目录
1.问题引出 :
2.单链表的出现:
2.1单链表的增添:
2.1.1:尾插
2.1.2:头插
2.1.3:任意插入
2.2:单链表的删除
2.2.1:尾删
2.2.2:头删
2.2.3:任意删除
2.3:链表节点的查找和修改
2.4:链表销毁
3.整体代码
1.问题引出 :
我们之前有谈及过顺序表这一数据结构,但它除了优势外也有明显的缺陷:
1.任意位置的插入和删除需要挪动大量元素。2.插入数据可能还需要扩增,造成空间浪费。
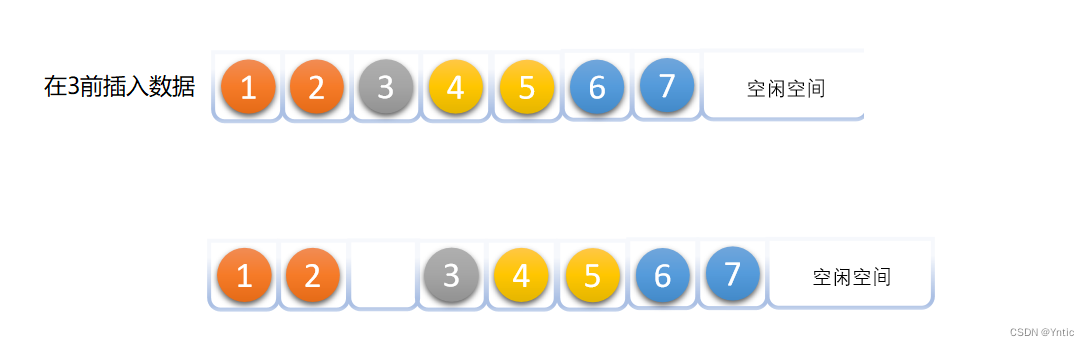
如图所示,我们在对顺序表的元素进行插入和删除时,由于顺序表是一段连续的空间,中间没有空隙,数据无法快速插入和删除。当顺序表空闲空间为0时还需要重新开辟空间,如果开辟后我们只需插入一个数据,就会造成空间不必要的浪费。那么怎么来解决以上的问题呢?
2.单链表的出现:
我们可以让所有的元素都不考虑其相邻位置,在内存中哪里有空就插入哪里,只需要保证每一个元素知道它下一个元素的位置即可——可以形成第一个元素知道第二个元素的位置(内存地址);第二个元素知道第三个元素的位置(内存地址)。这样不仅可以避免造成空间的不必要浪费,也可以通过一次遍历便找到需要插入或删除的元素位置——这便有了链表的概念。
那么什么是我们今天要谈及的单链表呢?
单链表定义:单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。链表中的数据是以结点来表示的,每个结点的构成:元素(存放的数据信息)+ 指针(指向下一个节点的地址),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
我们将单链表的一个元素称为节点,由定义可以看出,在单链表中我们要对节点存储两种元素:1.存储数据信息的数据域;2.存储后继节点地址的指针域。于是便有了我们对于单链表一个节点的代码定义:
typedef int SLTDateType;typedef struct SeqListNode
{SLTDateType x;//存储数据信息struct SeqListNode* next;//存储下一个节点地址
}SLT;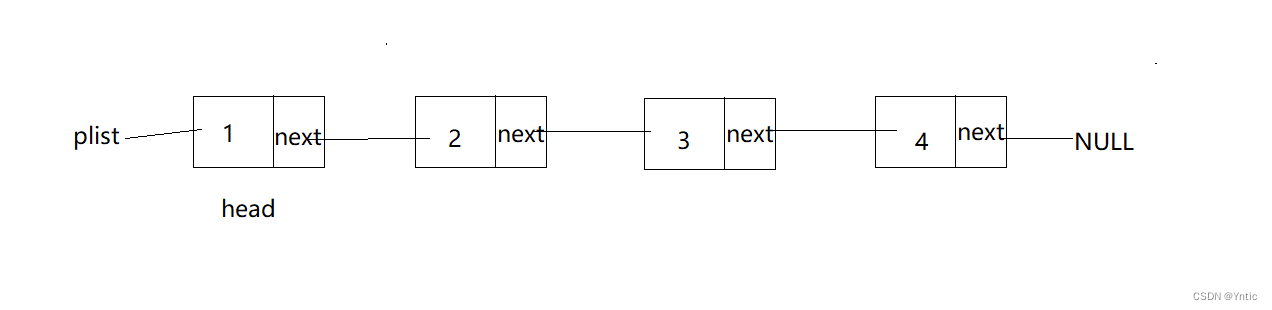
