaylist','loginUin':'0','hostUin':'0','format':'jsonp','inCharset':'utf8','outCharset':'utf-8','notice':'0','platform':'yqq','needNewCode':'0','categoryId':'10000000','sortId':'5','sin':sin,#开始结点'ein':ein #结束结点,用于翻页}html = requests.get(url=url,params=paramter,headers=header)res = json.loads(html.text.lstrip('getPlaylist(').rstrip(')'))['data']['list']data = []if res != []:for t_item in res:item = {}ILLEGAL_CHARACTERS_RE = re.compile(r'[\000-\010]|[\013-\014]|[\016-\037]') #用于去掉非法字符item['createtime'] = t_item['createtime']item['creator_qq'] = t_item['creator']['qq']item['creator_name'] = t_item['creator']['name']item['creator_name'] = ILLEGAL_CHARACTERS_RE.sub(r'', item['creator_name'])item['creator_isVip'] = t_item['creator']['isVip']item['dissid'] = t_item['dissid'] #item['dissname'] = t_item['dissname']item['dissname'] = ILLEGAL_CHARACTERS_RE.sub(r'', item['dissname'])item['listennum'] = t_item['listennum']data.append(item)return data歌单接口分析并获取歌单信息和歌曲id,同样的获取方式,打开开发者工具
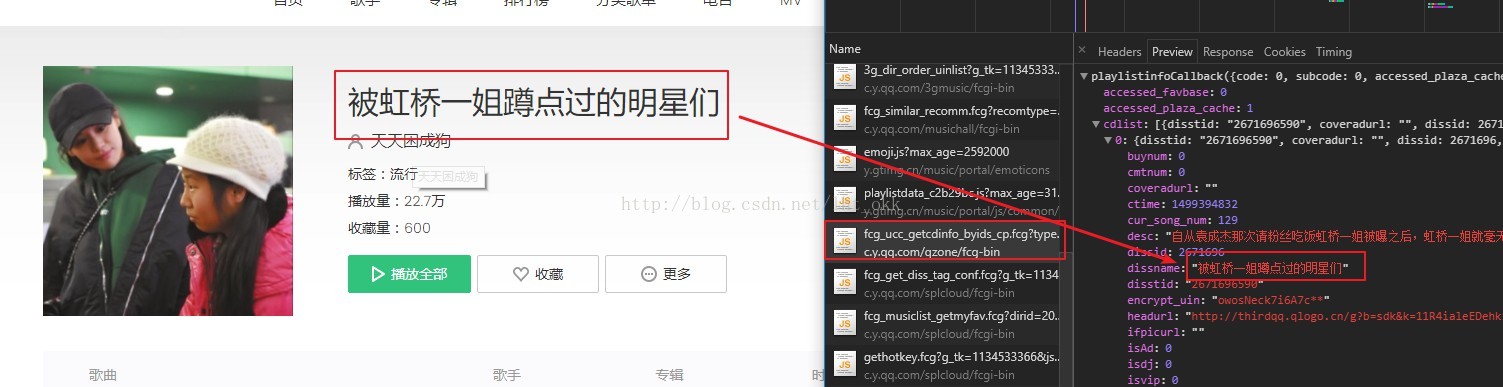
代码如下
#爬取歌曲id
def getSongid(dissid):url = 'https://c.y.qq.com/qzone/fcg-bin/fcg_ucc_getcdinfo_byids_cp.fcg'header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36','referer':'https://y.qq.com/n/yqq/playlist/{}.html'.format(dissid)}paramters = {'type':'1','json':'1','utf8':'1','onlysong':'0','disstid':dissid,'format':'jsonp','g_tk':'1089387893','jsonpCallback':'playlistinfoCallback','loginUin':'0','hostUin':'0','inCharset':'utf8','outCharset':'utf-8','notice':0,'platform':'yqq','needNewCode':0}html = requests.get(url=url,params=paramters,headers=header)cdlist = json.loads(html.text.lstrip('playlistinfoCallback(').rstrip(')'))['cdlist']if len(cdlist)>=1:cdlist = cdlist[0]data1 = {} #保存歌单信息数据data2 = [] #用于保存歌曲部分信息ILLEGAL_CHARACTERS_RE = re.compile(r'[\000-\010]|[\013-\014]|[\016-\037]')data1['desc'] = ILLEGAL_CHARACTERS_RE.sub(r'', cdlist['desc'])data1['dissid'] = dissiddata1['songids'] = cdlist['songids']data1['tags'] = ','.join([i['name'] for i in cdlist['tags']])tags = ','.join([i['name'] for i in cdlist['tags']])for item in cdlist['songlist']:tmp = {}tmp['albumname'] = item['albumname']tmp['songname'] = item['songname']tmp['singer'] = ','.join([i['name'] for i in item['singer']])tmp['tags'] = tagsif item.has_key('size128'):tmp['size128'] = item['size128']if item.has_key('songmid'):tmp['songmid'] = item['songmid']if item.has_key('songid'):tmp['songid'] = item['songid']data2.append(tmp)return [data1,data2]
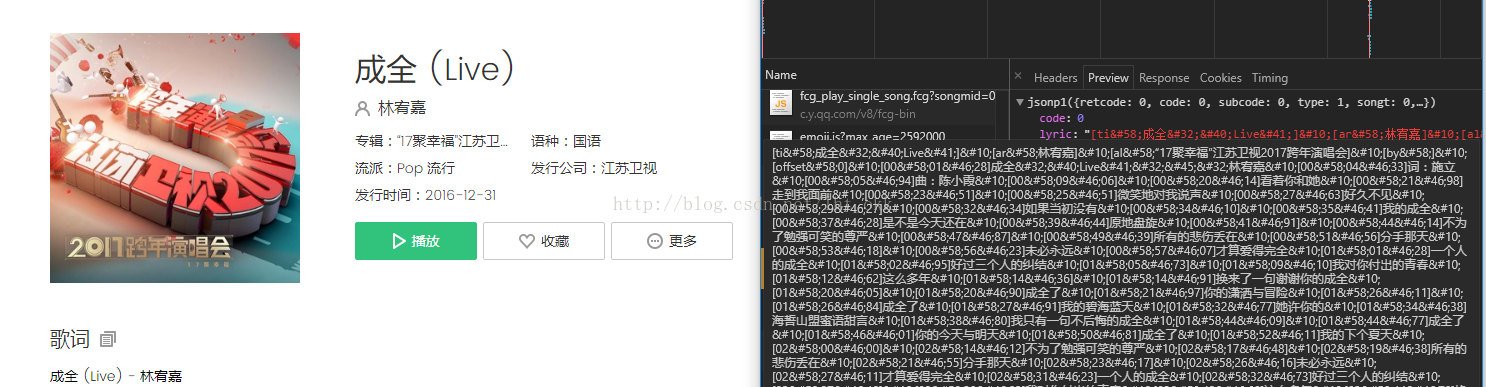
#获取歌词内容
def getLyric(musicid,songmid):url = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric.fcg'header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36','referer':'https://y.qq.com/n/yqq/song/{}.html'.format(songmid)}paramters = {'nobase64':1,'musicid':musicid, #传入之前获取到的id'callback':'jsonp1','g_tk':'1134533366','jsonpCallback':'jsonp1','loginUin':'0','hostUin':'0','format':'jsonp','inCharset':'utf8','outCharset':'utf-8','notice':'0','platform':'yqq','needNewCode':'0'}html = requests.get(url=url,params=paramters,headers=header)res = json.loads(html.text.lstrip('jsonp1(').rstrip(')'))#由于一部分歌曲是没有上传歌词,因此没有默认为空if res.has_key('lyric'):lyric = json.loads(html.text.lstrip('jsonp1(').rstrip(')'))['lyric']#对歌词内容做稍微清洗dr1 = re.compile(r'&#\d.;',re.S)dr2 = re.compile(r'\[\d+\]',re.S)dd = dr1.sub(r'',lyric)dd = dr2.sub(r'\n',dd).replace('\n\n','\n')return ddelse:return ""数据样式图


心得:
1.获取QQ音乐的接口链接其实不是很难,数据也是很明显就看到了。
2.一开始明明是请求成功,就是返回空数据,后来才发现原来是headers传少了referer参数,因为原先没有传入referer的习惯,忽略了。
3,.歌曲时长里面是没有具体数据的,只有文件大小,不过我想应该可以根据文件大小转化为时长,差个公式。
4.代码中用到了Mongo数据库,因为数据量有点多,不能保证一次性跑完并且中途不出差错,就没有用pandas.to_csv最后写入数据。
详细代码链接:https://github.com/lhtlht/qqmusic
写的不好,多多指正,谢谢!