U-Net: Convolutional Networks for Biomedical Image Segmentation
原文地址:https://zhuanlan.zhihu.com/p/43927696
前言
U-Net是比较早的使用全卷积网络进行语义分割的算法之一,论文中使用包含压缩路径和扩展路径的对称U形结构在当时非常具有创新性,且一定程度上影响了后面若干个分割网络的设计,该网络的名字也是取自其U形形状。
U-Net的实验是一个比较简单的ISBI cell tracking数据集,由于本身的任务比较简单,U-Net紧紧通过30张图片并辅以数据扩充策略便达到非常低的错误率,拿了当届比赛的冠军。
论文源码已开源,可惜是基于MATLAB的Caffe版本。虽然已有各种开源工具的实现版本的U-Net算法陆续开源,但是它们绝大多数都刻意回避了U-Net论文中的细节,虽然这些细节现在看起来已无关紧要甚至已被淘汰,但是为了充分理解这个算法,笔者还是建议去阅读作者的源码,地址如下:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
1. 算法详解
1.1 U-Net的网络结构
直入主题,U-Net的U形结构如图1所示。网络是一个经典的全卷积网络(即网络中没有全连接操作)。网络的输入是一张 的边缘经过镜像操作的图片(input image tile),关于“镜像操作“会在1.2节进行详细分析,网络的左侧(红色虚线)是由卷积和Max Pooling构成的一系列降采样操作,论文中将这一部分叫做压缩路径(contracting path)。压缩路径由4个block组成,每个block使用了3个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2,因此有了图中所示的Feature Map尺寸变化。最终得到了尺寸为
的Feature Map。
网络的右侧部分(绿色虚线)在论文中叫做扩展路径(expansive path)。同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即图1中左侧虚线部分)。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的Feature Map的尺寸是 。由于该任务是一个二分类任务,所以网络有两个输出Feature Map。
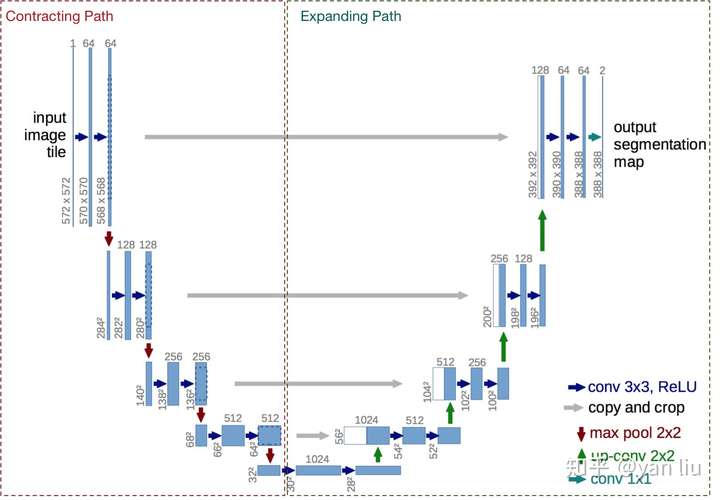
图1:U-Net网络结构图
如图1中所示,网络的输入图片的尺寸是 ,而输出Feature Map的尺寸是
,这两个图像的大小是不同的,无法直接计算损失函数,那么U-Net是怎么操作的呢?
1.2 U-Net究竟输入了什么
首先,数据集我们的原始图像的尺寸都是 的。为了能更好的处理图像的边界像素,U-Net使用了镜像操作(Overlay-tile Strategy)来解决该问题。镜像操作即是给输入图像加入一个对称的边(图2),那么边的宽度是多少呢?一个比较好的策略是通过感受野确定。因为有效卷积是会降低Feature Map分辨率的,但是我们希望
的图像的边界点能够保留到最后一层Feature Map。所以我们需要通过加边的操作增加图像的分辨率,增加的尺寸即是感受野的大小,也就是说每条边界增加感受野的一半作为镜像边。
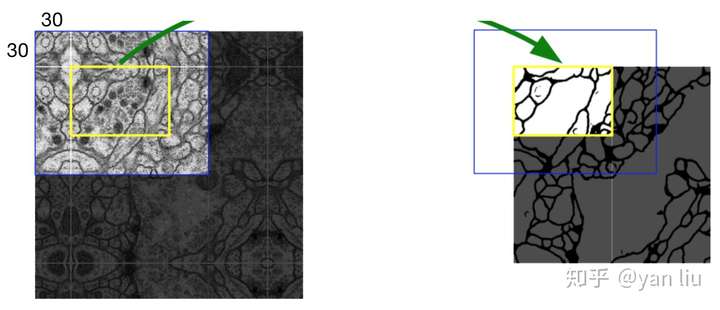
图2:U-Net镜像操作
根据图1中所示的压缩路径的网络架构,我们可以计算其感受野:
这也就是为什么U-Net的输入数据是 的。572的卷积的另外一个好处是每次降采样操作的Feature Map的尺寸都是偶数,这个值也是和网络结构密切相关的。
1.3 U-Net的损失函数
ISBI数据集的一个非常严峻的挑战是紧密相邻的物体之间的分割问题。如图3所示,(a)是输入数据,(b)是Ground Truth,(c)是基于Ground Truth生成的分割掩码,(d)是U-Net使用的用于分离边界的损失权值。
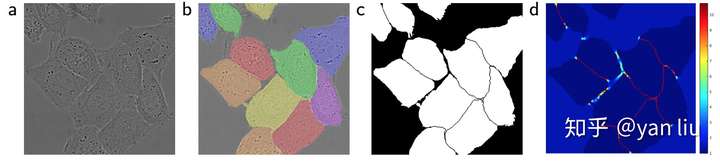
图3:ISBI数据集样本示例
那么该怎样设计损失函数来让模型有分离边界的能力呢?U-Net使用的是带边界权值的损失函数:
其中 是$$softmax$$损失函数,
是像素点的标签值,
是像素点的权值,目的是为了给图像中贴近边界点的像素更高的权值。
其中 是平衡类别比例的权值,
是像素点到距离其最近的细胞的距离,
则是像素点到距离其第二近的细胞的距离。
和
是常数值,在实验中
,
。
2. 数据扩充
由于训练集只有30张训练样本,作者使用了数据扩充的方法增加了样本数量。并且作者指出任意的弹性形变对训练非常有帮助。
3. 总结
U-Net是比较早的使用多尺度特征进行语义分割任务的算法之一,其U形结构也启发了后面很多算法。但其也有几个缺点:
- 有效卷积增加了模型设计的难度和普适性;目前很多算法直接采用了same卷积,这样也可以免去Feature Map合并之前的裁边操作
- 其通过裁边的形式和Feature Map并不是对称的,个人感觉采用双线性插值的效果应该会更好。
Reference
[1] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.