单链表的逻辑直观结构如上所示,我们习惯将链表中第一个节点的存储位置叫做头指针(必不可少),整个链表都得从头指针开始进行。之后的每一个节点就是前一个节点的后继next指向的位置,通常将最后一个节点next指针指向NULL。(文章中将第一个节点称为头节点)
2.1单链表的增添:
2.1.1:尾插
单链表和顺序表一样都是线性表。其中顺序表是线性表的顺序存储结构、单链表是线性表的链式存储结构。二者都可对数据进行增删查改的功能,我们来逐一实现。
SLT* plist = NULL;
我们先将链表制空,让链表只有一个头节点plist,从空开始对链表进行尾插操作:
void SLTPushBack(SLT* phead, SLTDateType x)
{SLT* newnode = (SLT*)malloc(sizeof(SLT));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->x = x;newnode->next = NULL;;if (phead== NULL){phead = newnode;}else{SLT* cur = phead;while (cur->next){cur = cur->next;}cur->next = newnode;}
}1.我们将头节点传入尾插函数。第一步自然是需要一个节点来进行尾插,链表前八行就是开辟节点并将x赋予给节点的数据域中。因为我们进行的是尾插,所以需要newnode的next指向NULL。这步很好理解
2.,在实际中我们不清楚链表是否为空(这里头节点为NULL,是空链表),所以要进行头指针判断,如果头指针指向空,我们将头指针指向newnode即可,如果不为空则遍历链表找寻单链表的尾节点(尾节点就是它next指向NULL的节点),当链表未指向尾节点我们将cur = cur->next这一步就相当于我们将第二个节点的地址给给cur,也就等价于链表向前移动由第一个节点变到第二个节点。然后找到后将newnode插入在尾节点之后。注意,我们一般对链表进行改变时候会将头节点拷贝给一个临时节点来对链表进行操作。可以在vs2019编译环境下对链表进行尾插观察:
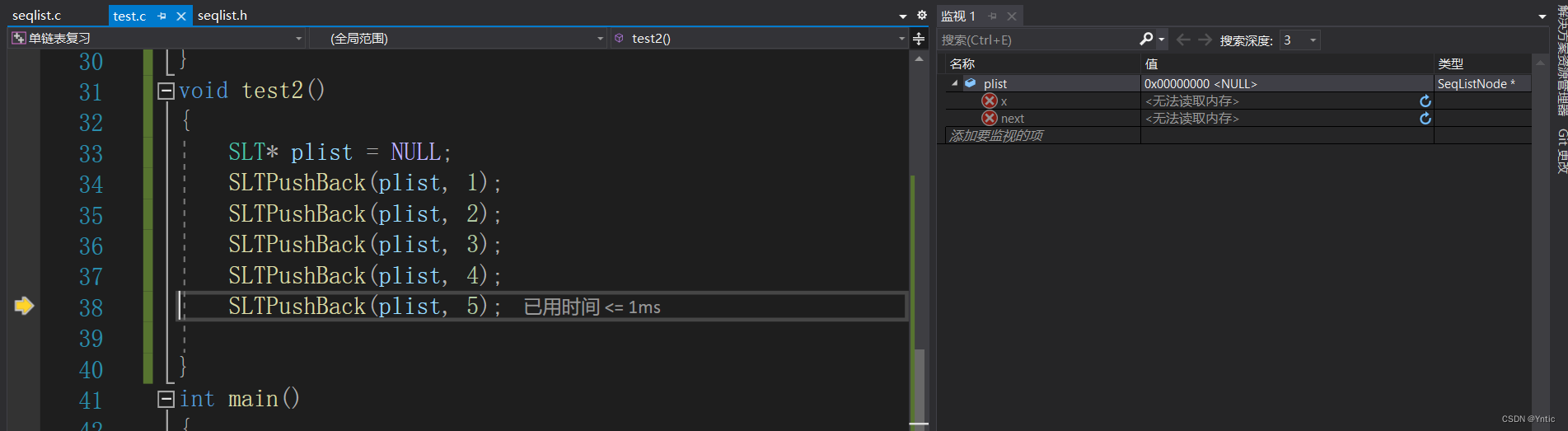
我们发现,当我们PushBack到5了,我们的plist依旧指向NULL,这是为什么呢?这里我们就涉及到了深层的指针知识,小编来带大家一一认识;在C语言中有如下情况:
情况1:
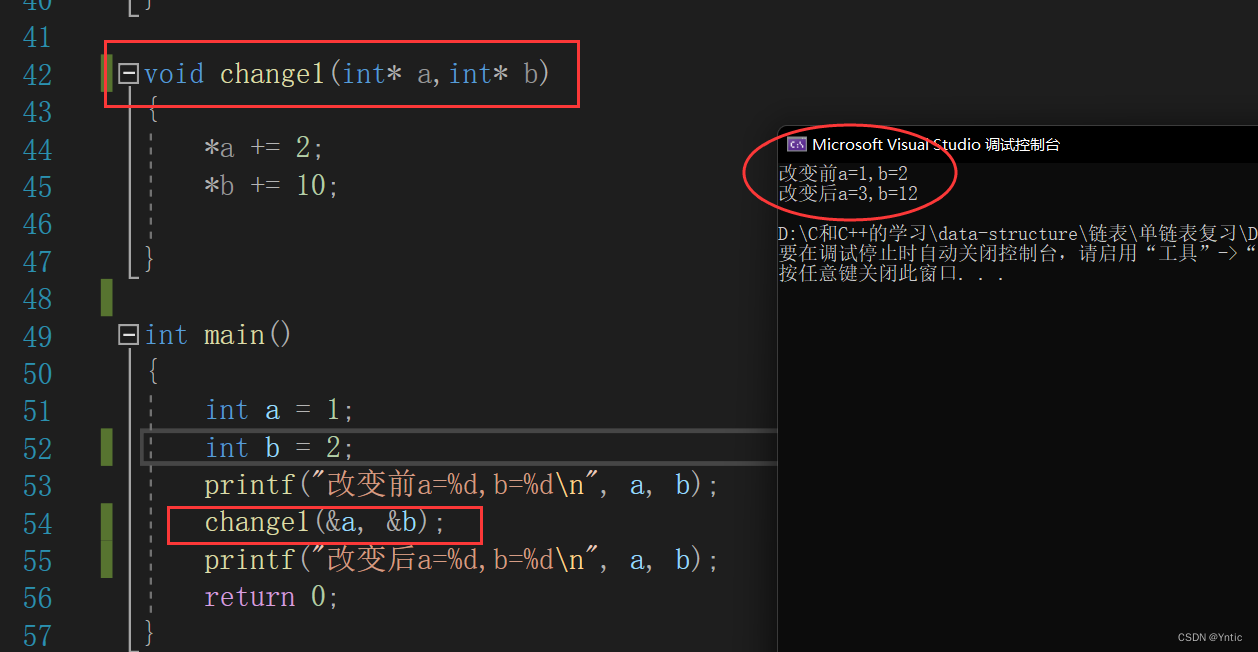
我们要想用函数改变int的变量,我们需要对函数进行传址调用,也就是用int*来接收a和b的地址,然后在解引用操作下的改变变量a和b(读者可以自行试试我们使用传值调用是否会改变a和b的值)。也就是说——在函数内改变int,要用int*
情况2:
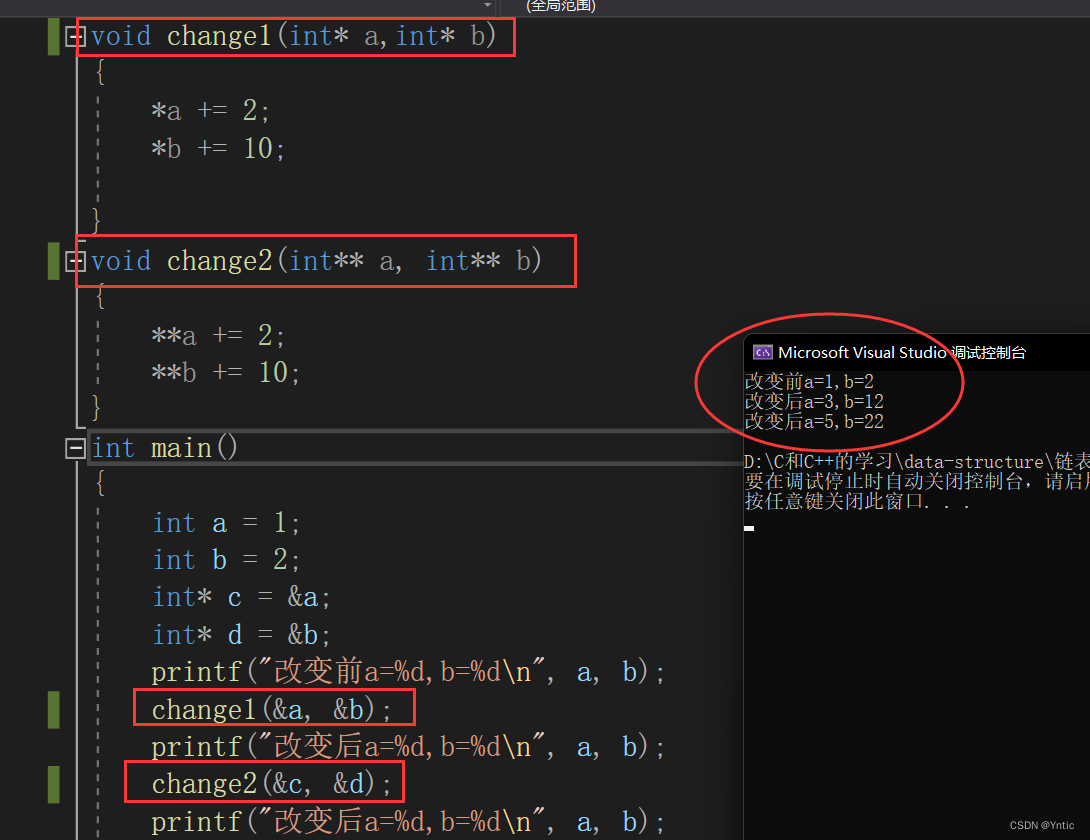
我们定义两个变量c和d,它们分别指向a的地址和b的地址,我们要用两个指针变量来改变原始a和b的值,我们就要传入c和d的地址,在change2中我们就要用二级指针来接受——即可以暂时理解为:在函数内部改变int*,要用int**
于是便可以引出我们单链表中的尾插样子了:

我们想要在SLTPushBcak函数内来改变我们的plist,我们就要传入plist的地址——即就是&plist,由于定义的头指针是一个指针,所以根据上面的“ 函数内部改变int*,要用int** ”可知我们在函数内部要改变SLT*要用SLT**;这里我们将形参改为“pphead”,改变如下:
SLT* plist = NULL;
SLTPushBack(&plist, 1);void SLTPushBack(SLT** pphead, SLTDateType x)
{assert(pphead);SLT* newnode = (SLT*)malloc(sizeof(SLT));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->x = x;newnode->next = NULL;if (*pphead == NULL) {*pphead = newnode;}else{SLT* cur = *pphead;while (cur->next){cur = cur->next;}cur->next = newnode;}
}这里做三点解释:
1.由于我们传入的是plist的地址,为了防止错误传参(可能穿空地址)我们用assert函数断言进行判断,若传入地址为空则报错,正常则进行下一步;
2.由于传入的是plist的地址,用的SLT**二级指针来接收,所以每一步给头指针plist链接时都要进行解引用。
3.在尾插函数内的第16行我们创建指针变量cur来复制*pphead即plist,这里为什么不用二级指针呢?道理也很简单,因为我们这时候只需要改变任意某个节点,而改变节点,我们用节点指针当然是可以的。整体实现效果如下:
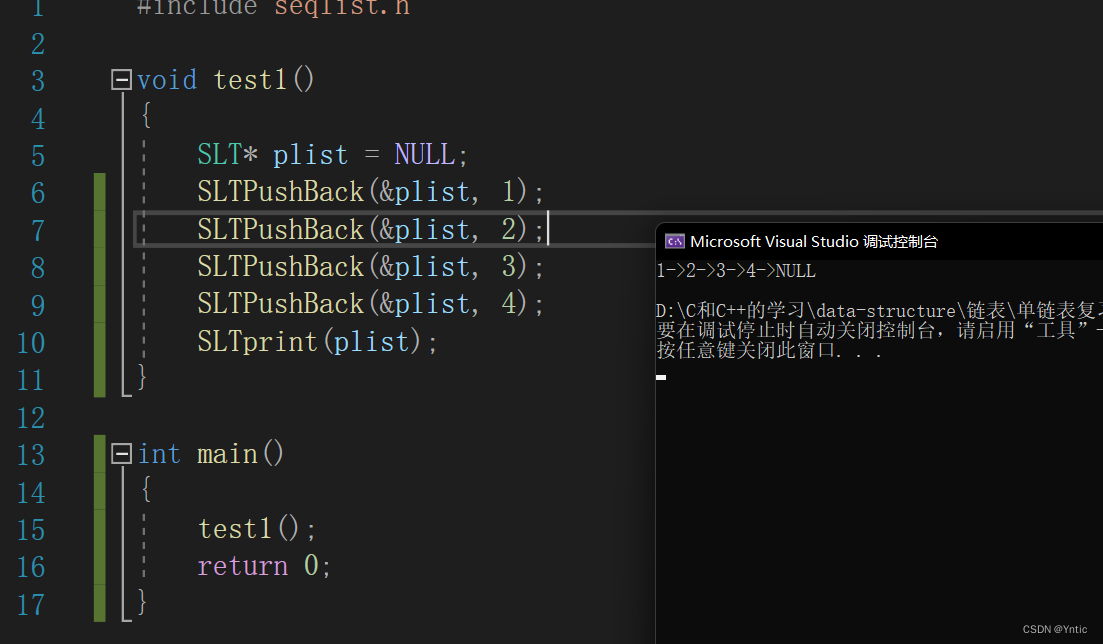
(这里是我简单实现的打印函数会附在后面的详细代码中)这边完成了我们的尾插函数。
2.1.2:头插
由于有头指针存在的缘故,自然也会有头部插入的函数,实现如下:
void SLTPushFront(SLT** pphead, SLTDateType x)
{assert(pphead);SLT* newnode = BuyNewNode(x);newnode->next = *pphead;*pphead = newnode;
}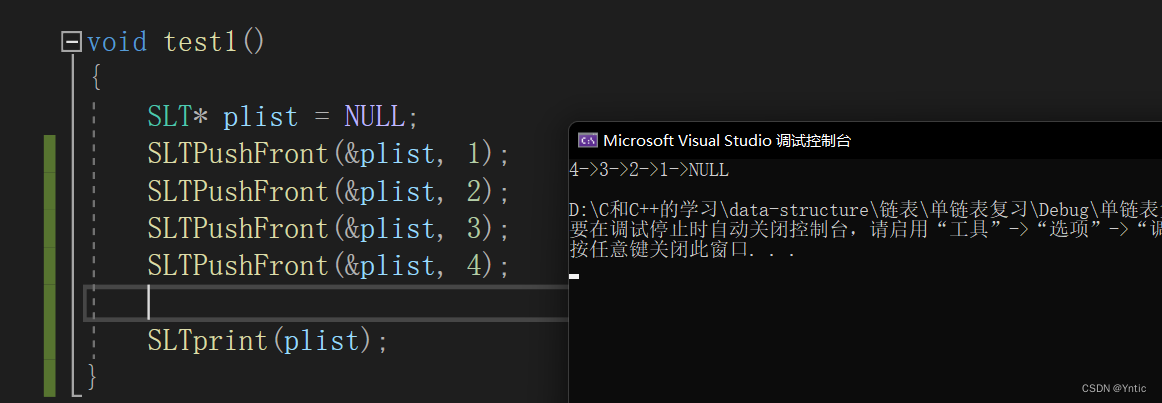
这里的**pphead便很好理解了,我们不多赘述,逻辑也很简单,无论头指针是否为空,只需要开辟一个新的节点(这里我们将开辟新节点的方法设置成一个BuyeNewNode函数来方便操作),只需要让新节点newnode指向plist,再把plist重新赋值给newnode作为头节点即可。
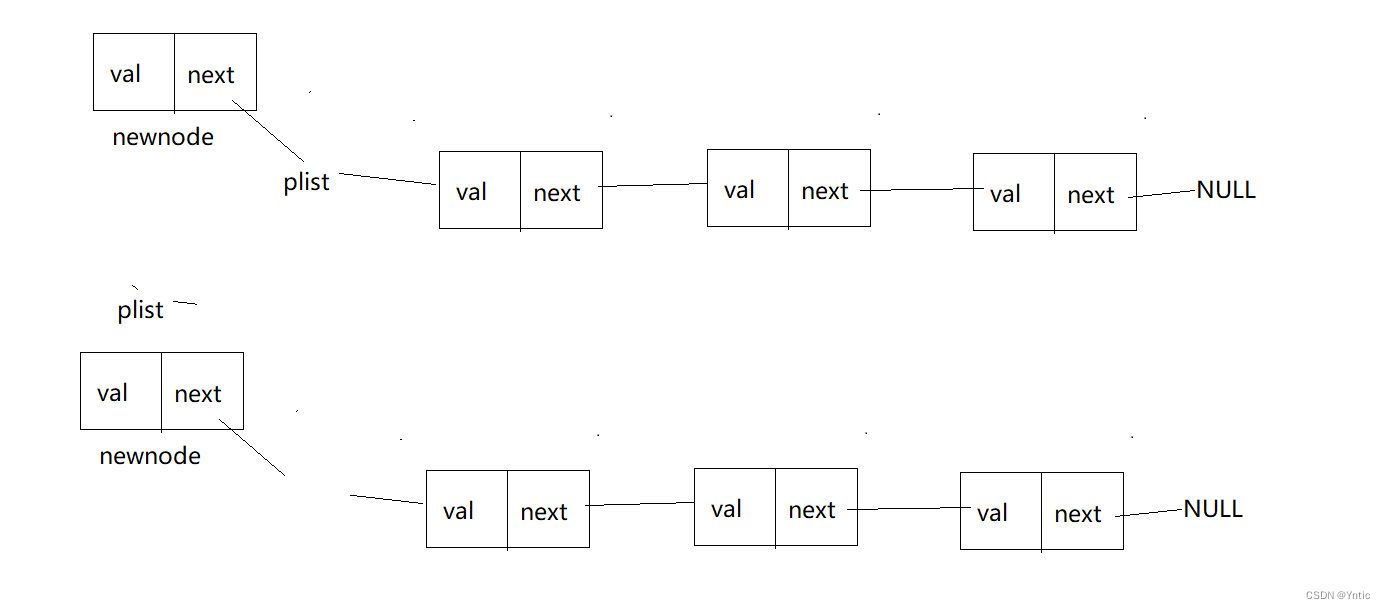
2.1.3:任意插入
那么头部尾部插入都有了,应该也有任意位置的插入吧?当然有的,实现如下:
void SLTInsertAfter(SLT* pos, SLTDateType x)
{assert(pos);SLT* newnode = BuyNewNode(x);newnode->next = pos->next;pos->next = newnode;
}我们在这里要求在pos之后插入节点,第一步断言一下pos是否为空,然后开辟新节点newnode,让newnode指向pos的下一个节点,然后pos指向newnode即可。这里不可以调换代码的最后两句,因为一旦调换第一句成了pos->next = newnode;我们进行下一步的时候无法找到pos的下一个节点,会链接失败,只需警惕这点即可。
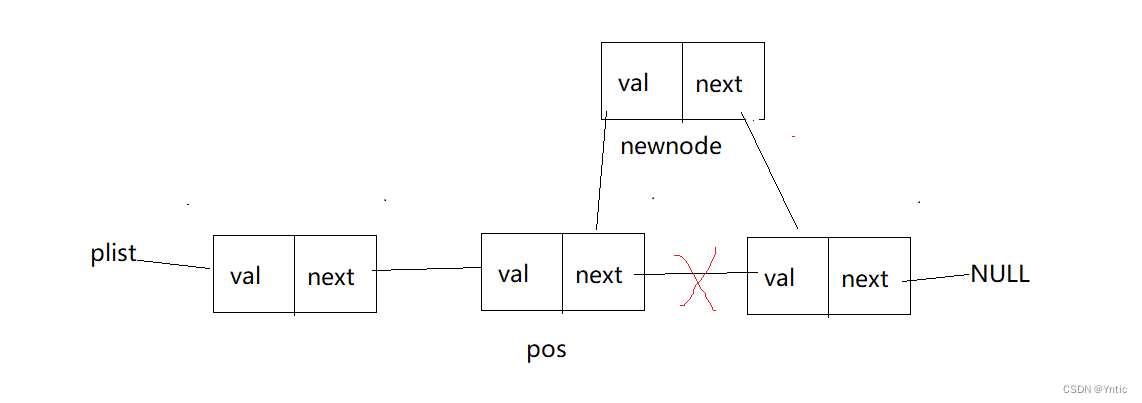
篇幅原因这里就不做代码运行结果展示了,我们来思考下一个问题:为什么不在pos节点之前位置插入呢?原因如下:
1.在pos位置之前插入需要传入头节点,如果没有头节点则不好操作。
2.在pos位置之前插入消耗大,需要从头遍历链表找到pos节点后pos前一节点来在中间进行插入。( 这和顺序表的任意位置插入时间复杂度一样都为O(n) )所以一般情况下我们都主要以实现在pos结点之后插入的操作。
2.2:单链表的删除
2.2.1:尾删
有了增插操作,自然少不了我们的删除操作,接下来我们一一介绍,首先尾删。
void SLTPopBack(SLT** pphead)
{assert(pphead);assert(*pphead);SLT* prev = NULL;SLT* tail = *pphead;if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{while (tail->next){prev = tail;tail = tail->next;}prev->next = NULL;free(tail);tail = NULL;}
}第一个断言的plist的地址不能为空,第二个断言的是plist不可以为空,因为链表为空不允许进行删除操作。我们在进行删除的时候先考虑普通情况,链表不为空,我们要找到尾部节点,然后删除即可,但是找到尾部节点时我们需要保存它的前一个节点,这样子才可以将倒数第二个节点的next指针滞空,如果只是简单的删除尾节点,会造成前一个结点next指针域的野指针访问。所以我们需要一个prev变量来保存tail节点的前一个节点。情况如下:

但当链表只有一个节点也就是*pphead == tail的时候,我们的prev为空,此时tail->next == NULL,不会进入循环,所以会导致prev空指针访问,也会造成错误。
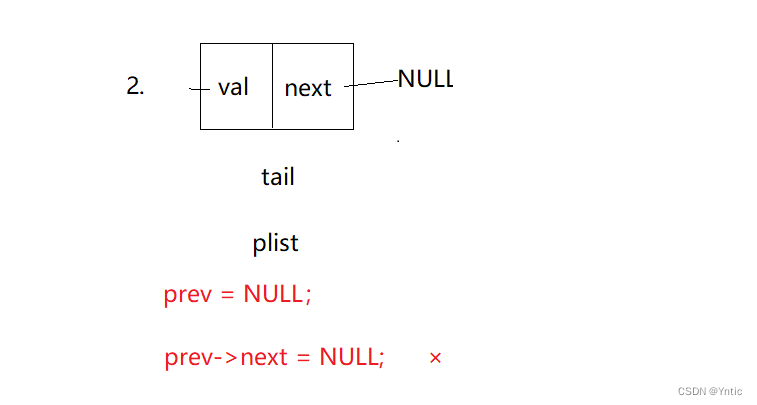
所以我们需要分开讨论这样的情况,也就实现了上面的代码。
实现效果如下:
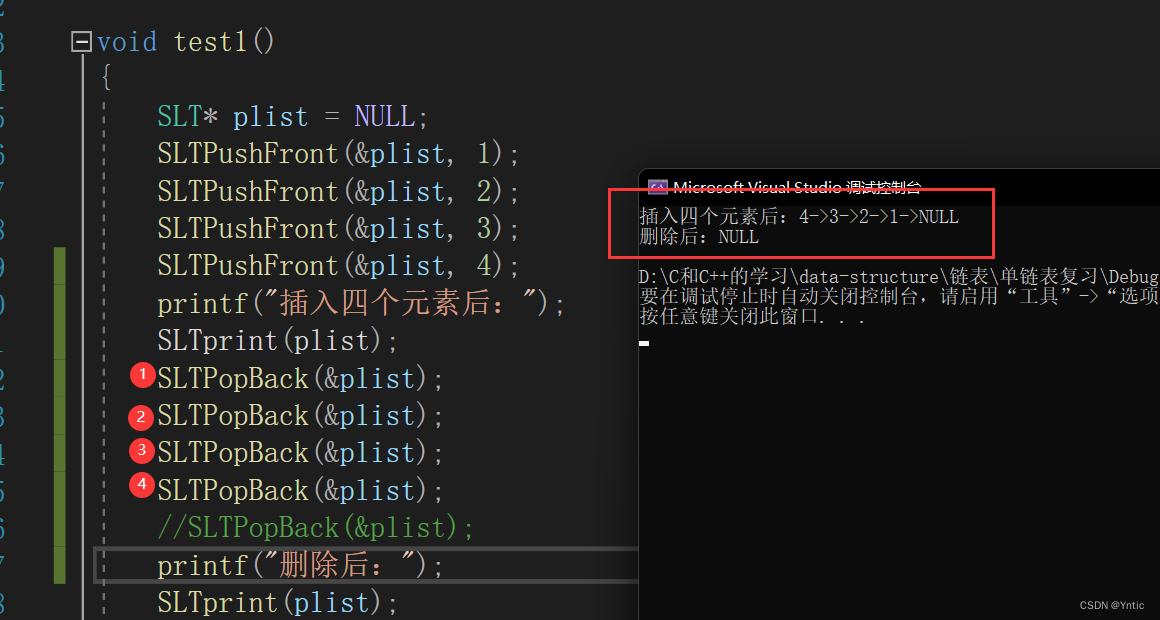
2.2.2:头删
这里我们对链表进行头部删除则会非常简单:
void SLTPopFront(SLT** pphead)
{assert(pphead);assert(*pphead);SLT* cur = (*pphead)->next;free(*pphead);*pphead = cur;
}还是一样,因为删除节点我们必须考虑链表为空不能删的情况,就需要两次断言判断。只需将头结点的下一个节点保存起来删掉原有的头节点,再将第二个节点重新命名为新的头节点即可。
2.2.3:任意删除
再来看看我们在pos节点之后的删除:
void SLTEraseAfter(SLT* pos)
{assert(pos);if (pos->next == NULL){return;}else{SLT* cur = pos->next;pos->next = cur->next;free(cur);}
}很显然,当pos的next指向NULL时表明pos是尾节点,所以不需要进行pos之后的删除,当不为尾节点时,我们保存pos的下下个节点,删除pos的下一个节点即可。这里就不多赘述了。
2.3:链表节点的查找和修改
对于数据来说,查找某一结点这一操作也极其重要,接下来我们简单实现一下。我们需要查找某一结点,所以函数设定为返回该节点,舍友返回值SLT,当我们需要找到x和数据域的量相同时返回该节点,没有则返回空。实现如下:
SLT* SListFind(SLT* phead, SLTDateType x)
{if (phead == NULL)return NULL;SLT* cur = phead;while (cur){if (cur->x == x){return cur;}cur = cur->next;}return NULL;
}
当我们找寻到该节点时,对它进行改变就很简单了,所以我们不需要实现修改节点的函数。可以轻松实现如下效果:
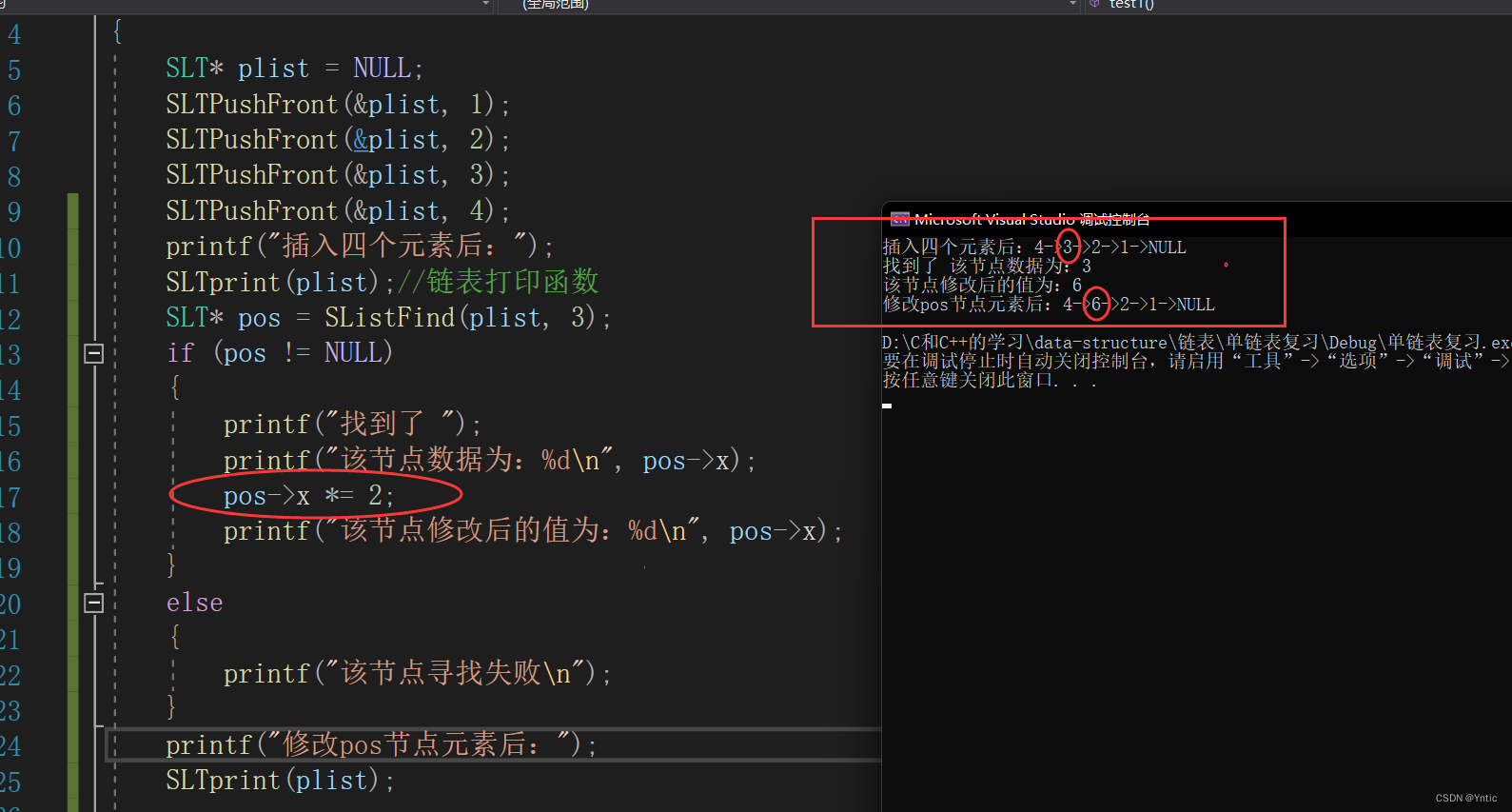
2.4:链表销毁
动态开辟的空间终归是要还给操作系统的,我们不能一直占用人家的空间,所以在我们每次开辟新节点对链表完成操作后自然要归还空间,于是便有如下函数:
void SLTDestroy(SLT** pphead)
{assert(pphead);assert(*pphead);SLT* cur = *pphead;SLT* prev = NULL;while (cur){prev = cur;cur = cur->next;free(prev);}*pphead = NULL;
}
我们保存两个节点:prev和cur,来遍历整个链表,由于每一个节点都是动态开辟,自然每一个节点都需要我们动手free掉,所以如上代码便形成,在free掉所有的节点后要将头指针制空。所以很简单就可以实现。
3.整体代码:
//创建一个节点
SLT* BuyNewNode(SLTDateType x)
{SLT* newnode = (SLT*)malloc(sizeof(SLT));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->x = x;newnode->next = NULL;
}//单链表打印
void SLTprint(SLT* plist)
{SLT* cur = plist;while (cur){printf("%d->", cur->x);cur = cur->next;}printf("NULL\n");
}//单链表尾插
void SLTPushBack(SLT** pphead, SLTDateType x)
{assert(pphead);SLT* newnode = BuyNewNode(x);if (*pphead == NULL){*pphead = newnode;}else{SLT* cur = *pphead;while (cur->next){cur = cur->next;}cur->next = newnode;}
}// 单链表的头插
void SLTPushFront(SLT** pphead, SLTDateType x)
{assert(pphead);SLT* newnode = BuyNewNode(x);newnode->next = *pphead;*pphead = newnode;
}// 单链表的尾删
void SLTPopBack(SLT** pphead)
{assert(pphead);assert(*pphead);SLT* prev = NULL;SLT* tail = *pphead;if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{while (tail->next){prev = tail;tail = tail->next;}prev->next = NULL;free(tail);tail = NULL;}
}// 单链表头删
void SLTPopFront(SLT** pphead)
{assert(pphead);assert(*pphead);SLT* cur = (*pphead)->next;free(*pphead);*pphead = cur;
}// 单链表查找
SLT* SListFind(SLT* phead, SLTDateType x)
{if (phead == NULL)return NULL;SLT* cur = phead;while (cur){if (cur->x == x){return cur;}cur = cur->next;}return NULL;
}// 单链表在pos位置之后插入x
void SLTInsertAfter(SLT* pos, SLTDateType x)
{assert(pos);SLT* newnode = BuyNewNode(x);newnode->next = pos->next;pos->next = newnode;
}// 单链表删除pos位置之后的值
void SLTEraseAfter(SLT* pos)
{assert(pos);if (pos->next == NULL){return;}else{SLT* cur = pos->next;pos->next = cur->next;free(cur);}
}// 单链表的销毁
void SLTDestroy(SLT** pphead)
{assert(pphead);assert(*pphead);SLT* cur = *pphead;SLT* prev = NULL;while (cur){prev = cur;cur = cur->next;free(prev);}*pphead = NULL;
}好啦,单链表知识就在这里介绍完咯,喜欢的话三连支持咯。